你必须理解你的数据,才能从机器学习算法中获得最佳结果。
了解数据最快的方法是使用数据可视化。
在这篇文章中,你将确切了解如何使用 Pandas 在 Python 中可视化你的机器学习数据。
使用我的新书《使用 Python 进行机器学习精通》启动你的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。
在 Python 中使用 Pandas 可视化机器学习数据
摄影:Alex Cheek,保留部分权利。
关于食谱
本文中的每个食谱都是完整且独立的,因此你可以将其复制并粘贴到自己的项目中并立即使用。
Pima 印第安人数据集用于演示每个图。该数据集描述了 Pima 印第安人的医疗记录,以及每位患者在五年内是否会患上糖尿病。因此,它是一个分类问题。
它是一个很好的演示数据集,因为所有输入属性都是数值型的,并且要预测的输出变量是二元的(0 或 1)。
需要 Python 机器学习方面的帮助吗?
参加我为期 2 周的免费电子邮件课程,探索数据准备、算法等等(附带代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
单变量图
在本节中,我们将介绍可用于独立理解每个属性的技术。
直方图
快速了解每个属性分布的一种方法是查看直方图。
直方图将数据分组到箱中,并提供每个箱中观测值的数量。从箱的形状,你可以快速了解属性是“高斯”、偏斜还是甚至呈指数分布。它还可以帮助你发现可能的异常值。
|
1 2 3 4 5 6 7 8 |
# 单变量直方图 import matplotlib.pyplot as plt import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) data.hist() plt.show() |
我们可以看到,属性 age、pedi 和 test 可能呈指数分布。我们还可以看到,mass、pres 和 plas 属性可能呈高斯分布或近似高斯分布。这很有趣,因为许多机器学习技术都假设输入变量呈高斯单变量分布。
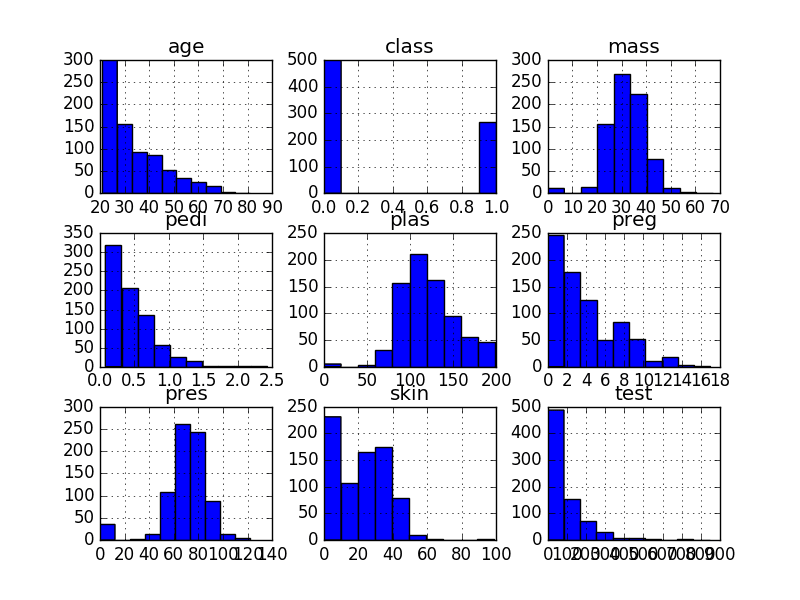
单变量直方图
密度图
密度图是快速了解每个属性分布的另一种方法。这些图看起来像抽象的直方图,每根柱子的顶部都绘制了一条平滑的曲线,就像你的眼睛试图在直方图中做的那样。
|
1 2 3 4 5 6 7 8 |
# 单变量密度图 import matplotlib.pyplot as plt import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) data.plot(kind='density', subplots=True, layout=(3,3), sharex=False) plt.show() |
我们可以看到每个属性的分布比直方图更清晰。
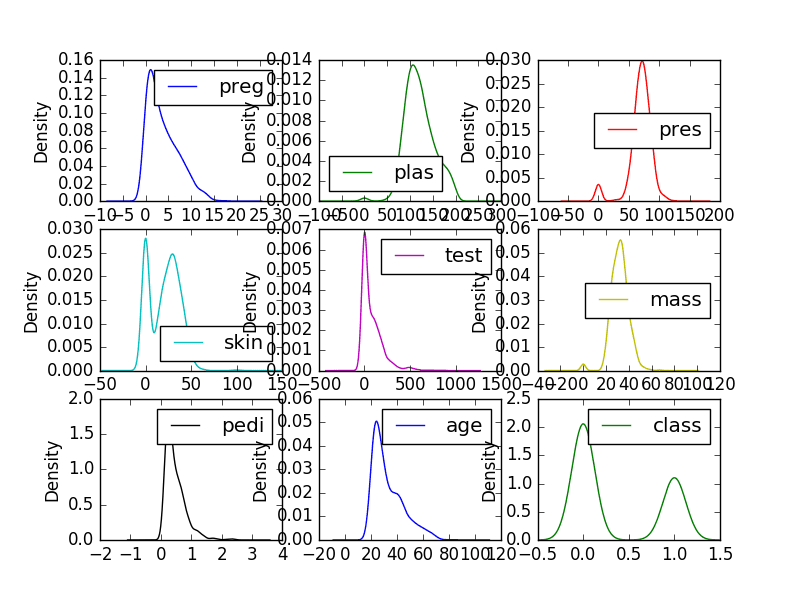
单变量密度图
箱线图
另一种有用的查看每个属性分布的方法是使用箱线图,简称箱图。
箱线图总结了每个属性的分布,绘制了一条中位数(中间值)线,并在第 25 和第 75 百分位数(数据中间 50%)周围绘制了一个方框。晶须表示数据的散布情况,晶须外部的点显示候选异常值(值大于数据中间 50% 散布大小的 1.5 倍)。
|
1 2 3 4 5 6 7 8 |
# 箱线图 import matplotlib.pyplot as plt import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) data.plot(kind='box', subplots=True, layout=(3,3), sharex=False, sharey=False) plt.show() |
我们可以看到属性的分布差异很大。有些属性,如 *age*、*test* 和 *skin*,似乎明显偏向较小的值。
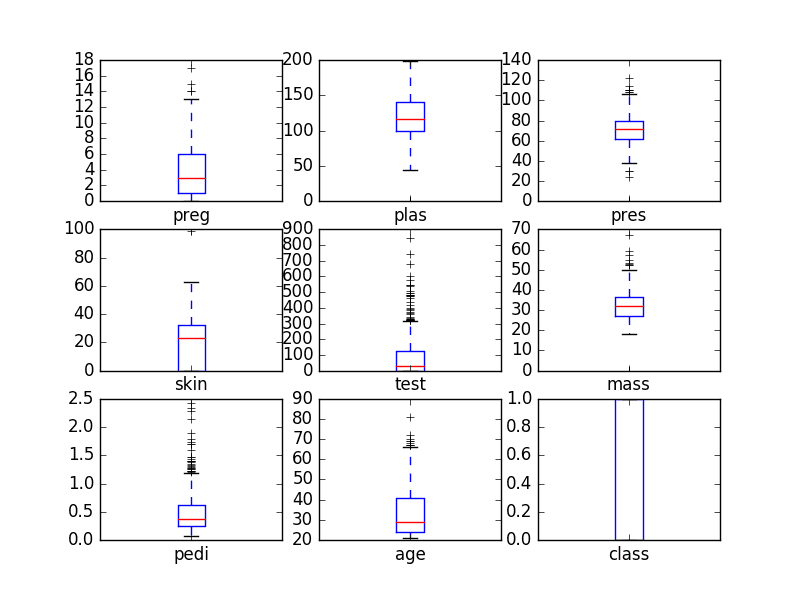
单变量箱线图
多变量图
本节展示了多个变量之间相互作用的图表示例。
相关矩阵图
相关性表示两个变量之间变化的关联程度。如果两个变量以相同的方向变化,则它们呈正相关。如果它们以相反的方向共同变化(一个上升,一个下降),则它们呈负相关。
您可以计算每对属性之间的相关性。这被称为相关矩阵。然后,您可以绘制相关矩阵,并了解哪些变量彼此之间具有高度相关性。
了解这一点很有用,因为如果数据中存在高度相关的输入变量,某些机器学习算法(如线性回归和逻辑回归)的性能可能会很差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 校正矩阵图 import matplotlib.pyplot as plt import pandas import numpy url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) correlations = data.corr() # 绘制相关矩阵 fig = plt.figure() ax = fig.add_subplot(111) cax = ax.matshow(correlations, vmin=-1, vmax=1) fig.colorbar(cax) ticks = numpy.arange(0,9,1) ax.set_xticks(ticks) ax.set_yticks(ticks) 轴.设置X轴标签(名称) ax.set_yticklabels(names) plt.show() |
我们可以看到矩阵是对称的,即矩阵的左下部分与右上部分相同。这很有用,因为我们可以在一个图中看到相同数据的两种不同视图。我们还可以看到,从左上角到右下角的对角线中,每个变量都与其他变量完全正相关(正如您所期望的)。
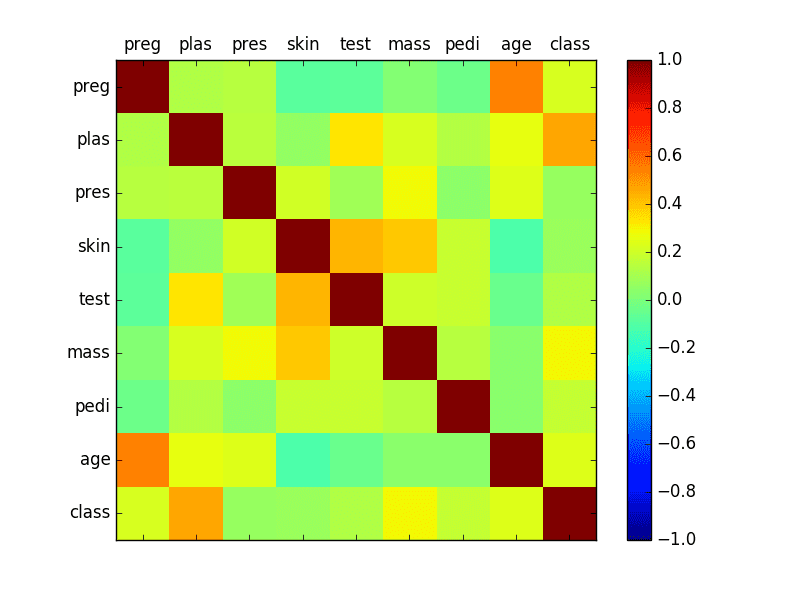
相关矩阵图
散点图矩阵
散点图将两个变量之间的关系显示为二维中的点,每个属性一个轴。您可以为数据中的每对属性创建一个散点图。将所有这些散点图一起绘制称为散点图矩阵。
散点图对于发现变量之间的结构化关系很有用,例如您是否可以用一条线来总结两个变量之间的关系。具有结构化关系的属性也可能相关,并且是将其从数据集中删除的良好候选。
|
1 2 3 4 5 6 7 8 9 |
# 散点图矩阵 import matplotlib.pyplot as plt import pandas from pandas.plotting import scatter_matrix url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) scatter_matrix(data) plt.show() |
与相关矩阵图一样,散点图矩阵是对称的。这对于从不同角度查看成对关系很有用。由于绘制每个变量与自身的散点图意义不大,因此对角线显示了每个属性的直方图。
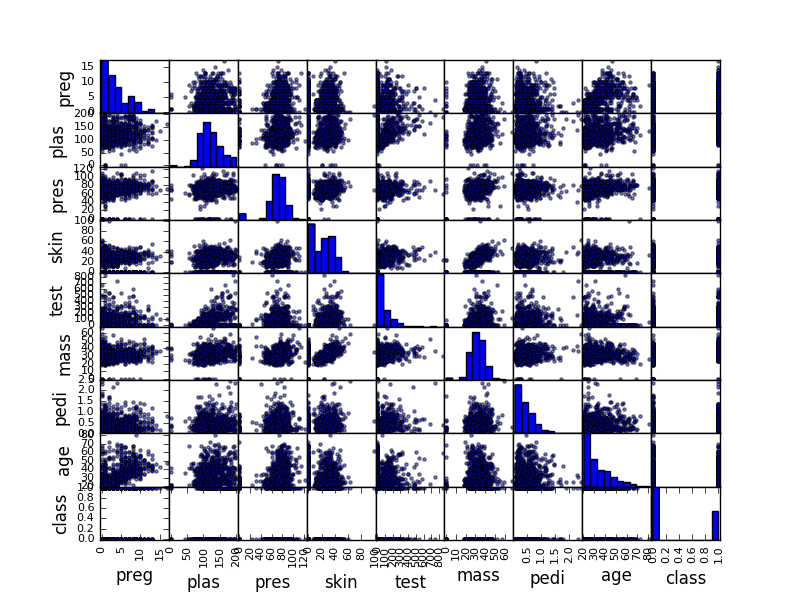
散点图矩阵
总结
在这篇文章中,你发现了许多可以使用 Pandas 在 Python 中更好地理解机器学习数据的方法。
具体来说,你学习了如何使用以下方法绘制数据:
- 直方图
- 密度图
- 箱线图
- 相关矩阵图
- 散点图矩阵
打开你的 Python 交互式环境,尝试每个食谱。
你对 Pandas 或这篇文章中的食谱有任何疑问吗?在评论中提问,我将尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






嗨,Jason Brownlee,
谢谢这篇帖子。到目前为止,我一直使用不同的 python 可视化库,如 matplotlib、plotly 或 seaborn,以从我加载到 pandas 数据帧中的数据中获取更多信息。到目前为止,我不知道如何使用 pandas 本身进行可视化。
从现在开始,我将使用你的食谱进行可视化。
很高兴这篇帖子对 saimadhu 有用。
你好 Jason,
我们可以从类别变量箱线图中推断出什么,为什么以及何时得到这种图。
好问题,naresh。
箱线图非常适合快速了解数据的分布以及数据在尺度上的主要集中区域。它还可以帮助您快速发现异常值(超出触须或实际 > 或 < 1.5 x IQR)。
你好,杰森,
当我尝试为我的包含 12 个变量的数据集创建相关矩阵时,矩阵中只有 7 个变量有颜色矩阵,而剩下的 5 个是白色。我只是将这个
“ticks=np.arange(0,12,1)” 从 9 更改为 12,
import numpy as np
names=[‘PassId’,’Sur’,’Pclas’,’Name’,’Sex’,’Age’,’SibSp’,’Parch’,’Ticket’,’Fare’,’Cabin’,’Emb’]
correlation=train.corr()
#创建相关矩阵
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlation, vmin=-1, vmax =1)
fig.colorbar(cax)
ticks=np.arange(0,12,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
plt.show()
散点图也有类似情况,请问我哪里有问题
还有一件事,我们如何决定哪个散点图最有价值
好问题,naresh,我一时半会儿想不出来。
我建议研究如何为函数指定自己的颜色列表。也许默认限制是 6-7 个。
嗨,Jason,
我很好奇如何为多元逻辑回归的概率制作图。你有什么想法或示例吗?
谢谢你。
抱歉,手头没有。
考虑尝试几种不同的方法,看看哪种能最好地传达理解。
还可以考虑复制现有分析中使用的方法。
原谅我的无知,但这难道不是用 matplotlib 可视化数据吗?而不是 Pandas?
是的,通过 pandas 封装器使用 matplotlib。
嗨,Jason,
你有没有关于使用分类数据进行二元分类(和可视化)的博客?那会对我很有帮助。
我在 Python 中有一些。尝试搜索一下。
您在寻找特定的东西吗?
我有分类变量和连续变量特征集。在预测(二元分类)之后,我想可视化每个特征以及特征组合如何导致预测。例如,我有一个分类特征,如收入范围、性别、职业,以及年龄作为连续特征。这些特征如何影响预测。
在应用机器学习中,我们通常为了更好的预测能力而放弃了预测的可理解性。
通常,为了更深入地理解预测的原因,您可以使用线性模型并放弃一些预测技能。
通常我不会费心评论出版物,但你的文章总是切中要害。极其有用,文笔流畅,而且代码确实有效。恭喜!
谢谢 FF,我真的很感谢你的好意和支持!
你好,杰森,
希望你一切都好!
实际上,我想知道如何在 Matplotlib 中设置 X 和 Y 轴的间隔大小。例如,我希望 X 轴的刻度值为 0、0.1、0.2、0.3,依此类推直到 1.0;Y 轴的刻度值为 0、20、40、60,依此类推直到 100。我有一个 .csv 文件格式的数据集,其中我将一列作为 X 轴,另一列作为 Y 轴。
非常感谢。
我建议阅读 matplotlib API。
你好 Jason,
在涉及大量解释特征的多变量分析中,视觉推断可能不是解决方案。您建议如何处理此类情况?
谢谢
也许是投影方法?
谢谢杰森。你的帖子为我节省了很多时间。
我真的很高兴听到这个消息,谢谢!
精彩博客!您的 14 天教程也很棒!
学到了很多!
非常感谢你,杰森
你有关于深度学习模型的博客吗?
谢谢!
我有,从这里开始
https://machinelearning.org.cn/start-here/#deeplearning
你好,是否可能找到字符串之间的相关性(例如:网站与其使用城市之间的相关性)或找到字符串与数字之间的相关性(例如:网站与观看该网站的人群年龄段之间的相关性)?
是的,首先将标签转换为等级数据,然后使用非参数相关性度量。
超棒的博客!
我们如何关联直方图和密度图?
密度图与峰度相同吗?
这两个图都可以显示分布以及分布的特征,如形状、偏度等。
我想看看我的每个变量与我的目标变量是如何相关的!我该如何可视化呢!
谢谢!
关联是一种很好的方法
https://machinelearning.org.cn/how-to-use-correlation-to-understand-the-relationship-between-variables/
在相关矩阵中,如何决定哪些独立变量需要用于逻辑回归模型?
皮尔逊相关系数的值介于 +1 和 -1 之间,是否有任何阈值可以决定哪些独立变量不能被考虑?
也许可以尝试不同的阈值,看看哪种最适合您的数据集?
谢谢 Jason Brownlee,我发现这个网站也许可以添加一些东西
http://www.codibits.com/category/python/matplotlib/
感谢分享。
太棒了!
但是先生,我的问题是如果 x1=[1,2,3] 和 x2=[4,5,6,7],那么如何使用 matplotlib.pyplot as plt 绘制 plt.scatter(x1,x2)
scatter() 函数接受两个参数,分别表示 x 和 y 坐标列表。
例如:
太棒了,先生
但我的问题是如何绘制 plt.scatter(x1,x2)
如果 x1=[1,2,3]
而 x2=[4,5,6,9,8]
使用 matplotlib.pyplot as plt
它显示 x 和 x2 应该具有相同的大小
如果它们大小不同,如何绘制它
您必须拥有相同数量的 x 和 y 坐标。
你好,先生……谢谢你提供这么好的食谱。
我是机器学习课程的新手,我正在使用 python idle 对我的数据集进行基本可视化。但对于许多可视化方法,例如散点图矩阵,它没有响应。请问你能解释一下这背后的原因吗(无论是由于数据大小还是缩放问题)。
数据大小=2560*45
您说的“没有响应”是什么意思?
当我绘制直方图时,图形太小了。我该如何调整大小?
我建议您查看 matplotlib API 中与图形大小相关的部分。
先生,我想使用保存在我笔记本电脑上的 csv 文件。请告诉我用于加载数据和打印此图的命令。
我在这里解释如何加载数据
https://machinelearning.org.cn/load-machine-learning-data-python/
杰森:非常感谢你的这篇文章!
尤其是相关矩阵图……
我很高兴我帮上忙了。
好文章,谢谢。我注意到代码示例中有一处写着“校正矩阵”。我猜这是个错别字,对吗?
不,有一个相关矩阵的例子。
好技巧,杰森。
验证分类数据有哪些方法?
你具体指的是什么?
你能举个例子吗?
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import os
os.getcwd()
os.chdir(“C:/Users/user/desktop”)
diabetes = pd.read_csv(‘diabetes.csv’)
print(diabetes.columns)
print(“dimension of diabetes data: {}”.format(diabetes.shape))
print(diabetes.groupby(‘Diabetes’).size())
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(diabetes.loc[:, diabetes.columns != ‘Diabetes’], diabetes[‘Diabetes’], stratify=diabetes[‘Diabetes’], random_state=66)
嘿,杰森,我有一个疑问……
我正在使用 Jupyter Notebook 中的糖尿病数据集。在这里我无法找到目标数据集的形状,也无法知道我的数据集用于训练和测试的分类百分比。
您可以通过以下方式访问数组的形状:array.shape
您可以选择拆分作为 train_test_split() 的变量
https://scikit-learn.cn/stable/modules/generated/sklearn.model_selection.train_test_split.html
就像我想知道我应该编写哪行代码来获取目标形状并查看数据集训练和测试的划分百分比。
如何获取数据集中特征之间的关系。
这叫做相关性
https://machinelearning.org.cn/how-to-use-correlation-to-understand-the-relationship-between-variables/
很高兴看到你教授 matplotlib 的面向对象方法。我认为 95% 的博客和教程都坚持使用 matlab 接口。这种方法更像 Python。
谢谢你,麦克。
如何使用数据集作为输入实现键能算法
什么是“键能算法”?
你好,Jasan,
我有一个疑问,对于异常值检测(UCL-上限控制线),以下哪种方法是建议的。
a) 百分位数法
将变量限制在 90% 百分位数。任何 >90% 的值都将被视为异常值
b) 标准差法
创建 (均值+3标准差) 或 (中位数+3标准差) 的限制
也许可以在您的数据集上测试一系列方法,并发现哪种方法最适合您。
嗨,Jason,
我有一些疑问。
1) 在给定的数据文件中,每行是否代表“preg”、“plas”、“pres”、“skin”、“test”、“mass”、“pedi”、“age”、“class”?
2) 在直方图部分,请问y轴变量是什么?它是x轴变量在数据文件中出现的次数吗?
3) 在密度图中,y轴范围是如何计算的?
4) 如果我想为某些模型预测缩放特征(0到1的值),我仍然能得到成对散点图的准确结果吗?另外,当我有了新数据并想预测输出变量时,缩放将如何影响我的输出精度?
是的,每列都是一个不同的度量,您可以在这里了解更多信息
https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.names
直方图中的 y 轴是落入该箱的示例数量的计数。
密度图中的 y 值是观察到该值的概率,独立于所有其他值,更多关于概率密度估计的信息请参阅此处
https://machinelearning.org.cn/probability-density-estimation/
对于某些模型和数据集,缩放可以改善建模,更多信息请参阅此处
https://machinelearning.org.cn/standardscaler-and-minmaxscaler-transforms-in-python/
非常感谢。另外,有没有办法可以在一个图表中将特征 X1,X2,…变量放在 X 轴,将输出 Y 放在 Y 轴?是否会有多个曲线代表不同的特征?当绘制 X1 对 Y 曲线时,X2, X3,…的值将取什么?
不客气。
是的,您可以在一个图表上绘制所有变量,但我预计它会很混乱。
嗨,Jason,
我有一个疑问,
我们如何绘制分类列或数据,我们可以使用哪些图来表示分类数据与数值数据或分类数据与分类数据
谢谢你
通常使用按频率着色的表格。
就一句话……我们是在讨论 PANDAS 还是 MATPLOTLIB?
嗨,Andrea……两个库都在使用。
# 散点图矩阵
import matplotlib.pyplot as plt
import pandas from pandas.plotting import scatter_matrix
在《机器学习精通》一书中,第 5.2 节涉及描述性统计。
似乎 set_option('precision', 3) 已不再受支持。有什么替代方案可以使用吗?
为了回答我上面的问题,看起来下面的代码将正确工作……
set_option('display.float_format', '{:.3f}'.format)
感谢您的反馈,加里!
非常有用的帖子。我将使用 pandas 进行绘图。
感谢您的反馈和支持,穆罕默德!可以在以下资源中找到更多选项
https://machinelearning.org.cn/data-visualization-in-python-with-matplotlib-seaborn-and-bokeh/