
在金融领域使用 R 进行预测建模
图片来自:Editor | Ideogram
金融领域的预测建模使用历史数据来预测未来趋势和结果。R 是一种强大的统计编程语言,为金融分析和建模提供了强大的工具和库。本文探讨了 R 中常用于金融预测建模的关键技术和软件包。我们将涵盖时间序列分析、回归、机器学习和投资组合优化,以及使用 R 构建基本预测模型的逐步指南。
为什么在金融领域使用 R?
R 在金融领域广受欢迎,原因有很多
- 强大的库:R 提供了广泛的统计和建模软件包。其中包括 forecast、caret 和 quantmod。
- 数据处理:R 在高效管理和分析大型数据集方面表现出色。其数据处理包使其易于处理复杂的金融数据。
- 可视化:R 使用 ggplot2 和 plotly 等软件包创建复杂的视觉效果。这些可视化有助于理解金融趋势并有效传达见解。
- 社区支持:R 受益于不断为其发展做出贡献的强大社区。广泛的支持包括教程和资源。
关键技术
1. 时间序列分析
时间序列分析用于根据历史数据预测金融趋势。关键模型包括
- ARIMA 模型:自回归积分移动平均(ARIMA)模型广泛用于预测。它们利用过去的观测值来预测未来的值。auto.arima() 函数会根据您的数据自动选择最佳 ARIMA 模型。
- 指数平滑:该技术通过平滑历史数据来做出预测。forecast 包中的 ets() 函数应用各种指数平滑方法来生成预测。
|
1 2 3 4 |
library(forecast) data <- ts(financial_data, frequency = 12) fit <- auto.arima(data) forecast(fit, h = 12) |
2. 回归分析
回归分析有助于理解变量之间的关系。它使您能够根据预测变量来预测结果。
|
1 |
model <- lm(return ~ factors, data = financial_data) |
3. 机器学习
机器学习通过从数据中学习来提高预测精度。使用 caret 包
- 训练模型:使用 train() 函数来实现机器学习算法,例如随机森林和支持向量机。这有助于构建强大的预测模型。
- 交叉验证:trainControl() 函数用于设置交叉验证程序,以评估不同模型的性能并避免过拟合。
|
1 2 3 |
library(caret) train_control <- trainControl(method="cv", number=10) model <- train(target ~ ., data = financial_data, method = "rf", trControl = train_control) |
4. 投资组合优化
投资组合优化旨在以最小化风险的方式实现最佳回报。R 中用于投资组合优化的关键工具包括
- Quantmod:此软件包有助于导入和分析股票价格数据。它提供了用于检索金融数据和计算移动平均线等指标的函数。
- PerformanceAnalytics:使用此软件包来评估投资组合绩效并计算风险指标,例如风险价值 (VaR) 和条件风险价值 (CVaR)。
|
1 2 3 4 |
library(quantmod) library(PerformanceAnalytics) returns <- na.omit(Return.calculate(prices)) VaR(returns, p = 0.95, method = "historical") |
逐步指南
本指南提供了一种在 R 中为金融数据构建和评估预测模型的实用方法。
1. 加载必要的库
首先加载数据处理和可视化库。重要的软件包包括用于创建绘图的 ggplot2 和用于数据整理的 dplyr。
|
1 2 3 |
# 加载必要的库 library(ggplot2) # 用于可视化 library(dplyr) # 用于数据处理 |
2. 模拟金融数据
生成用于测试目的的合成金融数据。使用 cumsum() 模拟收入和支出等累计金融指标。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 模拟一些金融数据 set.seed(123) n <- 100 # 观测值数量 data <- data.frame( Date = seq.Date(from = as.Date("2020-01-01"), by = "month", length.out = n), Revenue = cumsum(rnorm(n, mean = 100, sd = 10)), # 随机正态值的累积和 Expense = cumsum(rnorm(n, mean = 50, sd = 5)) # 随机正态值的累积和 ) # 查看模拟数据的几行 head(data) |

3. 准备数据
执行特征工程并将数据拆分为训练集和测试集。创建滞后特征以捕获过去的预测值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 特征工程:创建用于预测的滞后特征 data <- data %>% arrange(Date) %>% mutate(Lag1_Revenue = lag(Revenue, 1), Lag2_Revenue = lag(Revenue, 2), Lag1_Expense = lag(Expense, 1), Lag2_Expense = lag(Expense, 2)) %>% na.omit() # 删除包含 NA 值的行 # 将数据拆分为训练集和测试集 set.seed(123) train_index <- sample(seq_len(nrow(data)), size = 0.8 * nrow(data)) train_data <- data[train_index, ] test_data <- data[-train_index, ] |
4. 训练模型
使用训练数据拟合线性回归模型,以根据滞后特征预测财务指标。
|
1 2 |
# 训练线性回归模型 model <- lm(Revenue ~ Lag1_Revenue + Lag2_Revenue + Lag1_Expense + Lag2_Expense, data = train_data) |
5. 进行预测
使用训练好的模型在测试集上生成预测。此步骤有助于评估模型的性能。
|
1 2 |
# 模型预测 predictions <- predict(model, newdata = test_data) |
6. 评估模型
通过将预测值与实际值进行比较来评估预测的准确性。计算均方根误差 (RMSE) 来衡量模型性能。
|
1 2 3 4 |
# 模型评估 results <- data.frame(Actual = test_data$Revenue, Predicted = predictions) rmse <- sqrt(mean((results$Actual - results$Predicted)^2)) cat("均方根误差 (RMSE):", rmse, "\n") |

对于价格在 10,000 左右的情况下,RMSE 值为 8 表示模型误差非常小。
7. 可视化结果
使用 ggplot2 创建实际值与预测值散点图。
|
1 2 3 4 5 6 7 8 |
# 可视化 ggplot(results, aes(x = Actual, y = Predicted)) + geom_point() + geom_abline(intercept = 0, slope = 1, color = "red") + labs(title = "实际收入与预测收入", x = "实际收入", y = "预测收入") + theme_minimal() |
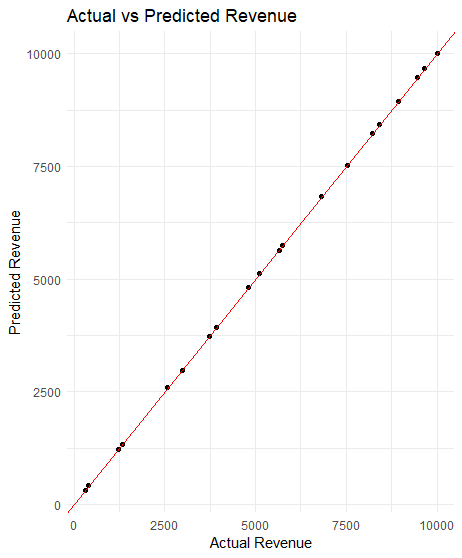
可视化显示模型拟合良好且性能准确。
实际应用
- 股票价格预测:根据历史数据预测未来价格。这有助于投资者决定何时买卖股票。
- 信用风险建模:预测贷款违约的可能性。分析过去的借款人行为和财务数据,以预测某人是否可能错过付款。
- 算法交易:使用数据分析开发交易策略。这些程序使用算法来分析市场趋势并自动执行交易。
总结
R 提供了金融预测建模的生态系统,具有用于时间序列分析、回归、机器学习和投资组合优化的专用库。该语言的数据处理功能和可视化工具使分析师能够处理复杂的金融数据并有效传达见解。通过利用 R 的预测建模能力,金融专业人士可以做出数据驱动的决策,并基于严格的统计分析制定策略。
在R中发现更快的机器学习!

在几分钟内开发您自己的模型
...只需几行R代码
在我的新电子书中探索如何实现
精通 R 语言机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到您自己的项目中
跳过学术理论。只看结果。





暂无评论。