绘制单个决策树可以深入了解给定数据集的梯度提升过程。
在本教程中,您将发现如何使用Python中的XGBoost绘制已训练梯度提升模型中的单个决策树。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。

如何在 Python 中使用 XGBoost 可视化梯度提升决策树
照片由Kaarina Dillabough提供,部分权利保留。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
绘制单个XGBoost决策树
XGBoost Python API提供了一个用于绘制已训练XGBoost模型中决策树的函数。
此功能在**plot_tree()**函数中提供,该函数将已训练模型作为第一个参数,例如:
|
1 |
plot_tree(model) |
这将绘制模型中的第一棵树(索引为0的树)。此图可以使用**matplotlib**和**pyplot.show()**保存到文件或显示在屏幕上。
此绘图功能要求您已安装graphviz库。
我们可以在Pima Indians糖尿病发病数据集上创建一个XGBoost模型,并绘制模型中的第一棵树。
下载数据集并将其放置在您的当前工作目录中。
完整的代码清单如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 绘制决策树 从 numpy 导入 loadtxt from xgboost import XGBClassifier from xgboost import plot_tree import matplotlib.pyplot as plt # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] y = dataset[:,8] # 拟合模型,无训练数据 model = XGBClassifier() model.fit(X, y) # 绘制单棵树 plot_tree(model) plt.show() |
运行代码将绘制模型中的第一棵决策树(索引0),显示每个分裂的特征和特征值以及输出的叶节点。
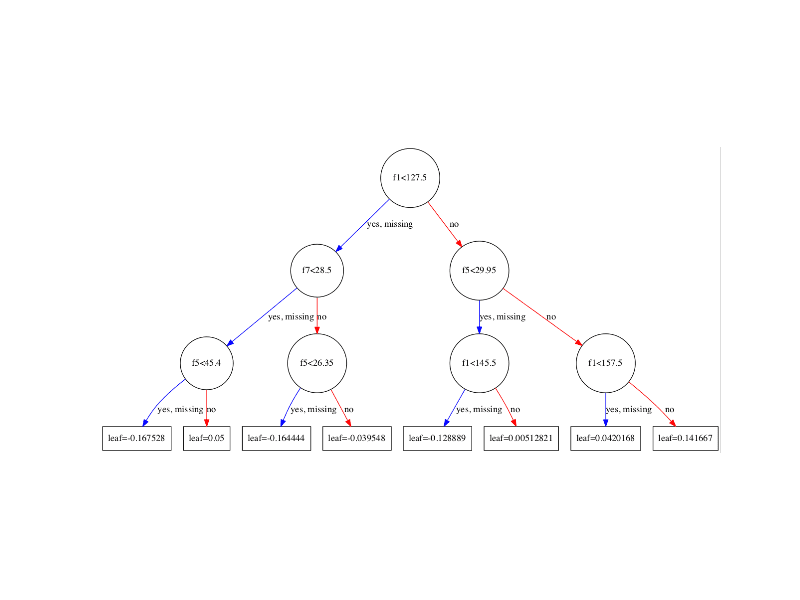
单个决策树的XGBoost图
您可以看到变量会自动命名为f1和f5,对应于输入数组中的特征索引。
您可以看到每个节点内的分裂决策,以及左右分裂的不同颜色(蓝色和红色)。
**plot_tree()**函数接受一些参数。您可以通过为**num_trees**参数指定索引来绘制特定的图。例如,您可以如下绘制序列中的第5棵提升树:
|
1 |
plot_tree(model, num_trees=4) |
您还可以通过将**rankdir**参数更改为“LR”(从左到右)而不是默认的从上到下(UT)来更改图的布局,使其从左到右(更易于阅读)。例如:
|
1 |
plot_tree(model, num_trees=0, rankdir='LR') |
下面显示了以从左到右布局绘制的树的结果。
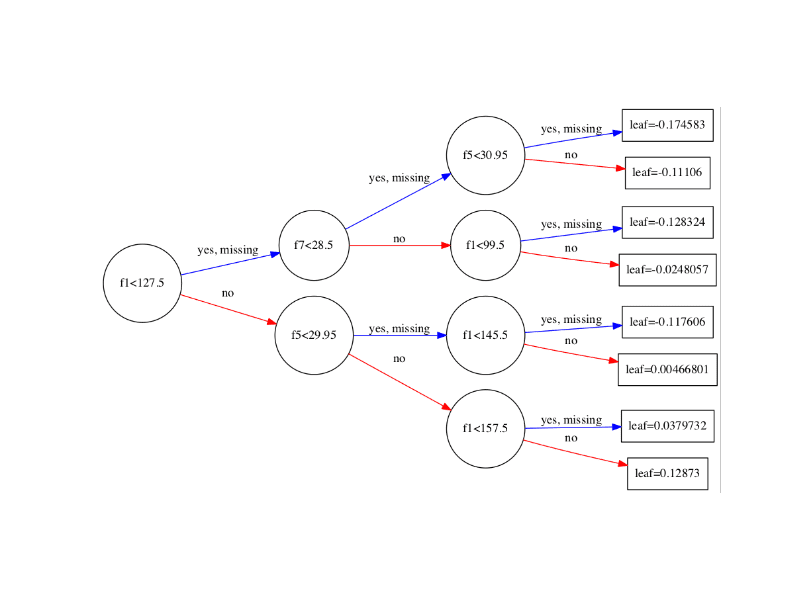
从左到右的单个决策树的XGBoost图
总结
在这篇文章中,您学习了如何在Python中绘制已训练的XGBoost梯度提升模型中的单个决策树。
您对在XGBoost中绘制决策树或对此文章有任何疑问吗?在评论中提出您的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。





 Ensemble in Python")
嗨,Jason,
很好,非常感谢提供一份使用R的精确帖子,因为可视化树并不容易。
我有一个概念性问题,假设模型训练了100棵提升树,我怎么知道哪一棵树表现最好?是否可以定义为最后训练的那棵树,因为最后一棵树的生长考虑了已经生长的99棵树。
谢谢!
Ronen
谢谢Ronen。抱歉,还没有R的示例,但也许很快会有。
有趣的问题,但并不重要,因为集成模型的性能由集成中所有树的贡献决定。一棵树在问题上的表现对整个问题没有意义,因为它只纠正序列中前一棵树的残差。
这有道理吗?
谢谢Jason,您的回答很完美。
很高兴听到这个ronen。
至少对我而言,这种重要性源于向我的客户通过您展示的图表传达模型及其分裂的雄心。
嗨Jason,正如你所说,一棵树的表现没有意义,因为输出是所有树的集合。那么我们为什么要费力地绘制一棵树呢?而且我们绘制的树可能与其他树不同,所以如果我们只是想给出一个树的样子,我们应该绘制哪棵树?
一些开发人员非常感兴趣了解单个树在做什么,以帮助更好地理解整体。
我个人不感兴趣。
嗨,Jason!
你知道如何更改树中特征的字体大小吗?
谢谢!
嗨,Jason,
有没有办法按顺序提取决策树及其参数列表,例如,将它们保存以供在Python外部使用?
谢谢,
Yonatan
抱歉Yonatan,我没做过这个。
告诉我进展如何。
嗨,Jason!
感谢您的分享。
我有一个问题,‘leaf’的输出值是什么意思?
例如,最后一个叶子leaf = 0.12873是什么意思?
谢谢~
好问题,我记不清了,但我想它是由该叶子所占训练数据的比例。
我确定文档会对此做出更清晰的说明。
它绝对不是训练数据的比例,因为它可能包含负值。我现在也在为此苦恼。
对于二元分类,可以通过应用logistic函数(1/(1+exp(x)))(不是-x而是x,这已经很奇怪了)将其转换为概率。但对于多类分类,每棵树都是一个一对多的分类器,你使用1/(1+exp(-x))。
https://github.com/dmlc/xgboost/issues/1746
“值(对于叶子):叶子可能对预测贡献的边距值”(xgb.plot.tree for R,但这里也可能适用?)
嗨,Jason,
一个非常棒的教程,正如你所说,在你的例子中,它将属性重命名为自己的形式,如‘f1’、‘f2’等。在我的例子中没有发生这种情况,因此树不清晰可见。你能帮帮我吗?另外,请告诉我如何保存一棵树的完整分辨率图像。
也许API已经改变了。
抱歉,我不知道如何使图像变大。
以下代码能够设置图像分辨率并将其保存到PDF文件
不错。
谢谢Jason和Frank!
嗨Jason,感谢您的帖子。我有一个问题,我的max_depth = 6,生成的图太小而无法读取。有什么办法可以“放大缩小”图形吗?谢谢。
我不知道,抱歉。
— xgb版本0.6 —
import xgboost as xgb
xgb.to_graphviz(you_xgb_model, num_trees=0, rankdir=’LR’, **{‘size’:str(10)})
调整大小会改变graphviz图的大小,但据我所知没有缩放功能。
如前所述,高分辨率图像,即渲染图像,可以通过以下方式创建:
xgb.to_graphviz(model)
对我来说,这会在IPython控制台中打开,然后我可以右键单击保存图像。
谢谢Dennis。
Jason,我们如何知道红色或蓝色属于哪个类别?
很好的问题。
我想,“否”是0类,“是”是1类。
是否可以在叶节点中获取类/目标名称?
特别是对于多类情况…
可以将树模型输出到一个平面文件吗?或者只支持绘制出来?谢谢。
你也许可以Anna,我不太清楚。我打赌有办法,可以看看xgboost的文档。
你知道如何更改树中特征的字体大小吗?
谢谢!
抱歉,我没有。
你是否发现可以在python中使用特征名进行绘图?这似乎是个bug。
没有,但也许API已经改变了,或者有人在stackoverflow上发布了解决方案?
感谢您的帖子,Jason。
当我尝试plot_tree时,我收到以下ValueError:
ValueError: Unable to parse node: 0:[COLLAT_TYP_GOVT
有什么原因会导致此问题吗?
谢谢
很抱歉听到这个,我没遇到过这个问题。
也许可以确保xgboost是最新的,并且您拥有帖子中的所有代码?
我明白了。原来特征名不能包含空格。
不过我还有另一个问题。树最终会输出叶子值。但是对于多类分类,叶子值是什么意思?
很高兴听到这个消息。
好问题,我还没试过超过两类。你可以试试,然后告诉我你看到了什么。
Jason,感谢您的帖子。
当我尝试使用plot_tree进行HousePrices数据集(使用XGBRegressor)时,它只绘制了一个叶子。有什么可能的原因吗?
也许模型没有完全训练好?
如果能使用实际的特征名称而不是通用的f1,f2,..等就好了。
我同意。
有没有办法将特征名提供给fit函数?
据我所知,没有。
您可以使用pandas dataframe而不是numpy数组,fit将使用dataframe列名而不是f1,f2,...等在图中显示。
感谢分享。
您可以通过将model.feature_names设置为列名来获取特征名。
model.feature_names = list_of_feature_in_order
我可能回答得晚了,也许这对正在寻找类似答案的人有所帮助。
谢谢!
嘿Jason,感谢您耐心的指导!
我可以问您一个问题吗?我使用XGBoost训练一些数据然后进行测试,但是一个新问题是,当测试未知数据时,测试数据的标签有其他选项,我该如何消除一些我不希望出现的选项?
例如,它会标记A为1,但我希望它不会标记A为1(消除选项1)。不确定您是否理解,谢谢!!
不确定我是否理解,抱歉?也许您可以详细说明一下?
那么,在预测一个数据集时,我想知道最接近的五个可能的标签,有什么建议吗?
感谢您的回复,Jason
预测概率。
嗯…我对那个不了解..如果你能告诉我更多就太好了..仍然感谢:)
如果您使用的是sklearn包装器,本教程将展示如何预测概率。
https://machinelearning.org.cn/make-predictions-scikit-learn/
嘿Jason,你是一位很棒的老师。内容很棒。
谢谢!
嗨,Jason,
太棒了,感谢详细的教程!
问题是,系数代表什么(例如,概率,正与负)?我猜根节点具有更高的特征重要性,但我如何解释最右边的节点?
谢谢,
安德烈
通常,我们不解释集成中的树。
叶子上的值是什么意思?
谢谢
好问题。
我怀疑是训练数据对叶子的支持。
嗨,Jason,
非常感谢您的精彩教程,如果您能帮助我解决运行教程时遇到的问题,我将非常感激!
当我运行代码时,一切都正常,直到我尝试“plot_tree(model)”。我收到以下错误。
您是否可能知道我遇到的问题?我怀疑可能是安装graphviz包的问题,我为此做了以下操作:
1. 从(https://graphviz.gitlab.io/_pages/Download/Download_windows.html)安装windows软件包
2. 安装python graphviz包(使用anaconda prompt“pip install graphviz)
3. 将C:\Program Files (x86)\Graphviz2.38\bin添加到用户路径
4. 将C:\Program Files (x86)\Graphviz2.38\bin\dot.exe添加到系统路径
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
回溯(最近一次调用)
File “”, line 1, in
plot_tree(model)
File “C:\ProgramData\Anaconda3\lib\site-packages\xgboost\plotting.py”, line 278, in plot_tree
rankdir=rankdir, **kwargs)
File “C:\ProgramData\Anaconda3\lib\site-packages\xgboost\plotting.py”, line 227, in to_graphviz
graph = Digraph(graph_attr=kwargs)
File “C:\ProgramData\Anaconda3\lib\site-packages\graphviz\dot.py”, line 61, in __init__
super(Dot, self).__init__(filename, directory, format, engine, encoding)
TypeError: super(type, obj): obj must be an instance or subtype of type
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
很抱歉听到这个,我没有好主意。
您可以尝试将错误发布到stackoverflow?
谢谢Jason,这听起来是个解决办法!
嗨 Jason,
我正在处理一个回归问题,并且正在使用XGboost。我尝试修改您展示的代码来绘制一棵树,并且运行正常。但我的问题是:
假设我使用梯度提升回归器,以决策树作为基础学习器,然后打印出第一棵树。对于给定的实例,我可以沿着树向下遍历,找出对因变量的大致近似值。我理解XGBoost的公式与GBM不同,但有没有办法得到一个类似的图?我提取的图只有“是”和“否”的决策以及一些叶子节点的值,对我来说(不像开发者那样)没有任何用处。请问是否有其他图表可以帮助我在第n个提升轮中得到因变量的大致近似值?
并没有,因为你有成百上千棵树。
谢谢!我同意有很多树,但我认为前几棵树会给我一个因变量的粗略估计值,而后续的树只用于微调这个粗略估计值。给定一个XGB模型及其参数,有没有办法找到它等同于GBM的表示?(如果问题听起来很傻,请原谅,我对机器学习概念只有几个月的研究,还无法消化我这几个月读到的所有内容)
在很大程度上它们是相同的算法,“随机梯度提升”,但xgboost的实现是从头开始设计的,以便在训练和推理期间提高执行速度。
谢谢!
在XGBoost的回归问题中,如何建立模型预测值与图中的叶节点或终端节点之间的关系?
不确定我是否明白,为什么会这样?
假设我有一个数据集,我训练了一个xgboost回归模型,其中80%的数据用作训练,其余20%用作预测测试。
另外,plot_tree()方法被用于xgBosst Regressor,以获得与本文开头所示图类似的图。
现在的问题是如何建立树图中的叶节点与模型得到的预测值之间的关系?
(并且,叶节点中的那些值究竟对应什么?)
我手头没有,抱歉。请记住,模型中有数百棵树。
也许 xgboost API 中有一些功能可以让你发现模型用来进行预测的每棵树的叶节点。
你好,我也有同样的问题,你知道答案吗?
可以绘制模型中的最后一棵树吗?
我不知道为什么不可以。抱歉,我没有例子。
Jason,树的图片非常非常小。
所以,我无法看到这棵树,如何才能得到一个“大”的树的图片?
我很确定有办法。抱歉,我没有例子。
有不止一种方法。这个很简单
# 绘制单棵树
plot_tree(model)
fig = pyplot.gcf() # 解决低分辨率问题
fig.set_size_inches(150, 100) # # 解决低分辨率问题
pyplot.show()
嗨,Jason,
我们刚刚在dtreeviz库中实现了xgboost https://github.com/parrt/dtreeviz。
它包含了许多有用的可视化,用于树结构、叶节点元数据等。
如果您有时间看看或试用一下,我很想听听您的反馈。
Tudor
感谢分享。
你好,可以使用plot_tree根据测试数据的预测来绘制决策树吗?如果不行,您能否推荐一个可以执行此操作的库?
树可以根据训练数据绘制,而不是测试数据,我们不绘制预测。
您是指每个输入的路径通过树吗?抱歉,我不知道有可以做到这一点的库。
您可以尝试dtreeviz。它有一个可视化功能,可以绘制输入示例的预测路径。就像这个一样 https://github.com/parrt/dtreeviz/blob/master/testing/samples/diabetes-LR-2-X.svg
感谢分享!
Jason博士您好。
再次感谢您的好文章。我有两个问题想问您。
第一个问题:我可以知道如何解释最底层的叶节点吗?最底层的节点带有浮点数值“leaf”,它们是什么意思?例如,leaf = 0.15…,0.16…。您能详细解释一下吗?
第二个问题:我们是否必须先做特征重要性,然后使用其结果重新训练XGBoost算法,根据特征重要性的结果选择权重较高的特征?完成这些步骤后,才能进行超参数优化,对吗?
感谢您的帮助。
单个树作为集成的一部分可能没有太多解释性。节点是输出/预测或用于预测的分割点 – 我不记得了,抱歉 – 也许可以查阅文档。
模型在训练过程中会自动执行特征选择/重要性加权。所有的树都是这样做的。
在单棵树中,一个特征可能出现两次或更多次吗?
一如既往的优秀作品。谢谢。
为什么“是,缺失”会出现在所有节点的交互中?这个“缺失”与什么有关?
你好 Chathurangi… 如下的讨论可能很有趣
https://stackoverflow.com/questions/62176516/how-to-visualize-an-xgboost-tree-from-gridsearchcv-output
我想知道我们如何使用它来可视化scikit-learn中的梯度提升分类器?
(https://scikit-learn.cn/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html)