投票是一种集成机器学习算法。
对于回归问题,投票集成涉及预测多个其他回归模型的平均值。
在分类问题中,硬投票集成模型涉及对来自其他模型的清晰类标签的投票进行求和,并预测获得最多投票的类别。软投票集成模型涉及对类标签的预测概率进行求和,并预测具有最大累积概率的类标签。
在本教程中,您将学习如何在 Python 中为机器学习算法创建投票集成模型。
完成本教程后,您将了解:
- 投票集成模型涉及对分类模型的预测进行求和,或对回归模型的预测进行平均。
- 投票集成模型的工作原理、何时使用投票集成模型以及该方法的局限性。
- 如何为分类预测建模实现硬投票集成模型和软投票集成模型。
开启您的项目,阅读我的新书《Python 集成学习算法》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。

如何使用 Python 开发投票集成
图片由 美国土地管理局 提供,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 投票集成模型
- 投票集成模型的 Scikit-learn API
- 分类投票集成模型
- 分类硬投票集成模型
- 分类软投票集成模型
- 回归投票集成模型
投票集成模型
投票集成模型(或“多数投票集成模型”)是一种集成机器学习模型,它组合了来自多个其他模型的预测。
这是一种可以提高模型性能的技术,理想情况下可以实现比集成中使用的任何单个模型更好的性能。
投票集成模型通过组合多个模型的预测来工作。它可以用于分类或回归。在回归的情况下,这涉及计算模型预测的平均值。在分类的情况下,将对每个标签的预测进行求和,并预测具有多数投票的标签。
- 回归投票集成模型:预测是贡献模型的平均值。
- 分类投票集成模型:预测是贡献模型的多数投票。
对于分类问题,存在两种多数投票预测方法;它们是硬投票和软投票。
硬投票涉及对每个类别的预测进行求和,并预测得票最多的类别。软投票涉及对每个类别进行预测的概率(或类似概率的得分)进行求和,并预测具有最大累积概率的类别。
- 硬投票。预测来自模型的投票总和最大的类别
- 软投票。预测来自模型的累积概率最大的类别。
投票集成模型可以被视为一个元模型,即模型的模型。
作为一个元模型,它可以与任何现有训练机器学习模型的集合一起使用,而现有模型无需知道它们正在集成中使用。这意味着您可以探索在您的预测建模任务的任何集合或子集中使用投票集成模型。
当您拥有两个或更多模型在预测建模任务上表现良好时,投票集成模型是合适的。集成中使用的模型必须在很大程度上同意它们的预测。
一种组合输出的方法是投票——与 bagging 中使用的机制相同。但是,(无权重的)投票只有在学习方案表现相当好时才有意义。如果三个分类器中有两个做出了明显错误的预测,那我们就麻烦了!
— 第 497 页,《数据挖掘:实用机器学习工具与技术》,2016 年。
何时使用投票集成模型
- 集成中的所有模型都具有普遍相同的良好性能。
- 集成中的所有模型大多已经达成一致。
当投票集成模型使用的模型预测清晰的类标签时,硬投票是合适的。当投票集成模型使用的模型预测类成员资格的概率时,软投票是合适的。软投票可用于不原生预测类成员资格概率的模型,尽管可能需要 在将其用于集成之前对其类似概率的得分进行校准(例如,支持向量机、k-近邻和决策树)。
- 硬投票适用于预测类标签的模型。
- 软投票适用于预测类成员资格概率的模型。
投票集成模型不保证能提供比集成中使用的任何单个模型更好的性能。如果集成中使用的任何给定模型表现优于投票集成模型,则应使用该模型而不是投票集成模型。
并非总是如此。投票集成模型可以提供比单个模型更低的预测方差。这可以体现在回归任务的预测误差方差较低。这也可以体现在分类任务的准确性方差较低。这种较低的方差可能导致集成模型的平均性能降低,鉴于模型更高的稳定性和置信度,这可能是可取的。
如果以下情况,请使用投票集成模型
- 它比集成中使用的任何模型都能提供更好的性能。
- 它提供的方差比集成中使用的任何模型都低。
投票集成模型尤其适用于使用随机学习算法且每次在相同数据集上训练时都会产生不同最终模型的机器学习模型。一个例子是使用随机梯度下降进行拟合的神经网络。
欲了解更多关于此主题的信息,请参阅教程
投票集成模型的另一个特别有用的情况是,当组合使用超参数略有不同的相同机器学习算法的多个拟合模型时。
投票集成模型最有效的时候是
- 组合使用随机学习算法训练的模型的多个拟合。
- 组合使用具有不同超参数的模型的多个拟合。
投票集成模型的一个局限性在于它对所有模型一视同仁,这意味着所有模型对预测的贡献均等。如果某些模型在某些情况下表现良好,而在其他情况下表现不佳,则这是一个问题。
为了解决这个问题,投票集成模型的一个扩展是使用贡献模型的加权平均值或加权投票。这有时称为融合。更进一步的扩展是使用机器学习模型来学习何时以及在多大程度上信任每个模型进行预测。这被称为堆叠泛化,或简称堆叠。
投票集成模型的扩展
- 加权平均集成模型(融合)。
- 堆叠泛化(堆叠)。
现在我们熟悉了投票集成模型,让我们仔细看看如何创建投票集成模型。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
投票集成模型的 Scikit-learn API
投票集成模型可以从头开始实现,尽管这对初学者来说可能具有挑战性。
scikit-learn Python 机器学习库提供了机器学习投票的实现。
它可在库版本 0.22 及更高版本中使用。
首先,通过运行以下脚本确认您正在使用该库的现代版本
|
1 2 3 |
# 检查 scikit-learn 版本 import sklearn print(sklearn.__version__) |
运行脚本将打印您的 scikit-learn 版本。
您的版本应该相同或更高。如果不是,您必须升级您的 scikit-learn 库版本。
|
1 |
0.22.1 |
投票通过 VotingRegressor 和 VotingClassifier 类提供。
这两种模型的操作方式相同,并且接受相同的参数。使用该模型需要您指定一组进行预测并组合到投票集成模型中的估计器。
基础模型的列表通过“estimators”参数提供。这是一个 Python 列表,列表中的每个元素都是一个元组,包含模型名称和配置好的模型实例。列表中的每个模型都必须具有唯一的名称。
例如,下面定义了两个基础模型
|
1 2 3 |
... models = [('lr',LogisticRegression()),('svm',SVC())] ensemble = VotingClassifier(estimators=models) |
列表中的每个模型也可以是一个 Pipeline,包括模型在训练数据集上拟合之前所需的任何数据预处理。
例如
|
1 2 3 |
... models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))] ensemble = VotingClassifier(estimators=models) |
在对分类问题使用投票集成模型时,可以通过“voting”参数指定投票类型,例如硬投票或软投票,并将其设置为字符串‘hard’(默认值)或‘soft’。
例如
|
1 2 3 |
... models = [('lr',LogisticRegression()),('svm',SVC())] ensemble = VotingClassifier(estimators=models, voting='soft') |
现在我们熟悉了 scikit-learn 中的投票集成模型 API,让我们来看一些实际示例。
分类投票集成模型
在本节中,我们将研究如何将堆叠用于分类问题。
首先,我们可以使用 make_classification() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成二元分类问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们将演示此数据集的硬投票和软投票。
分类硬投票集成模型
我们可以使用 k-近邻算法 来演示硬投票。
我们可以拟合 KNN 算法的五个不同版本,每个版本在进行预测时使用不同数量的邻居。我们将使用 1、3、5、7 和 9 个邻居(奇数,以避免平局)。
我们的期望是,通过组合每个不同 KNN 模型预测的类别标签,硬投票集成模型将平均实现比任何独立使用的模型更好的预测性能。
首先,我们可以创建一个名为 get_voting() 的函数,该函数创建每个 KNN 模型并将模型组合成一个硬投票集成模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 获取模型投票集成 def get_voting(): # 定义基础模型 models = list() models.append(('knn1', KNeighborsClassifier(n_neighbors=1))) models.append(('knn3', KNeighborsClassifier(n_neighbors=3))) models.append(('knn5', KNeighborsClassifier(n_neighbors=5))) models.append(('knn7', KNeighborsClassifier(n_neighbors=7))) models.append(('knn9', KNeighborsClassifier(n_neighbors=9))) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble |
然后,我们可以创建一个模型列表进行评估,包括每个独立配置的 KNN 模型以及硬投票集成模型。
这将有助于我们直接将每个独立配置的 KNN 模型与集成模型在分类准确率得分分布方面进行比较。下面的 get_models() 函数为我们创建了要评估的模型列表。
|
1 2 3 4 5 6 7 8 9 10 |
# 获取要评估的模型列表 定义 获取_模型(): models = dict() models['knn1'] = KNeighborsClassifier(n_neighbors=1) models['knn3'] = KNeighborsClassifier(n_neighbors=3) models['knn5'] = KNeighborsClassifier(n_neighbors=5) models['knn7'] = KNeighborsClassifier(n_neighbors=7) models['knn9'] = KNeighborsClassifier(n_neighbors=9) models['hard_voting'] = get_voting() 返回 models |
每个模型将使用重复的 k 折交叉验证进行评估。
下面的 evaluate_model() 函数接受一个模型实例,并以三次重复分层 10 折交叉验证的得分列表形式返回。
|
1 2 3 4 5 |
# 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') return scores |
然后,我们可以报告每个算法的平均性能,并创建一个箱须图来比较每个算法的准确率得分分布。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 将硬投票与独立分类器进行比较 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import VotingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2) 返回 X, y # 获取模型投票集成 def get_voting(): # 定义基础模型 models = list() models.append(('knn1', KNeighborsClassifier(n_neighbors=1))) models.append(('knn3', KNeighborsClassifier(n_neighbors=3))) models.append(('knn5', KNeighborsClassifier(n_neighbors=5))) models.append(('knn7', KNeighborsClassifier(n_neighbors=7))) models.append(('knn9', KNeighborsClassifier(n_neighbors=9))) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble # 获取要评估的模型列表 定义 获取_模型(): models = dict() models['knn1'] = KNeighborsClassifier(n_neighbors=1) models['knn3'] = KNeighborsClassifier(n_neighbors=3) models['knn5'] = KNeighborsClassifier(n_neighbors=5) models['knn7'] = KNeighborsClassifier(n_neighbors=7) models['knn9'] = KNeighborsClassifier(n_neighbors=9) models['hard_voting'] = get_voting() 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例后,将首先报告每个模型的平均和标准差准确率。
注意:由于算法或评估程序的随机性、数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
我们可以看到,硬投票集成模型的分类准确率约为 90.2%,优于所有独立使用的模型。
|
1 2 3 4 5 6 |
>knn1 0.873 (0.030) >knn3 0.889 (0.038) >knn5 0.895 (0.031) >knn7 0.899 (0.035) >knn9 0.900 (0.033) >hard_voting 0.902 (0.034) |
然后,将创建一个箱须图来比较每个模型的准确率得分分布,使我们能够清楚地看到硬投票集成模型平均而言优于所有独立使用的模型。
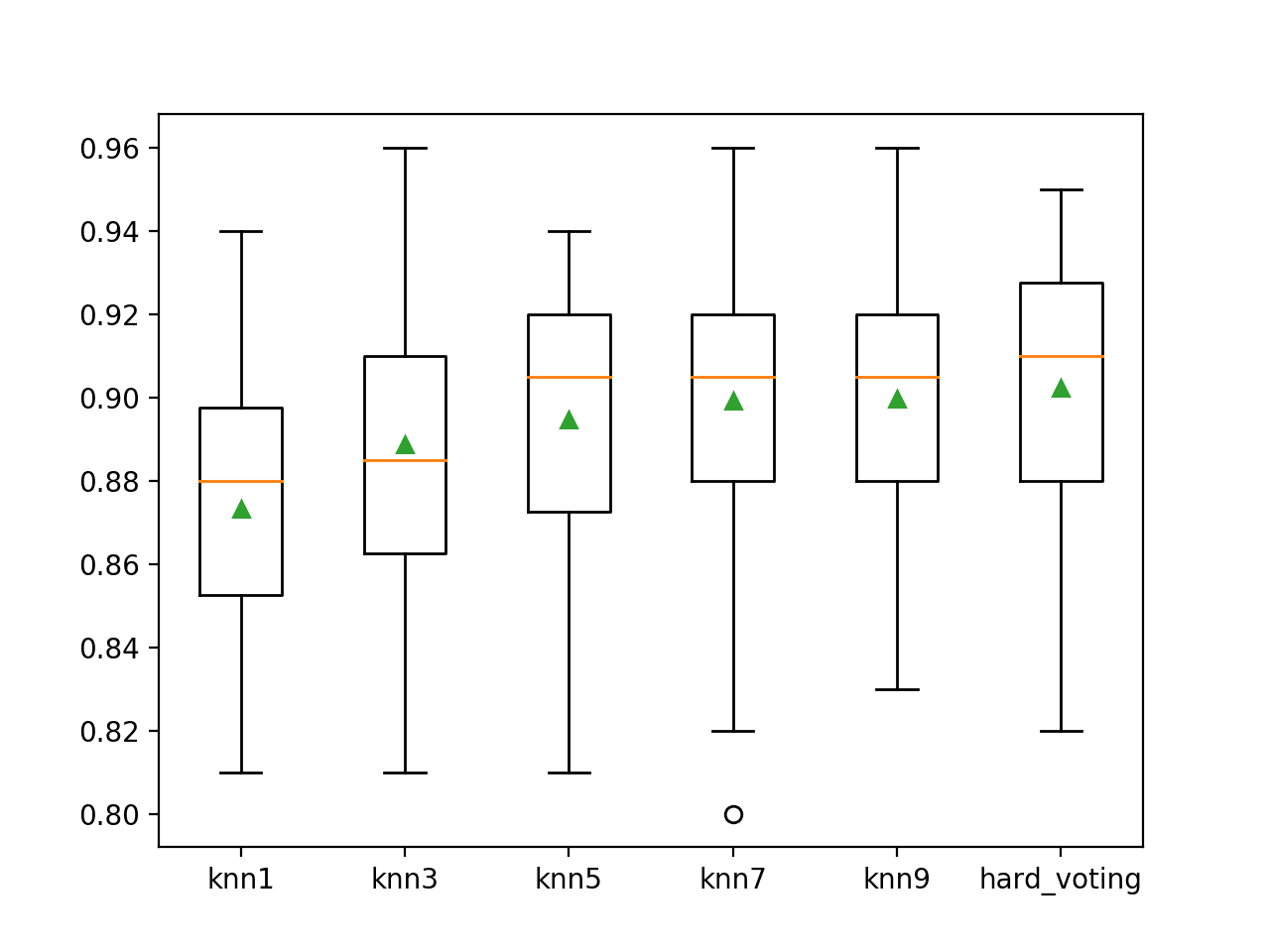
用于二元分类的硬投票集成模型与独立模型的箱须图
如果我们选择硬投票集成模型作为最终模型,我们可以像使用任何其他模型一样,在所有可用数据上拟合并使用它来对新数据进行预测。
首先,在所有可用数据上拟合硬投票集成模型,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用硬投票集成模型进行预测 from sklearn.datasets import make_classification from sklearn.ensemble import VotingClassifier from sklearn.neighbors import KNeighborsClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2) # 定义基础模型 models = list() models.append(('knn1', KNeighborsClassifier(n_neighbors=1))) models.append(('knn3', KNeighborsClassifier(n_neighbors=3))) models.append(('knn5', KNeighborsClassifier(n_neighbors=5))) models.append(('knn7', KNeighborsClassifier(n_neighbors=7))) models.append(('knn9', KNeighborsClassifier(n_neighbors=9))) # 定义硬投票集成模型 ensemble = VotingClassifier(estimators=models, voting='hard') # 在所有可用数据上拟合模型 ensemble.fit(X, y) # 对一个示例进行预测 data = [[5.88891819,2.64867662,-0.42728226,-1.24988856,-0.00822,-3.57895574,2.87938412,-1.55614691,-0.38168784,7.50285659,-1.16710354,-5.02492712,-0.46196105,-0.64539455,-1.71297469,0.25987852,-0.193401,-5.52022952,0.0364453,-1.960039]] yhat = ensemble.predict(data) print('Predicted Class: %d' % (yhat)) |
运行该示例,将硬投票集成模型拟合到所有数据,然后使用它对新数据进行预测,就像我们在应用程序中使用模型一样。
|
1 |
预测类别:1 |
分类软投票集成模型
我们可以使用 支持向量机 (SVM) 算法来演示软投票。
SVM 算法不原生预测概率,尽管可以通过将 SVC 类中的“probability”参数设置为“True”来配置它以预测类似概率的得分。
我们可以拟合 SVM 算法的五个不同版本,每个版本使用多项式核,并通过“degree”参数进行设置。我们将使用 1-5 的度。
我们的期望是,通过组合每个不同 SVM 模型预测的类成员资格概率得分,软投票集成模型将平均实现比任何独立使用的模型更好的预测性能。
首先,我们可以创建一个名为 get_voting() 的函数,该函数创建 SVM 模型并将它们组合成一个软投票集成模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 获取模型投票集成 def get_voting(): # 定义基础模型 models = list() models.append(('svm1', SVC(probability=True, kernel='poly', degree=1))) models.append(('svm2', SVC(probability=True, kernel='poly', degree=2))) models.append(('svm3', SVC(probability=True, kernel='poly', degree=3))) models.append(('svm4', SVC(probability=True, kernel='poly', degree=4))) models.append(('svm5', SVC(probability=True, kernel='poly', degree=5))) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='soft') return ensemble |
然后,我们可以创建一个模型列表进行评估,包括每个独立配置的 SVM 模型以及软投票集成模型。
这将有助于我们直接将每个独立配置的 SVM 模型与集成模型在分类准确率得分分布方面进行比较。下面的 get_models() 函数为我们创建了要评估的模型列表。
|
1 2 3 4 5 6 7 8 9 10 |
# 获取要评估的模型列表 定义 获取_模型(): models = dict() models['svm1'] = SVC(probability=True, kernel='poly', degree=1) models['svm2'] = SVC(probability=True, kernel='poly', degree=2) models['svm3'] = SVC(probability=True, kernel='poly', degree=3) models['svm4'] = SVC(probability=True, kernel='poly', degree=4) models['svm5'] = SVC(probability=True, kernel='poly', degree=5) models['soft_voting'] = get_voting() 返回 models |
我们可以像上一节一样,使用重复的 k 折交叉验证来评估和报告模型性能。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 将软投票集成模型与独立分类器进行比较 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.svm import SVC from sklearn.ensemble import VotingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2) 返回 X, y # 获取模型投票集成 def get_voting(): # 定义基础模型 models = list() models.append(('svm1', SVC(probability=True, kernel='poly', degree=1))) models.append(('svm2', SVC(probability=True, kernel='poly', degree=2))) models.append(('svm3', SVC(probability=True, kernel='poly', degree=3))) models.append(('svm4', SVC(probability=True, kernel='poly', degree=4))) models.append(('svm5', SVC(probability=True, kernel='poly', degree=5))) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='soft') return ensemble # 获取要评估的模型列表 定义 获取_模型(): models = dict() models['svm1'] = SVC(probability=True, kernel='poly', degree=1) models['svm2'] = SVC(probability=True, kernel='poly', degree=2) models['svm3'] = SVC(probability=True, kernel='poly', degree=3) models['svm4'] = SVC(probability=True, kernel='poly', degree=4) models['svm5'] = SVC(probability=True, kernel='poly', degree=5) models['soft_voting'] = get_voting() 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例后,将首先报告每个模型的平均和标准差准确率。
注意:由于算法或评估程序的随机性、数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
我们可以看到,软投票集成模型的分类准确率约为 92.4%,优于所有独立使用的模型。
|
1 2 3 4 5 6 |
>svm1 0.855 (0.035) >svm2 0.859 (0.034) >svm3 0.890 (0.035) >svm4 0.808 (0.037) >svm5 0.850 (0.037) >soft_voting 0.924 (0.028) |
然后,将创建一个箱须图来比较每个模型的准确率得分分布,使我们能够清楚地看到软投票集成模型平均而言优于所有独立使用的模型。
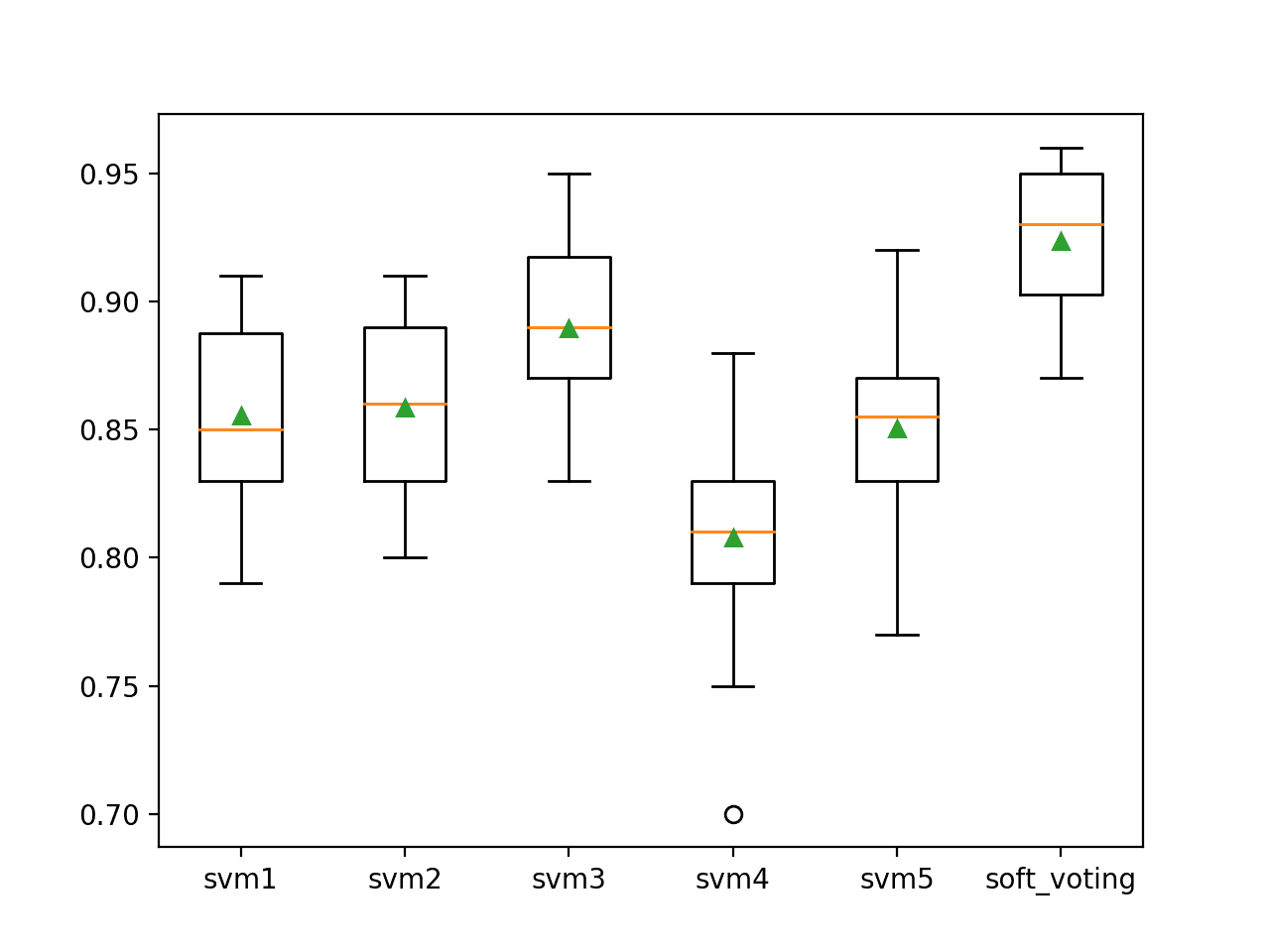
用于二元分类的软投票集成模型与独立模型的箱须图
如果我们选择软投票集成模型作为最终模型,我们可以像使用任何其他模型一样,在所有可用数据上拟合并使用它来对新数据进行预测。
首先,在所有可用数据上拟合软投票集成模型,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用软投票集成模型进行预测 from sklearn.datasets import make_classification from sklearn.ensemble import VotingClassifier from sklearn.svm import SVC # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2) # 定义基础模型 models = list() models.append(('svm1', SVC(probability=True, kernel='poly', degree=1))) models.append(('svm2', SVC(probability=True, kernel='poly', degree=2))) models.append(('svm3', SVC(probability=True, kernel='poly', degree=3))) models.append(('svm4', SVC(probability=True, kernel='poly', degree=4))) models.append(('svm5', SVC(probability=True, kernel='poly', degree=5))) # 定义软投票集成模型 ensemble = VotingClassifier(estimators=models, voting='soft') # 在所有可用数据上拟合模型 ensemble.fit(X, y) # 对一个示例进行预测 data = [[5.88891819,2.64867662,-0.42728226,-1.24988856,-0.00822,-3.57895574,2.87938412,-1.55614691,-0.38168784,7.50285659,-1.16710354,-5.02492712,-0.46196105,-0.64539455,-1.71297469,0.25987852,-0.193401,-5.52022952,0.0364453,-1.960039]] yhat = ensemble.predict(data) print('Predicted Class: %d' % (yhat)) |
运行该示例,将软投票集成模型拟合到所有数据,然后使用它对新数据进行预测,就像我们在应用程序中使用模型一样。
|
1 |
预测类别:1 |
回归投票集成模型
在本节中,我们将研究如何将投票应用于回归问题。
首先,我们可以使用 make_regression() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成回归问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试回归数据集 from sklearn.datasets import make_regression # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
我们可以通过决策树算法演示回归的集成投票,有时也称为分类与回归树 (CART) 算法。
我们可以拟合 CART 算法的五个不同版本,每个版本使用不同的决策树最大深度,通过“max_depth”参数设置。我们将使用 1-5 的深度。
我们的期望是,通过组合每个不同 CART 模型预测的值,投票集成模型将平均实现比任何独立使用的模型更好的预测性能。
首先,我们可以创建一个名为 get_voting() 的函数,该函数创建每个 CART 模型并将模型组合成一个投票集成模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 获取模型投票集成 def get_voting(): # 定义基础模型 models = list() models.append(('cart1', DecisionTreeRegressor(max_depth=1))) models.append(('cart2', DecisionTreeRegressor(max_depth=2))) models.append(('cart3', DecisionTreeRegressor(max_depth=3))) models.append(('cart4', DecisionTreeRegressor(max_depth=4))) models.append(('cart5', DecisionTreeRegressor(max_depth=5))) # 定义投票集成 ensemble = VotingRegressor(estimators=models) return ensemble |
然后,我们可以创建一个模型列表进行评估,包括每个独立配置的 CART 模型以及投票集成模型。
这将有助于我们直接将每个独立配置的 CART 模型与集成模型在错误得分分布方面进行比较。下面的 get_models() 函数为我们创建了要评估的模型列表。
|
1 2 3 4 5 6 7 8 9 10 |
# 获取要评估的模型列表 定义 获取_模型(): models = dict() models['cart1'] = DecisionTreeRegressor(max_depth=1) models['cart2'] = DecisionTreeRegressor(max_depth=2) models['cart3'] = DecisionTreeRegressor(max_depth=3) models['cart4'] = DecisionTreeRegressor(max_depth=4) models['cart5'] = DecisionTreeRegressor(max_depth=5) models['voting'] = get_voting() 返回 models |
我们可以像上一节一样,使用重复的 k 折交叉验证来评估和报告模型性能。
模型使用平均绝对误差 (MAE) 进行评估。Scikit-learn 将得分设为负数,以便可以最大化它。这意味着报告的 MAE 得分为负数,值越大越好,0 表示没有误差。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 将投票集成模型与每个独立模型进行比较以进行回归 from numpy import mean from numpy import std from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedKFold 来自 sklearn.tree 导入 DecisionTreeRegressor from sklearn.ensemble import VotingRegressor from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=1) 返回 X, y # 获取模型投票集成 def get_voting(): # 定义基础模型 models = list() models.append(('cart1', DecisionTreeRegressor(max_depth=1))) models.append(('cart2', DecisionTreeRegressor(max_depth=2))) models.append(('cart3', DecisionTreeRegressor(max_depth=3))) models.append(('cart4', DecisionTreeRegressor(max_depth=4))) models.append(('cart5', DecisionTreeRegressor(max_depth=5))) # 定义投票集成 ensemble = VotingRegressor(estimators=models) return ensemble # 获取要评估的模型列表 定义 获取_模型(): models = dict() models['cart1'] = DecisionTreeRegressor(max_depth=1) models['cart2'] = DecisionTreeRegressor(max_depth=2) models['cart3'] = DecisionTreeRegressor(max_depth=3) models['cart4'] = DecisionTreeRegressor(max_depth=4) models['cart5'] = DecisionTreeRegressor(max_depth=5) models['voting'] = get_voting() 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例后,将首先报告每个模型的平均和标准差准确率。
注意:由于算法或评估程序的随机性、数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
我们可以看到,投票集成模型的均方误差约为 -136.338,这比所有独立使用的模型都高(更好)。
|
1 2 3 4 5 6 |
>cart1 -161.519 (11.414) >cart2 -152.596 (11.271) >cart3 -142.378 (10.900) >cart4 -140.086 (12.469) >cart5 -137.641 (12.240) >voting -136.338 (11.242) |
然后,将创建一个箱须图来比较每个模型的负 MAE 得分分布,使我们能够清楚地看到投票集成模型平均而言优于所有独立使用的模型。
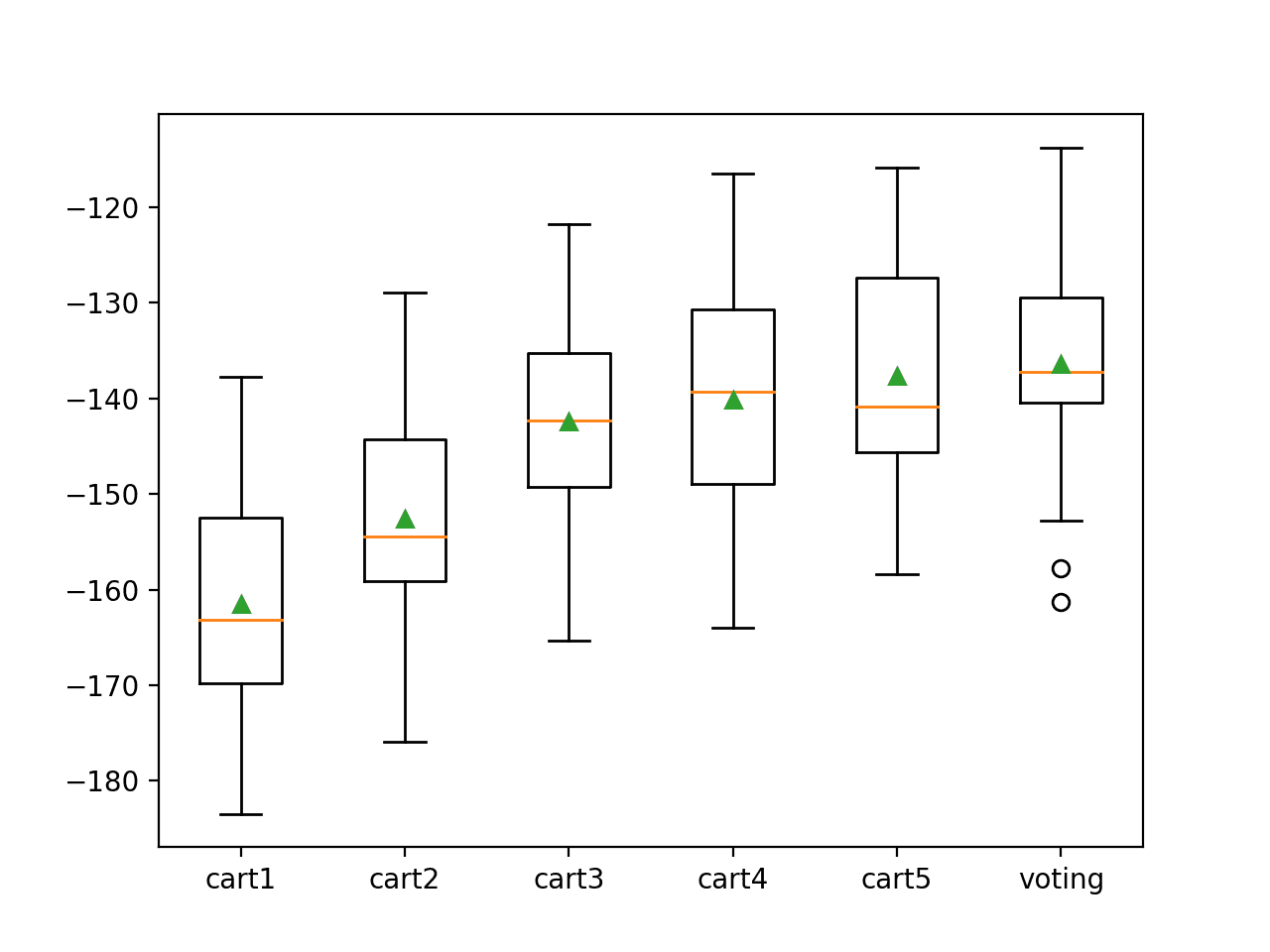
用于回归的投票集成模型与独立模型的箱须图
如果我们选择投票集成模型作为最终模型,我们可以像使用任何其他模型一样,在所有可用数据上拟合并使用它来对新数据进行预测。
首先,在所有可用数据上拟合投票集成模型,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用投票集成模型进行预测 from sklearn.datasets import make_regression 来自 sklearn.tree 导入 DecisionTreeRegressor from sklearn.ensemble import VotingRegressor # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=1) # 定义基础模型 models = list() models.append(('cart1', DecisionTreeRegressor(max_depth=1))) models.append(('cart2', DecisionTreeRegressor(max_depth=2))) models.append(('cart3', DecisionTreeRegressor(max_depth=3))) models.append(('cart4', DecisionTreeRegressor(max_depth=4))) models.append(('cart5', DecisionTreeRegressor(max_depth=5))) # 定义投票集成模型 ensemble = VotingRegressor(estimators=models) # 在所有可用数据上拟合模型 ensemble.fit(X, y) # 对一个示例进行预测 data = [[0.59332206,-0.56637507,1.34808718,-0.57054047,-0.72480487,1.05648449,0.77744852,0.07361796,0.88398267,2.02843157,1.01902732,0.11227799,0.94218853,0.26741783,0.91458143,-0.72759572,1.08842814,-0.61450942,-0.69387293,1.69169009]] yhat = ensemble.predict(data) print('Predicted Value: %.3f' % (yhat)) |
运行该示例,将投票集成模型拟合到所有数据,然后使用它对新数据进行预测,就像我们在应用程序中使用模型一样。
|
1 |
预测值:141.319 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
API
总结
在本教程中,您学习了如何为 Python 中的机器学习算法创建投票集成模型。
具体来说,你学到了:
- 投票集成模型涉及对分类模型的预测进行求和,或对回归模型的预测进行平均。
- 投票集成模型的工作原理、何时使用投票集成模型以及该方法的局限性。
- 如何为分类预测建模实现硬投票集成模型和软投票集成模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……






这篇帖子让我对如何在分类问题中进行投票有了清晰的认识,我正在处理这个问题。谢谢!
谢谢,很高兴听到这个!
嗨,jason
我收到了“无法导入名称‘VotingRegressor’”的错误。另外,你能告诉我一些关于如何研究用于预测的集成模型的信息吗?基本上,我使用 azure automl 得到了一个 VotingEnsemble 模型,但无法确定如何提供输入数据进行重新训练。由于我想自动化我的重新训练,我想自己查看代码。谢谢。
错误表明您需要更新 scikit-learn 库的版本。
Jason,我们如何在集成分类中使用加权投票?
您可以学习如何为模型加权,这被称为堆叠集成。
https://machinelearning.org.cn/stacking-ensemble-machine-learning-with-python/
在您看来:投票集成模型是否应被视为所有 ML 项目标准流程中的首选步骤?
此致!
不,每个项目都不同。
你好,Jason。我有一个问题,我该如何让多个基础模型学习不同的
相同的训练特征,然后进行集成?
每一个都可以是基于不同数据(相同数据的不同子集)拟合的不同模型类型的模型。
理解集成学习的最佳来源。继续保持好工作!!!
谢谢!
嘿Jason,在集成学习中,我们可以为不同的模型(基于不同的参数或完全不同的算法模型)使用相同的数据集(例如相同的数据集)吗??
是的!
您好,Jason。感谢您的帖子,我很喜欢。我有一个疑问;在回归问题中,我应该何时使用硬投票回归器与软投票回归器?
如果您的模型能给出良好的概率,例如逻辑回归或朴素贝叶斯,那么软投票可能比硬投票更好。
如有疑问,请两者都测试。
Jason您好,这个教程太棒了,非常感谢您。我有一个问题,请您指教。我正在处理皮肤病图像,我从每张图像中裁剪一些斑块,然后将它们输入到分类器中,以对每个斑块的严重程度进行分级。病灶的存在会影响严重程度。然后,我将所有斑块的结果组合起来对整个图像的严重程度进行分级。但问题是,病灶并非出现在所有斑块上,只出现在少数几个上,所以使用斑块投票集成可能没有帮助,因为大多数斑块没有病灶,因此它们的严重程度将是正常或轻微。那么在这种情况下,您会推荐哪种策略?非常感谢!
不客气。
我建议在整个输入图像上使用CNN模型,而不是在像素斑块上使用机器学习模型。
感谢您的回复,Jason。是的,这正是我正在尝试的另一种方法,但问题在于它需要高分辨率图像,这使得训练耗时,而且还需要注意力机制。我正在尝试您在这篇文章中提到的堆叠方法,通过使用SVM等模型从不同斑块获得的局部等级学习全局等级。谢谢!
您好!我遇到了以下问题。我正在尝试使用多输出分类(我试图预测3个值为输出)来进行堆叠和投票。但是Scikit learn目前还不支持多输出分类问题的投票和堆叠。有没有什么办法可以解决这种情况?
也许手动开发自己的模型?
也许使用备用模型或API?
也许扩展类以实现您期望的结果?
您好!感谢这个很棒的主题。
我有一个问题,如果我想在不同的数据源上进行测试(这些数据源是从同一来源提取的),并且我想知道哪个数据源以及它们的组合可以产生最佳性能。我可以使用这种技术吗?比如说我有6个数据集。我可以单独用这些数据集来拟合相同的SVM,然后我得到6个模型,以及它们的组合,即mod1+mod2,mod1+mod3,…,然后进行硬投票来评估性能吗?
投票不是比较模型,而是组合模型的预测。您明白了吗?
Jason您好。帖子写得很好。我读您的帖子已经有一段时间了。我需要您的建议。
我希望根据训练数据子集对测试数据的重要性来分配权重。因此,我尝试了投票集成,其中模型相同,但在不同的子集上进行训练。我使用了硬投票,但结果并不理想。
第二种情况是,如果我使用不同的模型进行投票,那么是否有办法为数据分配权重。我已经尝试过使用sample_weights。
我正在使用CNN。
谢谢!
我不认为投票能满足您的需求。我建议您考虑为单个模型使用样本权重。
感谢您的及时回复。我忘记提我的数据集是平衡的。我已经尝试过为训练数据使用sample_weights。Sample_weights基于样本的重要性。我现在面临的问题是,在evaluate函数中应该传递什么作为样本权重。在我看来,训练数据的样本权重不应该被传递,因为训练和测试数据的尺寸不同。请分享您的看法。
再次感谢您的建议和时间:)
抱歉,我不明白您遇到的问题,我认为我不是最适合提供帮助的人。
也许您可以在Stack Overflow上发帖提问。
集成是否可以使用多种算法?我看到您在一个集成中使用了1种算法,即仅使用KNN,仅使用SVM等。我们可以在一个集成中使用KNN、SVM和CART等吗?
是的。您可以在集成中使用任何您喜欢的算法。
感谢您提供的精彩教程,我很高兴地告诉您,您的书籍《Develop Deep Learning Models for Natural Language in Python》已被纳入我博士的文本挖掘课程的阅读清单。
谢谢,很高兴听到这个!
您好。感谢您提供这个有用的教程
在投票集成中,例如Bagging,模型是在训练数据集的子集上训练的吗?
在投票中,每个模型都用所有数据进行拟合。
在Bagging中,每个模型都用数据的子集进行拟合。
您好,Jason先生
请教我一些问题
1-在多类别分类器的情况下,如果所有估计器的结果都不同,投票结果是什么?
例如:第一个估计器的输出是类别 1
第二个估计器的输出是类别 2
第三个估计器的输出是类别 3
2-在软投票中我知道:如何找到每个估计器的概率?它如何与多类别分类一起工作?
3-我们知道随机森林也使用投票技术,那么在多类别分类的情况下它使用哪种类型的投票?
4-我是否可以将随机森林作为投票分类器的估计器?这是否可行?
谢谢
我认为它会选择四舍五入的平均值(1 + 2 + 3)/ 3 = 2
您可以使用model.predict_proba()来获取给定模型/子模型中属于某个类别的概率。
随机森林使用四舍五入的平均值。
您可以将随机森林作为投票分类器,但我们通常称之为一种Bagging——因为这方面对结果更重要。
非常感谢,您帮助了我很多。
不客气!
请教,如果我有偶数个估计器,例如4个估计器,并且输出标签是文本,如下所示 [class2,class3, class2,class3],那么硬投票分类器的输出是什么?
可能是class2,例如四舍五入的平均值的向下取整。
您可以测试一下看看。
我检查过了,有时会按照您提到的程序给出结果,但其他时候它是不稳定的,特别是当输出完全不同时,例如[class2,class3, class4,class1],它给出class1,并且偶然class1是正确的类别。所以很遗憾,我至今仍不了解它是如何工作的。
根据文档,平局是通过对标签进行升序排序并选择第一个标签来解决的。
来自这里
https://scikit-learn.cn/stable/modules/ensemble.html#voting-classifier
好的,现在非常清楚了,非常感谢您,致以我最美好的祝愿
不客气。
您好Jason,很棒的文章,有个小问题,您提到使用不同的算法应用于同一组输入特征。如果我们想要一个投票集成,其中每个模型可以相同也可以不同,但很可能使用不同的输入特征,例如
泰坦尼克号
算法1输入船舱甲板、性别、年龄,使用GBM
算法2输入已婚、登船地点,使用XGBoost
等等
这可以使用sklearn的投票集成库或其他您知道的库来实现吗?
谢谢
是的,请看这个例子
https://machinelearning.org.cn/feature-selection-subspace-ensemble-in-python/
请忽略拼写错误
不客气。
非常感谢您提供这个教程,先生。我的代码有以下情况
ensemble = VotingClassifier(ensembles)
results_vc = cross_val_score(ensemble, X_train, y_train, cv=kfold)
print(results_vc.mean())
result_vc.mean()给出:0.8838
但是当我拟合和预测时,我得到的f1-score是0.0560。
这好吗,不好吗?我该如何解决这个问题?根据我的数据,它非常不平衡。一个类别比另一个类别大7倍。
这有助于您确定模型的性能是否良好
https://machinelearning.org.cn/naive-classifiers-imbalanced-classification-metrics/
这些建议可能会有帮助
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
嘿Jason,我正试图在我的数据集(70,15)上使用这个。我想知道您这里的y代表什么。数据集有1000行,看起来是0和1的二元分类。那么我如何使用我的数据集来表示y的类似格式呢?我尝试思考了一下,不认为这些是聚类标识符,对吧?那么y的二元/多类表示是什么?
这是代码,显然我不能使用我拥有的y,因为它是一个连续的变量,但当然我实现了它来看会发生什么,并为了举例说明
y = X_train_MinMax[:,1]
print(X_train_MinMax.shape, y.shape)
#(70,15)(70, )
# 获取模型投票集成
def get_voting()
# 定义基础模型
models = list()
models.append((‘knn1’, KNeighborsClassifier(n_neighbors=1)))
models.append((‘knn3’, KNeighborsClassifier(n_neighbors=3)))
models.append((‘knn5’, KNeighborsClassifier(n_neighbors=5)))
models.append((‘knn7’, KNeighborsClassifier(n_neighbors=7)))
models.append((‘knn9′, KNeighborsClassifier(n_neighbors=9)))
# 定义投票集成模型
ensemble = VotingClassifier(estimators=models, voting=’hard’)
return ensemble
# 获取要评估的模型列表
def get_models()
models = dict()
models[‘knn1’] = KNeighborsClassifier(n_neighbors=1)
models[‘knn3’] = KNeighborsClassifier(n_neighbors=3)
models[‘knn5’] = KNeighborsClassifier(n_neighbors=5)
models[‘knn7’] = KNeighborsClassifier(n_neighbors=7)
models[‘knn9’] = KNeighborsClassifier(n_neighbors=9)
models[‘hard_voting’] = get_voting()
return models
# 使用交叉验证评估给定模型
def evaluate_model(model, X_train_MinMax, y)
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X_train_MinMax, y, scoring=’accuracy’, cv=cv, n_jobs=-1, error_score=’raise’)
return scores
# 获取要评估的模型
models = get_models()
# 评估模型并存储结果
results, names = list(), list()
for name, model in models.items()
scores = evaluate_model(model, X_train_MinMax, y)
results.append(scores)
names.append(name)
print(‘>%s %.3f (%.3f)’ % (name, mean(scores), std(scores)))
# 绘制模型性能以供比较
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
这会有帮助
https://machinelearning.org.cn/faq/single-faq/what-are-x-and-y-in-machine-learning
嗨,杰森,
硬投票分类器仅适用于二元分类或多阶段分类(5个阶段的类别)。
为您的数据集使用最有效的方法。
非常感谢您提供如此出色的教程,先生
不客气。
您好Jason。您能告诉我投票如何提高我们的准确率得分的后端现象吗?我使用了2个模型,分别是MLP和ELM,有4个标签。
假设我得到了这些准确率
Mlp = 92
Elm = 94
Ensemble voting = 97
那么问题是。集成投票如何提高我们的准确率?它是如何做到的?
有时可以帮助,有时不行。原因——这取决于模型和数据。尝试一下,看看效果。
感谢这篇帖子。
我有一个问题。我将Adaboost、DT和Bagging用作投票分类器中的分类器1、分类器2和分类器3,我使用了硬投票。投票分类器获得了93.14%的准确率,这比我之前DT给我的92.87%要好。在另一个集成方法(投票分类器)中使用boosting和bagging是否合乎逻辑?
当然。可以尝试一下看看。
嗨
感谢您提供有用的内容
我有一个问题。如何将机器学习(SVM,NB, KNN)和词典(NRC)结合起来使用多数投票?
请指教。
抱歉,我不知道“词典(NRC)”是什么。
谢谢!
如何为3个预训练的语言模型应用多数投票?
难道3个投票者总是能得到多数票吗?
我可以处理3、4、5个及以上,但如何应用呢?
简单地统计结果就可以了。这就是为什么称之为投票。
嗨,Jason,
感谢您提供的精彩帖子。我有一个关于软投票的问题。如何校准那些不直接预测类别概率的模型,例如KNN,以便与软投票一起用于集成?
我认为我们不是一次校准多个模型,而是对每个模型进行单独的微调,使每个模型都做得好。如果每个模型都做得好,那么集成也会做得好。
你好 Adrian,
为了确保我正确理解,您的意思是,首先,我应该单独调整和校准每个算法,并找到每个算法的最佳参数。然后将所有校准好的模型放入投票分类器,并根据为每个算法找到的最佳参数来训练模型?
正确。但如果用于校准的数据与最终模型的数据相同,您可以保存校准后的模型,并跳过sklearn中的投票分类器函数,然后在循环中自己构建投票分类器。当然,使用VotingClassifier函数重新训练模型更简单。
您好,Jason,
感谢这篇教程。
我有一个如下的查询
假设我有两个模型(Model1和Model2),它们分别在不同的图像数据集(如Data1和Data2)上训练。我可以在voting-classifier函数中使用这些模型吗?
没有什么能阻止您这样做。但这对您的问题有意义吗?
嗨Adrian Tam
如何使用极限学习机实现投票集成?
谢谢你
嗨Abdou……您可能会发现以下资源很有趣
https://analyticsindiamag.com/a-beginners-guide-to-extreme-learning-machine/
亲爱的 Jason,
亲爱的 Adrian,
请允许我提问。是否存在限制将某些机器学习分类器组合成投票元学习器的理论背景?
例如,我为每个模型使用了Lasso惩罚的逻辑回归、Ridge惩罚的逻辑回归、决策树、随机森林、AdaBoost和XGboost,每个模型都有不同的准确率结果。
将决策树模型和随机森林模型组合成一个软投票分类器(或加权投票分类器)是否有意义?(考虑到随机森林本身已经是由多个决策树组合和投票组成的)。将XGBoost和Adaboost组合成一个投票分类器是否有意义?
我知道我们可以将任意多的SVM、KNN、ANN与它们的各种超参数组合到投票分类器中。这是否也适用于基于集成的方法?(考虑到每种集成方法在其算法内部已经实现了投票机制)。
感谢您的耐心。抱歉提出这个初级问题。和平。
亲爱的 Jason,
亲爱的 Adrian,
请允许我提问。是否存在限制将某些机器学习分类器组合成投票元学习器的理论背景?
例如,我为每个模型使用了Lasso惩罚的逻辑回归、弹性网络惩罚的逻辑回归、决策树、随机森林、AdaBoost和XGboost,并使用分层k折交叉验证,每个模型都有不同的准确率结果。
将决策树模型和随机森林模型组合成一个软投票分类器(或加权投票分类器)是否有意义?(考虑到随机森林本身已经是由多个决策树组合和投票组成的)。
将XGBoost和Adaboost组合成一个投票分类器是否有意义?
将带有Lasso惩罚的逻辑回归和其他带有弹性网络惩罚的逻辑回归组合成一个投票分类器是否有意义?(考虑到弹性网络本身就是Lasso和Ridge的组合
我知道我们可以将任意多的SVM、KNN和ANN与它们的各种超参数组合到投票分类器中。这是否也适用于基于集成的方法?(考虑到每种集成方法在其算法内部已经实现了投票机制)。
我知道我们可以自由地处理我们的数据,我相信组合相似的模型将有助于缩小交叉验证循环的累积平均值的标准差。但是,但是,这在理论上是可接受的吗?
感谢您的耐心。抱歉提出这个初级问题。祝大家一切顺利。
嗨,Jason,
感谢您提供有用的内容
我有一个问题。如何将机器学习(SVM,NB, RF)和深度学习(ANN)结合起来使用多数投票?
请指教。
嗨Sarvesh……以下资源可能对您有益
https://machinelearning.org.cn/ensemble-machine-learning-with-python-7-day-mini-course/
亲爱的 Jason,
亲爱的 Adrian,
亲爱的 James,
请允许我提问。是否存在限制将某些机器学习分类器组合成投票分类器的理论背景?
例如,我使用几种模型构建了X和y:Lasso惩罚的逻辑回归、弹性网络惩罚的逻辑回归、决策树、随机森林、AdaBoost和XGboost,并使用分层k折交叉验证,每个模型都有不同的准确率结果。
将决策树模型和随机森林模型组合成一个软投票分类器(或加权投票分类器)是否有意义?(考虑到随机森林本身已经是由多个决策树组合和投票组成的)。
将XGBoost和Adaboost组合成一个投票分类器是否有意义?
将带有Lasso惩罚的逻辑回归和其他带有弹性网络惩罚的逻辑回归组合成一个投票分类器是否有意义?(考虑到弹性网络本身就是Lasso和Ridge的组合
我知道我们可以将任意多的SVM、KNN和ANN与它们的各种超参数组合到投票分类器中。这是否也适用于基于集成的方法?(考虑到每种集成方法在其算法内部已经实现了投票机制)。
我知道我们可以自由地处理我们的数据,我相信组合相似的模型将有助于缩小交叉验证循环的累积平均值的标准差。但是,但是,这在理论上是可接受的吗?
感谢您的耐心。抱歉提出这个初级问题。祝大家一切顺利。
感谢您的信息,非常有启发性。我想回答几个问题。
1.除了投票,还有什么方法可以采用来组合算法以创建集成学习器?
2.投票是否等同于堆叠?
3.投票集成与混合(blending)有什么区别?
等待您的快速回复。
谢谢
艾萨克
嗨Isaac……以下资源可能对您有益
https://towardsdatascience.com/ensemble-learning-stacking-blending-voting-b37737c4f483
您好,亲爱的Jason博士
我想训练一些模型(可以是相同类型或不同类型),使用不同的训练数据(但类别数量相同),并在验证数据上对训练好的模型进行投票。我该如何在python中做到这一点?
嗨Ali……以下资源可能对您在训练新数据模型方面有益。
https://machinelearning.org.cn/update-neural-network-models-with-more-data/