过去,收集数据是一项繁琐且成本高昂的工作。机器学习项目离不开数据。幸运的是,如今网络上有大量数据可供我们使用。我们可以从网上复制数据来创建我们的数据集。我们可以手动下载文件并将其保存到磁盘。但通过自动化数据采集,我们可以更有效地做到这一点。Python中有多种工具可以帮助实现自动化。
完成本教程后,你将学到:
- 如何使用requests库通过HTTP读取在线数据
- 如何使用pandas读取网页表格
- 如何使用Selenium模拟浏览器操作
启动您的项目,阅读我的新书《Python for Machine Learning》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧!
Python中的Web爬虫
照片由 Ray Bilcliff 拍摄。保留部分权利。
概述
本教程分为三个部分;它们是:
- 使用requests库
- 使用pandas在网上读取表格
- 使用Selenium读取动态内容
使用Requests库
当我们谈论编写Python程序从网络读取数据时,不可避免地会涉及到 requests 库。您需要安装它(以及稍后将介绍的BeautifulSoup和lxml)。
|
1 |
pip install requests beautifulsoup4 lxml |
它为您提供了一个可以轻松与网络交互的接口。
最简单的用例是从URL读取网页。
|
1 2 3 4 5 6 7 |
import requests # 纽约的经纬度 URL = "https://weather.com/weather/today/l/40.75,-73.98" resp = requests.get(URL) print(resp.status_code) print(resp.text) |
|
1 2 3 4 5 |
200 <!doctype html><html dir="ltr" lang="en-US"><head> <meta data-react-helmet="true" charset="utf-8"/><meta data-react-helmet="true" name="viewport" content="width=device-width, initial-scale=1, viewport-fit=cover"/> ... |
如果您熟悉HTTP,您可能还记得状态码200表示请求已成功满足。然后我们可以读取响应。在上面,我们读取了文本响应并获取了网页的HTML。如果数据是CSV或其他文本数据,我们可以在响应对象的text属性中获取。例如,这是我们如何从美联储经济数据中读取CSV
|
1 2 3 4 5 6 7 8 9 10 11 |
import io import pandas as pd import requests URL = "https://fred.stlouisfed.org/graph/fredgraph.csv?id=T10YIE&cosd=2017-04-14&coed=2022-04-14" resp = requests.get(URL) if resp.status_code == 200: csvtext = resp.text csvbuffer = io.StringIO(csvtext) df = pd.read_csv(csvbuffer) print(df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
日期 T10YIE 0 2017-04-17 1.88 1 2017-04-18 1.85 2 2017-04-19 1.85 3 2017-04-20 1.85 4 2017-04-21 1.84 ... ... ... 1299 2022-04-08 2.87 1300 2022-04-11 2.91 1301 2022-04-12 2.86 1302 2022-04-13 2.8 1303 2022-04-14 2.89 [1304 行 x 2 列] |
如果数据是JSON格式,我们可以将其读取为文本,或者让requests为您解码。例如,以下是将一些数据从GitHub中提取为JSON格式并将其转换为Python字典的方法:
|
1 2 3 4 5 6 7 |
import requests URL = "https://api.github.com/users/jbrownlee" resp = requests.get(URL) if resp.status_code == 200: data = resp.json() print(data) |
|
1 2 3 4 5 6 7 8 9 10 11 |
{'login': 'jbrownlee', 'id': 12891, 'node_id': 'MDQ6VXNlcjEyODkx', 'avatar_url': 'https://avatars.githubusercontent.com/u/12891?v=4', 'gravatar_id': '', 'url': 'https://api.github.com/users/jbrownlee', 'html_url': 'https://github.com/jbrownlee', ... 'company': 'Machine Learning Mastery', 'blog': 'https://machinelearning.org.cn', 'location': None, 'email': None, 'hireable': None, 'bio': 'Making developers awesome at machine learning. Making developers awesome at machine learning.', 'twitter_username': None, 'public_repos': 5, 'public_gists': 0, 'followers': 1752, 'following': 0, 'created_at': '2008-06-07T02:20:58Z', 'updated_at': '2022-02-22T19:56:27Z' } |
但是,如果URL提供的是二进制数据,例如ZIP文件或JPEG图像,您需要获取content属性,因为这将是二进制数据。例如,这是我们如何下载一张图片(维基百科的标志):
|
1 2 3 4 5 6 7 |
import requests URL = "https://en.wikipedia.org/static/images/project-logos/enwiki.png" wikilogo = requests.get(URL) if wikilogo.status_code == 200: with open("enwiki.png", "wb") as fp: fp.write(wikilogo.content) |
既然我们已经获取了网页,我们应该如何提取数据呢?这已经超出了requests库的功能,但我们可以使用另一个库来帮忙。有两种方法,取决于我们想要如何指定数据。
第一种方法是将HTML视为一种XML文档,并使用XPath语言提取元素。在这种情况下,我们可以利用lxml库来首先创建一个文档对象模型(DOM),然后通过XPath进行搜索。
|
1 2 3 4 5 6 7 8 |
... from lxml import etree # 从HTML文本创建DOM dom = etree.HTML(resp.text) # 搜索温度元素并获取内容 elements = dom.xpath("//span[@data-testid='TemperatureValue' and contains(@class,'CurrentConditions')]") print(elements[0].text) |
|
1 |
61° |
XPath是指定如何查找元素的字符串。lxml对象提供了一个xpath()函数来在DOM中搜索匹配XPath字符串的元素,可能会有多个匹配。上面的XPath表示在任何地方查找一个HTML元素,其<span>标签具有data-testid属性且值为“TemperatureValue”,并且class属性以“CurrentConditions”开头。我们可以从浏览器的开发者工具(例如,下面的Chrome截图)中通过检查HTML源代码来学习这一点。
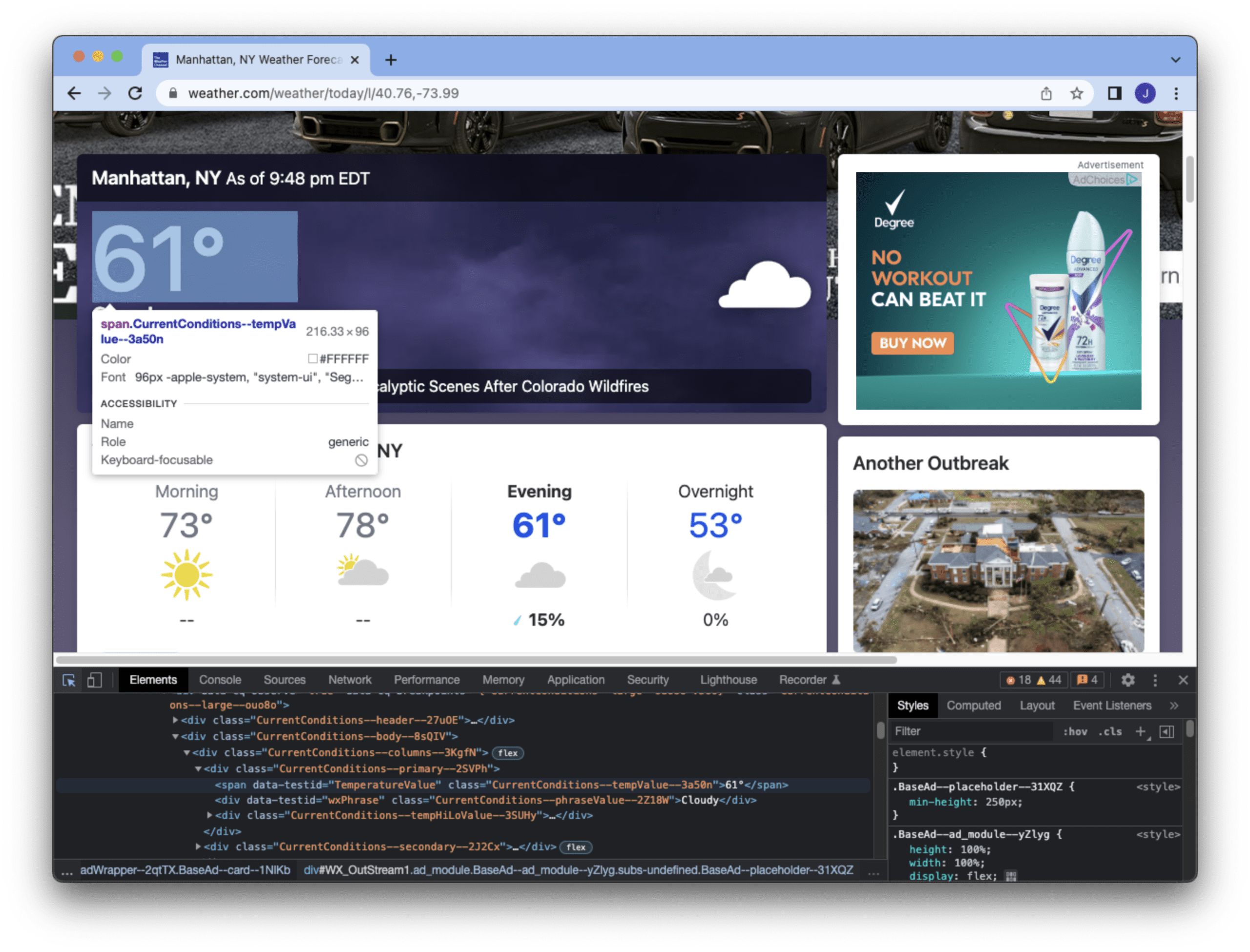
这个例子是为了查找纽约市的温度,该温度由该网页的特定元素提供。我们知道XPath匹配的第一个元素是我们需要的,我们可以读取<span>标签内的文本。
另一种方法是使用CSS选择器在HTML文档上进行操作,我们可以利用BeautifulSoup库。
|
1 2 3 4 5 6 |
... from bs4 import BeautifulSoup soup = BeautifulSoup(resp.text, "lxml") elements = soup.select('span[data-testid="TemperatureValue"][class^="CurrentConditions"]') print(elements[0].text) |
|
1 |
61° |
在上面,我们首先将HTML文本传递给BeautifulSoup。BeautifulSoup支持各种HTML解析器,它们各有不同的功能。在上面,我们使用了BeautifulSoup推荐的lxml库作为解析器(它通常也是最快的)。CSS选择器是一种不同的迷你语言,与XPath相比各有利弊。上面的选择器与我们在上一个示例中使用的XPath相同。因此,我们可以从第一个匹配的元素中获取相同的温度。
以下是根据网络实时信息打印纽约当前温度的完整代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import requests from lxml import etree # 读取纽约的温度 URL = "https://weather.com/weather/today/l/40.75,-73.98" resp = requests.get(URL) if resp.status_code == 200: # 使用lxml dom = etree.HTML(resp.text) elements = dom.xpath("//span[@data-testid='TemperatureValue' and contains(@class,'CurrentConditions')]") print(elements[0].text) # 使用BeautifulSoup soup = BeautifulSoup(resp.text, "lxml") elements = soup.select('span[data-testid="TemperatureValue"][class^="CurrentConditions"]') print(elements[0].text) |
您可以想象,通过定期运行此脚本,您可以收集温度的时间序列数据。同样,我们可以从各种网站自动收集数据。这就是我们如何为机器学习项目获取数据。
使用Pandas读取网页表格
很多时候,网页会使用表格来承载数据。如果页面足够简单,我们甚至可以跳过检查它来找出XPath或CSS选择器,并使用pandas一次性获取页面上的所有表格。这很容易做到,只需一行代码即可完成。
|
1 2 3 4 |
import pandas as pd tables = pd.read_html("https://www.federalreserve.gov/releases/h15/") print(tables) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
[ 工具 2022年4月7日 2022年4月8日 2022年4月11日 2022年4月12日 2022年4月13日 0 联邦基金(有效) 1 2 3 0.33 0.33 0.33 0.33 0.33 1 商业票据 3 4 5 6 NaN NaN NaN NaN NaN 2 非金融 NaN NaN NaN NaN NaN 3 1个月 0.30 0.34 0.36 0.39 0.39 4 2个月 n.a. 0.48 n.a. n.a. n.a. 5 3个月 n.a. n.a. n.a. 0.78 0.78 6 金融 NaN NaN NaN NaN NaN 7 1个月 0.49 0.45 0.46 0.39 0.46 8 2个月 n.a. n.a. 0.60 0.71 n.a. 9 3个月 0.85 0.81 0.75 n.a. 0.86 10 银行优惠贷款 2 3 7 3.50 3.50 3.50 3.50 3.50 11 贴现窗一级信贷 2 8 0.50 0.50 0.50 0.50 0.50 12 美国政府证券 NaN NaN NaN NaN NaN 13 财政部票据(二级市场) 3 4 NaN NaN NaN NaN NaN 14 4周 0.21 0.20 0.21 0.19 0.23 15 3个月 0.68 0.69 0.78 0.74 0.75 16 6个月 1.12 1.16 1.22 1.18 1.17 17 1年 1.69 1.72 1.75 1.67 1.67 18 财政部近期到期证券 NaN NaN NaN NaN NaN 19 名义9 NaN NaN NaN NaN NaN 20 1个月 0.21 0.20 0.22 0.21 0.26 21 3个月 0.68 0.70 0.77 0.74 0.75 22 6个月 1.15 1.19 1.23 1.20 1.20 23 1年 1.78 1.81 1.85 1.77 1.78 24 2年 2.47 2.53 2.50 2.39 2.37 25 3年 2.66 2.73 2.73 2.58 2.57 26 5年 2.70 2.76 2.79 2.66 2.66 27 7年 2.73 2.79 2.84 2.73 2.71 28 10年 2.66 2.72 2.79 2.72 2.70 29 20年 2.87 2.94 3.02 2.99 2.97 30 30年 2.69 2.76 2.84 2.82 2.81 31 通胀挂钩10 NaN NaN NaN NaN NaN 32 5年 -0.56 -0.57 -0.58 -0.65 -0.59 33 7年 -0.34 -0.33 -0.32 -0.36 -0.31 34 10年 -0.16 -0.15 -0.12 -0.14 -0.10 35 20年 0.09 0.11 0.15 0.15 0.18 36 30年 0.21 0.23 0.27 0.28 0.30 37 通胀挂钩长期平均11 0.23 0.26 0.30 0.30 0.33, 0 1 0 n.a. 不可用.] |
Pandas中的read_html()函数读取URL并查找页面上的所有表格。每个表格都会被转换为一个pandas DataFrame,然后将它们全部返回在一个列表中。在此示例中,我们正在读取美联储的各种利率,碰巧这个页面只有一个表格。表格列由pandas自动识别。
很有可能并非所有表格都是我们感兴趣的。有时,网页会仅使用表格来格式化页面,但pandas可能不够智能,无法分辨。因此,我们需要测试并筛选read_html()函数返回的结果。
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用Selenium读取动态内容
现代网页的很大一部分都充满了JavaScript。这提供了更fancy的体验,但却成为了程序提取数据的障碍。一个例子是雅虎的主页,如果我们只是加载页面并查找所有新闻标题,其数量会远少于我们在浏览器中看到的数量。
|
1 2 3 4 5 6 7 8 9 10 11 |
import requests # 读取雅虎主页 URL = "https://www.yahoo.com/" resp = requests.get(URL) dom = etree.HTML(resp.text) # 打印新闻标题 elements = dom.xpath("//h3/a[u[@class='StretchedBox']]") for elem in elements: print(etree.tostring(elem, method="text", encoding="unicode")) |
这是因为像这样的网页依赖于JavaScript来填充内容。像AngularJS或React这样著名的Web框架支持这一类。Python库,如requests,不理解JavaScript。因此,您看到的结果会不同。如果您要获取的网页数据是其中之一,您可以研究JavaScript是如何被调用的,并在您的程序中模仿浏览器的行为。但这可能太繁琐,难以实现。
另一种方法是让真实的浏览器读取网页,而不是使用requests。这就是Selenium可以做到的。在使用它之前,我们需要安装库:
|
1 |
pip install selenium |
但Selenium只是一个控制浏览器的框架。您需要在计算机上安装浏览器以及连接Selenium到浏览器的驱动程序。如果您打算使用Chrome,您还需要下载并安装ChromeDriver。您需要将驱动程序放在可执行路径中,以便Selenium可以像普通命令一样调用它。例如,在Linux中,您只需要从下载的ZIP文件中获取chromedriver可执行文件,并将其放在/usr/local/bin中。
同样,如果您使用的是Firefox,您需要GeckoDriver。有关设置Selenium的更多详细信息,您应该参考其文档。
之后,您可以使用Python脚本来控制浏览器行为。例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import time from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By # 以无头模式启动Chrome浏览器 options = webdriver.ChromeOptions() options.add_argument("headless") browser = webdriver.Chrome(options=options) # 加载网页 browser.get("https://www.yahoo.com") # 网络传输需要时间。等待页面完全加载 def is_ready(browser): return browser.execute_script(r""" return document.readyState === 'complete' """) WebDriverWait(browser, 30).until(is_ready) # 滚动到页面底部以触发JavaScript操作 browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(1) WebDriverWait(browser, 30).until(is_ready) # 搜索新闻标题并打印 elements = browser.find_elements(By.XPATH, "//h3/a[u[@class='StretchedBox']]") for elem in elements: print(elem.text) # 完成后关闭浏览器 browser.close() |
上面的代码工作原理如下。我们首先以无头模式启动浏览器,这意味着我们要求Chrome启动但不显示在屏幕上。如果我们要远程运行脚本,这一点很重要,因为可能没有GUI支持。请注意,每个浏览器开发方式不同,因此我们使用的选项语法特定于Chrome。如果我们使用Firefox,代码将是这样的:
|
1 2 3 |
options = webdriver.FirefoxOptions() options.set_headless() browser = webdriver.Firefox(firefox_options=options) |
启动浏览器后,我们让它加载一个URL。但由于网络传输页面需要时间,并且浏览器需要时间来渲染它,所以在进行下一步操作之前,我们应该等待浏览器准备就绪。我们使用JavaScript来检测浏览器是否已完成渲染。我们让Selenium为我们运行一段JavaScript代码,并通过execute_script()函数告诉我们结果。我们利用Selenium的WebDriverWait工具来运行它,直到成功或直到30秒超时。页面加载后,我们滚动到页面底部,以便触发JavaScript加载更多内容。然后,我们无条件等待一秒钟,以确保浏览器触发了JavaScript,然后再次等待页面准备就绪。之后,我们可以使用XPath(或选择器)提取新闻标题元素。由于浏览器是一个外部程序,我们负责在脚本中关闭它。
Selenium的使用在多个方面与requests库不同。首先,您的Python代码中从不直接包含网页内容。相反,您在需要时引用浏览器的内容。因此,find_elements()函数返回的Web元素是指外部浏览器中的对象,所以我们必须在完成使用它们之前不要关闭浏览器。其次,所有操作都应基于浏览器交互,而不是网络请求。因此,您需要通过模拟键盘和鼠标移动来控制浏览器。但作为回报,您拥有了支持JavaScript的完整功能浏览器。例如,您可以使用JavaScript来检查页面上元素的大小和位置,这些信息只有在HTML元素渲染后才能知道。
Selenium框架提供了许多我们可以涵盖的功能。它很强大,但由于它连接到浏览器,使用起来比requests库要求更高,而且速度也慢得多。通常,这是从网络上采集信息的最后手段。
进一步阅读
Python中另一个著名的网络爬虫库是我们上面没有介绍的Scrapy。它就像将requests库与BeautifulSoup结合在一起。Web协议很复杂。有时我们需要管理Web Cookie或使用POST方法向请求提供额外数据。所有这些都可以使用requests库通过不同的函数或附加参数来完成。以下是一些供您深入研究的资源:
文章
API文档
书籍
- Python Web Scraping,第二版,作者:Katharine Jarmul和Richard Lawson
- Web Scraping with Python,第二版,作者:Ryan Mitchell
- Learning Scrapy,作者:Dimitrios Kouzis-Loukas
- Python Testing with Selenium,作者:Sujay Raghavendra
- Hands-On Web Scraping with Python,作者:Anish Chapagain
总结
在本教程中,您了解了可用于从网络获取内容的工具。
具体来说,你学到了:
- 如何使用requests库发送HTTP请求并从其响应中提取数据
- 如何构建HTML的文档对象模型,以便我们可以找到网页上的某些特定信息
- 如何使用pandas快速轻松地读取网页上的表格
- 如何使用Selenium控制浏览器来处理网页上的动态内容
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...






这里有一个拼写错误。
df = ppd.read_csv(csvbuffer)
“ppd”应该是“pd”
感谢您的反馈 YF!
感谢您提供如此详细且有用的页面。有一件事,这不算是网络抓取吗?据我所知,网络爬虫是查找或发现网络上的URL或链接。
嗨 Selda…是的,这种技术通常被称为网络抓取。
错误
df = ppd.read_csv(csvbuffer)
正确
df = pd.read_csv(csvbuffer)
嗨 Luis…感谢您的反馈!
很棒且全面的文章。它有助于理解不同的方法。然而,由于没有标准的网站开发模板,要拥有一个通用的工具来从网页收集数据确实很困难。您对此有什么想法吗?
嗨 Suchi…以下内容可能对您感兴趣
https://machinelearning.org.cn/web-crawling-in-python/
感谢您的全面步骤。请问如何抓取推特数据?这里有人能提供链接吗?
嗨 Rina…以下资源可能对您感兴趣
https://machinelearning.org.cn/web-crawling-in-python/
感谢本教程。我怎样才能知道如何抓取私人GitHub仓库的数据?
感谢您的反馈 Billie!我不知道有任何方法可以执行该任务。
您好,希望您一切安好。
请问我怎样才能从任何网站上抓取任何数据?
嗨 Abdul…以下资源可能对您感兴趣
https://medium.com/dataseries/build-a-crawler-to-extract-web-data-in-10-mins-691b2cc4f1c3