模型平均集成将每个模型的预测结果平均地结合起来,并且通常能比单个模型获得更好的平均性能。
有时,我们希望一些非常好的模型能在集成预测中贡献更多,而一些可能有用但技巧较差的模型贡献更少。加权平均集成是一种方法,它允许多个模型根据其可信度或估计性能的比例来贡献预测。
在本教程中,您将学习如何在 Python 中使用 Keras 为深度学习神经网络开发加权平均集成。
完成本教程后,您将了解:
- 模型平均集成存在局限性,因为它们要求每个集成成员对预测的贡献是相等的。
- 加权平均集成允许每个集成成员对预测的贡献与其在保留数据集上的可信度或性能成比例地加权。
- 如何在 Keras 中实现加权平均集成,并将其结果与模型平均集成和独立模型进行比较。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。
- 2020年1月更新:已针对 scikit-learn v0.22 API 的更改进行更新。

如何为深度学习神经网络开发加权平均集成
照片由 Simon Matzinger 拍摄,保留部分权利。
教程概述
本教程分为六个部分;它们是:
- 加权平均集成
- 多类别分类问题
- 多层感知器模型
- 模型平均集成
- 网格搜索加权平均集成
- 优化加权平均集成
加权平均集成
模型平均是一种集成学习方法,其中每个集成成员对最终预测的贡献是相等的。
在回归的情况下,集成预测计算为成员预测的平均值。在预测类别标签的情况下,预测计算为成员预测的众数。在预测类别概率的情况下,预测可以计算为每个类别标签的总概率的 argmax。
这种方法的一个限制是,每个模型对集成做出的最终预测都具有相等的贡献。要求所有集成成员都比随机机会有更高的技能,尽管有些模型已知比其他模型表现得更好或更差。
加权集成是模型平均集成的扩展,其中每个成员对最终预测的贡献由模型的性能加权。
模型权重是小的正值,所有权重的总和为一,这使得权重可以指示每个模型的信任百分比或预期性能。
可以将权重 Wk 视为对预测器 k 的信念,因此我们约束权重为正且总和为一。
— Learning with ensembles: How over-fitting can be useful, 1996.
权重的均匀值(例如,1/k,其中 k 是集成成员的数量)意味着加权集成充当简单的平均集成。寻找权重的解析解不存在(我们无法计算它们);相反,权值的值可以使用训练数据集或保留的验证数据集来估计。
使用用于拟合集成成员的相同训练集来寻找权重可能会导致模型过拟合。更稳健的方法是使用集成成员在训练期间未见过保留的验证数据集。
最简单、也许最全面的方法是为每个集成成员对 0 到 1 之间的权重值进行网格搜索。或者,可以使用优化过程,如线性求解器或梯度下降优化,来估计权重,使用单位范数权重约束来确保权重向量的总和为一。
除非保留的验证数据集足够大且具有代表性,否则加权集成相比简单的平均集成存在过拟合的风险。
在不计算显式权重系数的情况下,为给定模型增加更多权重的一个简单替代方法是多次将该模型添加到集成中。虽然灵活性较低,但它允许一个表现良好的模型在集成做出的给定预测中贡献多次。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
多类别分类问题
我们将使用一个小巧的多类分类问题作为基础来演示加权平均集成。
scikit-learn 类提供了 make_blobs() 函数,可用于创建具有指定样本数、输入变量、类别和类别内样本方差的多类分类问题。
该问题有两个输入变量(表示点的 x 和 y 坐标),每个组内点的标准差为 2.0。我们将使用相同的随机状态(伪随机数生成器的种子)来确保我们始终获得相同的数据点。
|
1 2 |
# 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) |
结果是我们可以建模的数据集的输入和输出元素。
为了了解问题的复杂性,我们可以在二维散点图上绘制每个点,并根据类别值对每个点进行着色。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# blob 数据集的散点图 from sklearn.datasets import make_blobs from matplotlib import pyplot from pandas import DataFrame # 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 散点图,点按类别值着色 df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y)) colors = {0:'red', 1:'blue', 2:'green'} fig, ax = pyplot.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key]) pyplot.show() |
运行此示例将生成整个数据集的散点图。我们可以看到,标准差为 2.0 意味着这些类不是线性可分的(不能用一条线分开),导致许多模糊的点。
这是可取的,因为它意味着问题并非微不足道,并且可以让神经网络模型找到许多不同的“足够好”的候选解决方案,从而产生高方差。

具有三个类别且点按类别值着色的 Blob 数据集散点图
多层感知器模型
在我们定义模型之前,我们需要构建一个适合加权平均集成的问题。
在我们的问题中,训练数据集相对较小。具体来说,训练数据集中的样本与保留数据集的比例为 10:1。这模拟了我们可能拥有大量未标记样本和少量标记样本用于训练模型的情况。
我们将从斑点问题中创建 1100 个数据点。模型将在前 100 个点上进行训练,其余 1000 个将保留在测试数据集中,模型无法使用。
这是一个多类分类问题,我们将使用输出层的 softmax 激活函数对其进行建模。这意味着模型将预测一个包含三个元素的向量,表示样本属于每个类别的概率。因此,在我们将行分割为训练集和测试集之前,我们必须对类别值进行独热编码。我们可以使用 Keras 的 to_categorical() 函数来完成此操作。
|
1 2 3 4 5 6 7 8 9 |
# 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 独热编码输出变量 y = to_categorical(y) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) |
接下来,我们可以定义并编译模型。
模型将期望具有两个输入变量的样本。然后,模型有一个具有 25 个节点和 ReLU 激活函数的隐藏层,然后是一个具有三个节点以预测每个类别概率的输出层,以及一个 softmax 激活函数。
由于问题是多类的,我们将使用分类交叉熵损失函数来优化模型,以及高效的 Adam 随机梯度下降。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) |
模型将进行 500 个训练周期,我们将在每个周期在测试集上评估模型,将测试集用作验证集。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0) |
运行结束时,我们将评估模型在训练集和测试集上的性能。
|
1 2 3 4 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
最后,我们将绘制模型在训练集和验证集上每个训练周期的准确率学习曲线。
|
1 2 3 4 5 |
# 模型准确率的学习曲线 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 为 blob 数据集开发一个 mlp from sklearn.datasets import make_blobs from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 独热编码输出变量 y = to_categorical(y) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) # 定义模型 model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 模型准确率的学习曲线 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印每个数据集的形状以进行确认,然后打印最终模型在训练集和测试集上的性能。
注意:您 获得的结果可能不同,这取决于算法或评估程序的随机性,或数值精度的差异。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型在训练数据集上达到了约 87% 的准确率,我们知道这是乐观的,而在测试数据集上达到了约 81%,我们预计这会更现实。
|
1 2 |
(100, 2) (1000, 2) 训练:0.870,测试:0.814 |
还创建了一条线图,显示了模型在训练集和测试集上每个训练周期的准确率学习曲线。
我们可以看到,在大部分运行过程中,训练准确率更加乐观,正如我们对最终分数所注意到的那样。
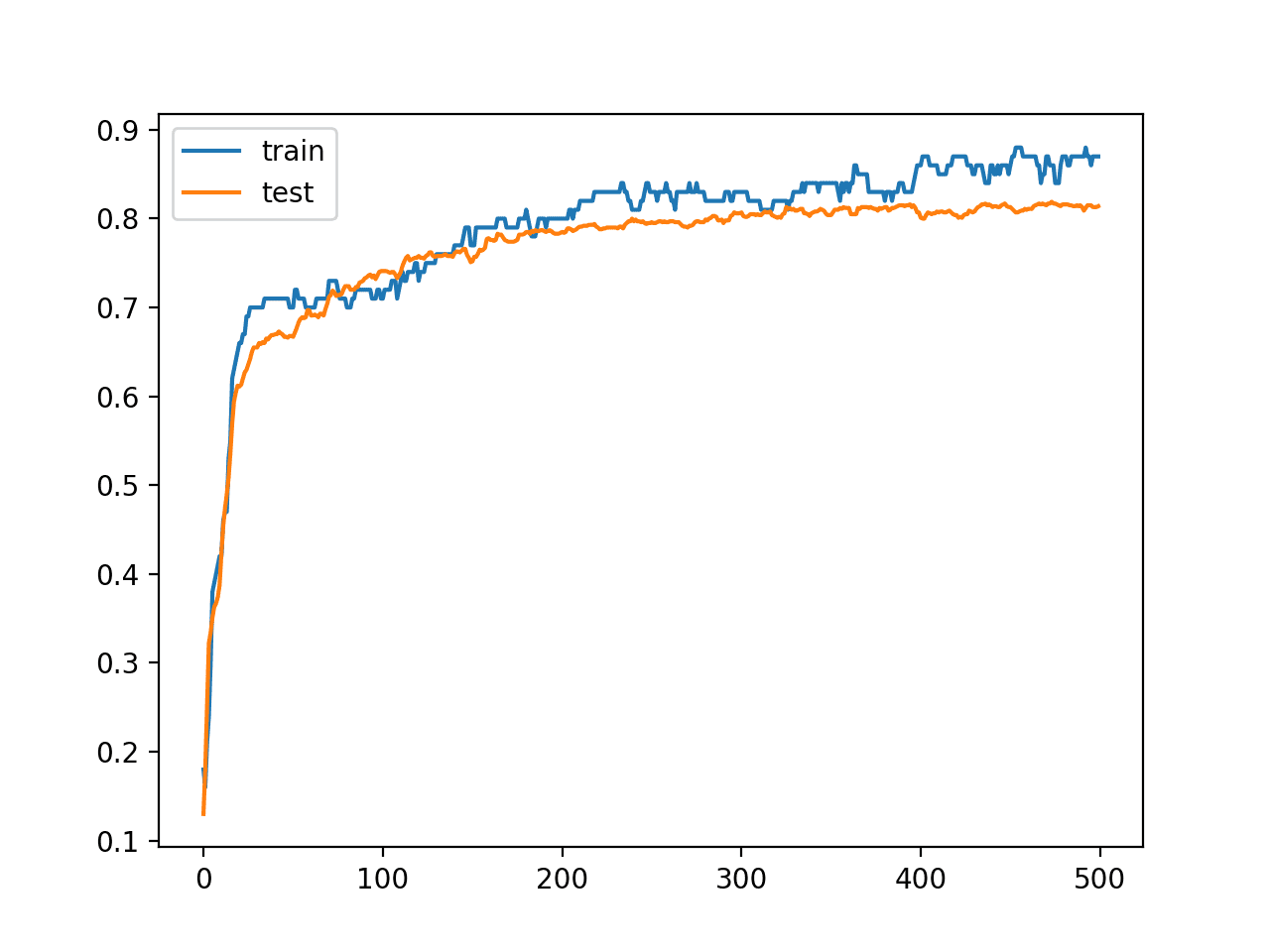
绘制每个训练周期中模型在训练集和测试集上的准确率学习曲线
既然我们已经确定该模型是开发集成的一个好候选者,那么接下来我们可以着手开发一个简单的模型平均集成。
模型平均集成
在查看加权平均集成之前,我们可以开发一个简单的模型平均集成。
模型平均集成的结果可以作为比较点,因为我们期望一个配置良好的加权平均集成能够表现得更好。
首先,我们需要拟合多个模型来开发集成。我们将定义一个名为 fit_model() 的函数,该函数用于在训练数据集上创建和拟合单个模型,我们可以重复调用此函数来创建任意数量的模型。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 在数据集上拟合模型 def fit_model(trainX, trainy): trainy_enc = to_categorical(trainy) # 定义模型 model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy_enc, epochs=500, verbose=0) return model |
我们可以调用此函数来创建 10 个模型的池。
|
1 2 3 |
# 拟合所有模型 n_members = 10 members = [fit_model(trainX, trainy) for _ in range(n_members)] |
接下来,我们可以开发模型平均集成。
我们不知道有多少成员适合这个问题,因此我们可以创建包含 1 到 10 个成员的不同大小的集成,并在测试集上评估每个集成的性能。
我们还可以评估每个独立模型在测试集上的性能。这为模型平均集成提供了一个有用的比较点,因为我们期望平均而言,集成将优于随机选择的单个模型。
每个模型都预测每个类别标签的概率,例如,有三个输出。可以通过对预测概率使用 argmax() 函数将单个预测转换为类别标签,例如,返回预测中具有最大概率值的索引。我们可以通过对每个类别预测的概率求和来集成多个模型的预测,并对结果使用 argmax()。下面的 ensemble_predictions() 函数实现了此行为。
|
1 2 3 4 5 6 7 8 9 10 |
# 为多类分类进行集成预测 def ensemble_predictions(members, testX): # 进行预测 yhats = [model.predict(testX) for model in members] yhats = array(yhats) # 跨集成成员求和 summed = numpy.sum(yhats, axis=0) # 跨类求 argmax result = argmax(summed, axis=1) return result |
通过选择所需数量的模型,调用 ensemble_predictions() 函数进行预测,然后通过将预测与真实值进行比较来计算预测的准确性,来估计给定大小的集成性能。下面的 evaluate_n_members() 函数实现了此行为。
|
1 2 3 4 5 6 7 8 |
# 评估集成中的特定数量成员 def evaluate_n_members(members, n_members, testX, testy): # 选择成员子集 subset = members[:n_members] # 进行预测 yhat = ensemble_predictions(subset, testX) # 计算准确率 return accuracy_score(testy, yhat) |
每个大小的集成的分数可以存储以供以后绘制,并且收集每个模型的得分,并报告平均性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 在保留集上评估不同数量的集成 single_scores, ensemble_scores = list(), list() for i in range(1, len(members)+1): # 评估具有 i 个模型的集成 ensemble_score = evaluate_n_members(members, i, testX, testy) # 单独评估第 i 个模型 testy_enc = to_categorical(testy) _, single_score = members[i-1].evaluate(testX, testy_enc, verbose=0) # 总结这一步 print('> %d: single=%.3f, ensemble=%.3f' % (i, single_score, ensemble_score)) ensemble_scores.append(ensemble_score) single_scores.append(single_score) # 总结单个最终模型的平均准确度 print('Accuracy %.3f (%.3f)' % (mean(single_scores), std(single_scores))) |
最后,我们创建一个图表,显示每个独立模型的准确率(蓝点)以及模型平均集成随着成员数量从 1 增加到 10 的性能(橙线)。
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
# model averaging ensemble for the blobs dataset from sklearn.datasets import make_blobs from sklearn.metrics import accuracy_score from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot from numpy import mean from numpy import std import numpy from numpy import array from numpy import argmax # 在数据集上拟合模型 def fit_model(trainX, trainy): trainy_enc = to_categorical(trainy) # 定义模型 model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy_enc, epochs=500, verbose=0) return model # 为多类分类进行集成预测 def ensemble_predictions(members, testX): # 进行预测 yhats = [model.predict(testX) for model in members] yhats = array(yhats) # 跨集成成员求和 summed = numpy.sum(yhats, axis=0) # 跨类求 argmax result = argmax(summed, axis=1) return result # 评估集成中的特定数量成员 def evaluate_n_members(members, n_members, testX, testy): # 选择成员子集 subset = members[:n_members] # 进行预测 yhat = ensemble_predictions(subset, testX) # 计算准确率 return accuracy_score(testy, yhat) # 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) # 拟合所有模型 n_members = 10 members = [fit_model(trainX, trainy) for _ in range(n_members)] # 在保留集上评估不同数量的集成 single_scores, ensemble_scores = list(), list() for i in range(1, len(members)+1): # 评估具有 i 个模型的集成 ensemble_score = evaluate_n_members(members, i, testX, testy) # 单独评估第 i 个模型 testy_enc = to_categorical(testy) _, single_score = members[i-1].evaluate(testX, testy_enc, verbose=0) # 总结这一步 print('> %d: single=%.3f, ensemble=%.3f' % (i, single_score, ensemble_score)) ensemble_scores.append(ensemble_score) single_scores.append(single_score) # 总结单个最终模型的平均准确度 print('Accuracy %.3f (%.3f)' % (mean(single_scores), std(single_scores))) # 绘制分数与集成成员数量的关系 x_axis = [i for i in range(1, len(members)+1)] pyplot.plot(x_axis, single_scores, marker='o', linestyle='None') pyplot.plot(x_axis, ensemble_scores, marker='o') pyplot.show() |
运行该示例后,首先会报告每个单个模型的性能以及具有给定大小(1、2、3 等)成员的模型平均集成的性能。
注意:您 获得的结果可能不同,这取决于算法或评估程序的随机性,或数值精度的差异。请考虑运行示例几次并比较平均结果。
在此次运行中,单个模型的平均性能约为 80.4%,而具有 5 到 9 个成员的集成可以实现 80.8% 到 81% 之间的性能。正如预期的那样,一个规模适中的模型平均集成的性能平均优于随机选择的单个模型的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(100, 2) (1000, 2) > 1: single=0.803, ensemble=0.803 > 2: single=0.805, ensemble=0.808 > 3: single=0.798, ensemble=0.805 > 4: single=0.809, ensemble=0.809 > 5: single=0.808, ensemble=0.811 > 6: single=0.805, ensemble=0.808 > 7: single=0.805, ensemble=0.808 > 8: single=0.804, ensemble=0.809 > 9: single=0.810, ensemble=0.810 > 10: single=0.794, ensemble=0.808 Accuracy 0.804 (0.005) |
接下来,将创建一个图表,比较单个模型(蓝点)的准确性与模型平均集成(橙线)的准确性,后者的大小逐渐增加。
在此次运行中,集成模型的橙线清楚地显示出比单个模型更好的或可比的性能(如果隐藏了点)。

折线图显示单个模型的准确性(蓝点)和不断增加的集成模型的准确性(橙线)
现在我们知道了如何开发模型平均集成,我们可以将该方法再进一步,通过对集成成员的贡献进行加权。
网格搜索加权平均集成
模型平均集成允许每个集成成员对集成的预测贡献相等的量。
我们可以更新示例,使得每个集成成员的贡献由一个系数加权,该系数指示模型的信任度或预期性能。权重值是介于 0 和 1 之间的小数值,其处理方式类似于百分比,使得所有集成成员的权重之和为一。
首先,我们必须更新 ensemble_predictions() 函数,使其能够为每个集成成员使用权重向量。
我们必须计算加权和,而不是简单地对每个集成成员的预测求和。我们可以手动使用 for 循环来实现这一点,但这效率非常低;例如
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 计算预测的加权和 def weighted_sum(weights, yhats): rows = list() for j in range(yhats.shape[1]): # 枚举值 row = list() for k in range(yhats.shape[2]): # 枚举成员 value = 0.0 for i in range(yhats.shape[0]): value += weights[i] * yhats[i,j,k] row.append(value) rows.append(row) return array(rows) |
相反,我们可以使用高效的 NumPy 函数来实现加权和,例如 einsum() 或 tensordot()。
对这些函数的详细讨论有些超出范围,因此请参考 API 文档以获取有关如何使用这些函数的更多信息,因为如果您不熟悉线性代数和/或 NumPy,它们会很棘手。我们将使用 tensordot() 函数来应用具有所需求和的张量积;更新后的 ensemble_predictions() 函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 |
# 为多类分类进行集成预测 def ensemble_predictions(members, weights, testX): # 进行预测 yhats = [model.predict(testX) for model in members] yhats = array(yhats) # 按集成成员进行加权求和 summed = tensordot(yhats, weights, axes=((0),(0))) # 跨类求 argmax result = argmax(summed, axis=1) return result |
接下来,我们必须更新 evaluate_ensemble() 以在进行集成预测时传递权重。
|
1 2 3 4 5 6 |
# 评估集成中的特定数量成员 def evaluate_ensemble(members, weights, testX, testy): # 进行预测 yhat = ensemble_predictions(members, weights, testX) # 计算准确率 return accuracy_score(testy, yhat) |
我们将使用一个中等规模的五成员集成,该集成在模型平均集成中表现良好。
|
1 2 3 |
# 拟合所有模型 n_members = 5 members = [fit_model(trainX, trainy) for _ in range(n_members)] |
然后,我们可以估算每个单独模型在测试数据集上的性能作为参考。
|
1 2 3 4 5 |
# 在测试集上评估每个单独模型 testy_enc = to_categorical(testy) for i in range(n_members): _, test_acc = members[i].evaluate(testX, testy_enc, verbose=0) print('Model %d: %.3f' % (i+1, test_acc)) |
接下来,我们可以为每个五成员集成使用 1/5 或 0.2 的权重,并使用新函数来估算模型平均集成(称为等权重集成)的性能。
我们预期这个集成将表现得与任何单个模型一样好或更好。
|
1 2 3 4 |
# 评估平均集成(等权重) weights = [1.0/n_members for _ in range(n_members)] score = evaluate_ensemble(members, weights, testX, testy) print('Equal Weights Score: %.3f' % score) |
最后,我们可以开发一个加权平均集成。
一种简单但详尽的为集成成员寻找权重的方法是网格搜索值。我们可以定义一个粗略的权重值网格,从 0.0 到 1.0,步长为 0.1,然后生成所有可能的包含这些值的五元素向量。生成所有可能的组合称为 笛卡尔积,可以使用标准库中的 itertools.product() 函数 在 Python 中实现。
此方法的一个限制是,权重向量将不会如要求那样加到一(称为单位范数)。通过计算绝对权重值之和(称为 L1 范数)并将每个权重除以该值,我们可以强制每个生成的权重向量具有单位范数。下面的 normalize() 函数实现了这个技巧。
|
1 2 3 4 5 6 7 8 9 |
# 将向量归一化为单位范数 def normalize(weights): # 计算 l1 向量范数 result = norm(weights, 1) # 检查是否为全零向量 if result == 0.0: return weights # 返回归一化向量(单位范数) return weights / result |
现在我们可以枚举笛卡尔积生成的每个权重向量,对其进行归一化,并通过进行预测来评估它,并保留最佳的权重以用于我们最终的权重平均集成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 网格搜索权重 def grid_search(members, testX, testy): # 定义要考虑的权重 w = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] best_score, best_weights = 0.0, None # 迭代所有可能的组合(笛卡尔积) for weights in product(w, repeat=len(members)): # 如果所有权重都相等则跳过 if len(set(weights)) == 1: continue # 技巧,归一化权重向量 weights = normalize(weights) # 评估权重 score = evaluate_ensemble(members, weights, testX, testy) if score > best_score: best_score, best_weights = score, weights print('>%s %.3f' % (best_weights, best_score)) return list(best_weights) |
一旦找到,我们就可以报告我们的权重平均集成在测试数据集上的性能,我们预期它会比最佳的单个模型更好,并且最好比模型平均集成更好。
|
1 2 3 4 |
# 网格搜索权重 weights = grid_search(members, testX, testy) score = evaluate_ensemble(members, weights, testX, testy) print('Grid Search Weights: %s, Score: %.3f' % (weights, score)) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
# 对 blobs 问题的加权平均集成寻找系数的网格搜索 from sklearn.datasets import make_blobs from sklearn.metrics import accuracy_score from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot from numpy import mean from numpy import std from numpy import array from numpy import argmax from numpy import tensordot from numpy.linalg import norm from itertools import product # 在数据集上拟合模型 def fit_model(trainX, trainy): trainy_enc = to_categorical(trainy) # 定义模型 model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy_enc, epochs=500, verbose=0) return model # 为多类分类进行集成预测 def ensemble_predictions(members, weights, testX): # 进行预测 yhats = [model.predict(testX) for model in members] yhats = array(yhats) # 按集成成员进行加权求和 summed = tensordot(yhats, weights, axes=((0),(0))) # 跨类求 argmax result = argmax(summed, axis=1) return result # 评估集成中的特定数量成员 def evaluate_ensemble(members, weights, testX, testy): # 进行预测 yhat = ensemble_predictions(members, weights, testX) # 计算准确率 return accuracy_score(testy, yhat) # 将向量归一化为单位范数 def normalize(weights): # 计算 l1 向量范数 result = norm(weights, 1) # 检查是否为全零向量 if result == 0.0: return weights # 返回归一化向量(单位范数) return weights / result # 网格搜索权重 def grid_search(members, testX, testy): # 定义要考虑的权重 w = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] best_score, best_weights = 0.0, None # 迭代所有可能的组合(笛卡尔积) for weights in product(w, repeat=len(members)): # 如果所有权重都相等则跳过 if len(set(weights)) == 1: continue # 技巧,归一化权重向量 weights = normalize(weights) # 评估权重 score = evaluate_ensemble(members, weights, testX, testy) if score > best_score: best_score, best_weights = score, weights print('>%s %.3f' % (best_weights, best_score)) return list(best_weights) # 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) # 拟合所有模型 n_members = 5 members = [fit_model(trainX, trainy) for _ in range(n_members)] # 在测试集上评估每个单独模型 testy_enc = to_categorical(testy) for i in range(n_members): _, test_acc = members[i].evaluate(testX, testy_enc, verbose=0) print('Model %d: %.3f' % (i+1, test_acc)) # 评估平均集成(等权重) weights = [1.0/n_members for _ in range(n_members)] score = evaluate_ensemble(members, weights, testX, testy) print('Equal Weights Score: %.3f' % score) # 网格搜索权重 weights = grid_search(members, testX, testy) score = evaluate_ensemble(members, weights, testX, testy) print('Grid Search Weights: %s, Score: %.3f' % (weights, score)) |
运行该示例首先创建五个单独的模型,并评估它们在测试数据集上的性能。
注意:您 获得的结果可能不同,这取决于算法或评估程序的随机性,或数值精度的差异。请考虑运行示例几次并比较平均结果。
在此次运行中,我们可以看到模型 2 具有最佳的独立性能,准确率约为 81.7%。
接下来,创建一个模型平均集成,其性能约为 80.7%,与大多数模型相比是合理的,但并非与所有模型都如此。
|
1 2 3 4 5 6 7 |
(100, 2) (1000, 2) 模型 1:0.798 模型 2:0.817 模型 3:0.798 模型 4:0.806 模型 5:0.810 等权重分数:0.807 |
接下来执行网格搜索。它相当慢,在现代硬件上可能需要大约二十分钟。可以使用 Joblib 等库轻松地使该过程并行化。
每次发现新的表现最佳的权重集时,都会报告它及其在测试数据集上的性能。我们可以看到,在运行期间,该过程发现仅使用模型 2 就能获得良好的性能,直到被更好的东西取代。
我们可以看到,在此次运行中,使用仅关注第一个和第二个模型的权重取得了最佳性能,在测试数据集上的准确率为 81.8%。这优于同一数据集上的单个模型和模型平均集成。
|
1 2 3 4 5 6 |
>[0. 0. 0. 0. 1.] 0.810 >[0. 0. 0. 0.5 0.5] 0.814 >[0. 0. 0. 0.33333333 0.66666667] 0.815 >[0. 1. 0. 0. 0.] 0.817 >[0.23076923 0.76923077 0. 0. 0. ] 0.818 网格搜索权重:[0.23076923076923075, 0.7692307692307692, 0.0, 0.0, 0.0],分数:0.818 |
一种寻找权重的替代方法是随机搜索,这已被证明对模型超参数调优普遍有效。
加权平均 MLP 集成
寻找权重值的替代方法是使用定向优化过程。
优化是一个搜索过程,但不是随机或穷举地采样可能的解决方案空间,而是利用任何可用信息来指导搜索的下一步,例如朝着具有较低误差的权重集前进。
SciPy 库提供了许多出色的优化算法,包括局部和全局搜索方法。
SciPy 提供了一个 差分进化 方法的实现。这是为数不多的随机全局搜索算法之一,它“能够很好地”用于具有连续输入的函数优化,并且效果很好。
differential_evolution() SciPy 函数要求指定一个函数来评估一组权重并返回一个要最小化的分数。我们可以最小化分类误差(1 – 准确率)。
与网格搜索一样,我们必须在评估权重向量之前对其进行归一化。下面的 loss_function() 函数将在优化过程中用作评估函数。
|
1 2 3 4 5 6 |
# 优化过程的损失函数,旨在最小化 def loss_function(weights, members, testX, testy): # 归一化权重 normalized = normalize(weights) # 计算误差率 return 1.0 - evaluate_ensemble(members, normalized, testX, testy) |
我们还必须指定优化过程的边界。我们可以将边界定义为一个五维超立方体(例如,5 个集成成员的 5 个权重),其值介于 0.0 和 1.0 之间。
|
1 2 |
# 定义每个权重的边界 bound_w = [(0.0, 1.0) for _ in range(n_members)] |
我们的损失函数除了权重之外还需要三个参数,我们将它们作为元组提供,然后传递给对 loss_function() 的调用,以便在每次评估一组权重时使用。
|
1 2 |
# 损失函数的参数 search_arg = (members, testX, testy) |
现在我们可以调用我们的优化过程。
我们将算法的总迭代次数限制为 1,000 次,并使用小于默认值的容差来检测搜索过程是否已收敛。
|
1 2 |
# 集成权重的全局优化 result = differential_evolution(loss_function, bound_w, search_arg, maxiter=1000, tol=1e-7) |
对 differential_evolution() 的调用结果是一个包含搜索各种信息的字典。
重要的是,“x”键包含搜索过程中找到的最佳权重集。我们可以检索最佳权重集,然后报告它们以及它们在加权集成中使用时的测试集性能。
|
1 2 3 4 5 6 |
# 获取选定的权重 weights = normalize(result['x']) print('Optimized Weights: %s' % weights) # 评估选定的权重 score = evaluate_ensemble(members, weights, testX, testy) print('Optimized Weights Score: %.3f' % score) |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
# 对 blobs 问题进行加权集成系数的全局优化 from sklearn.datasets import make_blobs from sklearn.metrics import accuracy_score from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot from numpy import mean from numpy import std from numpy import array from numpy import argmax from numpy import tensordot from numpy.linalg import norm from scipy.optimize import differential_evolution # 在数据集上拟合模型 def fit_model(trainX, trainy): trainy_enc = to_categorical(trainy) # 定义模型 model = Sequential() model.add(Dense(25, input_dim=2, activation='relu')) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy_enc, epochs=500, verbose=0) return model # 为多类分类进行集成预测 def ensemble_predictions(members, weights, testX): # 进行预测 yhats = [model.predict(testX) for model in members] yhats = array(yhats) # 按集成成员进行加权求和 summed = tensordot(yhats, weights, axes=((0),(0))) # 跨类求 argmax result = argmax(summed, axis=1) return result # # 评估集成中特定数量的成员 def evaluate_ensemble(members, weights, testX, testy): # 进行预测 yhat = ensemble_predictions(members, weights, testX) # 计算准确率 return accuracy_score(testy, yhat) # 将向量归一化为单位范数 def normalize(weights): # 计算 l1 向量范数 result = norm(weights, 1) # 检查是否为全零向量 if result == 0.0: return weights # 返回归一化向量(单位范数) return weights / result # 优化过程的损失函数,旨在最小化 def loss_function(weights, members, testX, testy): # 归一化权重 normalized = normalize(weights) # 计算误差率 return 1.0 - evaluate_ensemble(members, normalized, testX, testy) # 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) # 拟合所有模型 n_members = 5 members = [fit_model(trainX, trainy) for _ in range(n_members)] # 在测试集上评估每个单独模型 testy_enc = to_categorical(testy) for i in range(n_members): _, test_acc = members[i].evaluate(testX, testy_enc, verbose=0) print('Model %d: %.3f' % (i+1, test_acc)) # 评估平均集成(等权重) weights = [1.0/n_members for _ in range(n_members)] score = evaluate_ensemble(members, weights, testX, testy) print('Equal Weights Score: %.3f' % score) # 定义每个权重的边界 bound_w = [(0.0, 1.0) for _ in range(n_members)] # 损失函数的参数 search_arg = (members, testX, testy) # 集成权重的全局优化 result = differential_evolution(loss_function, bound_w, search_arg, maxiter=1000, tol=1e-7) # 获取选定的权重 weights = normalize(result['x']) print('Optimized Weights: %s' % weights) # 评估选定的权重 score = evaluate_ensemble(members, weights, testX, testy) print('Optimized Weights Score: %.3f' % score) |
运行示例首先创建五个单独的模型,并评估每个模型在测试数据集上的性能。
注意:您 获得的结果可能不同,这取决于算法或评估程序的随机性,或数值精度的差异。请考虑运行示例几次并比较平均结果。
在此次运行中,我们可以看到模型 3 和模型 4 的性能最佳,准确率约为 82.2%。
接下来,在测试集上评估具有所有五个成员的模型平均集成,报告的准确率为 81.8%,这比某些单个模型要好,但不如所有单个模型。
|
1 2 3 4 5 6 7 |
(100, 2) (1000, 2) 模型 1:0.814 模型 2:0.811 模型 3:0.822 模型 4:0.822 模型 5:0.809 等权重分数:0.818 |
优化过程相对较快。
我们可以看到,该过程找到了一个权重集,该权重集主要关注模型 3 和模型 4,并将剩余的关注分配给其他模型,在测试集上实现了约 82.4% 的准确率,优于模型平均集成和各个模型。
|
1 2 |
优化权重:[0.1660322 0.09652591 0.33991854 0.34540932 0.05211403] 优化权重分数:0.824 |
需要注意的是,在这些示例中,我们将测试数据集视为验证数据集。这样做是为了使示例保持重点和技术上的简单性。在实践中,集成权重的选择和调整将通过验证数据集来选择,并且单个模型、模型平均集成和加权集成将在单独的测试集上进行比较。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 并行化网格搜索。更新网格搜索示例,使用 Joblib 库来并行化权重评估。
- 实现随机搜索。更新网格搜索示例,使用对权重系数进行随机搜索。
- 尝试局部搜索。尝试使用 SciPy 库提供的局部搜索过程而不是全局搜索,并比较性能。
- 重复全局优化。针对给定模型集重复全局优化过程多次,以查看在多次运行中是否可以找到不同的权重集。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 当网络意见不一致时:混合神经网络的集成方法, 1995.
- 神经网络集成、交叉验证和主动学习, 1995.
- 集成学习:过拟合如何有用, 1996.
API
- Keras 顺序模型入门
- Keras核心层API
- scipy.stats.mode API
- numpy.argmax API
- sklearn.datasets.make_blobs API
- numpy.argmax API
- numpy.einsum API
- numpy.tensordot API
- itertools.product API
- scipy.optimize API
- scipy.optimize.differential_evolution API
文章
总结
在本教程中,您将学习如何在 Python 和 Keras 中开发深度学习神经网络模型的加权平均集成。
具体来说,你学到了:
- 模型平均集成存在局限性,因为它们要求每个集成成员对预测的贡献是相等的。
- 加权平均集成允许每个集成成员对预测的贡献与其在保留数据集上的可信度或性能成比例地加权。
- 如何在 Keras 中实现加权平均集成,并将其结果与模型平均集成和独立模型进行比较。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







好文章 Jason!谢谢..
此外,使用误差项不相关的模型可以产生更好的结果。
一个问题:有些人建议给予与 RMSE 成反比或与准确率度量成正比的权重。您认为从这种方法得出的权重是否与从网格搜索得出的权重相似?或者它们有区别吗?
提前感谢 Jason。
我更喜欢使用全局优化算法来寻找鲁棒的权重。
嗨 Jason,写得很好,感谢分享!
尝试使用 Scipy 优化库进行局部搜索,将权重初始化为线性、Ridge 或 Lasso 回归的系数。这只需要几秒钟,但性能将与网格搜索相似。
好建议,您认为它会优于像 DE 这样的全局搜索吗?
我表示怀疑,因为我认为误差曲面高度非线性且可能是多模态的。
很好的例子。
谢谢,
Jay
谢谢 Jay。
好文章,谢谢 Jason。
我对加权平均集成有一些担忧。它会加剧过拟合问题吗?毕竟,机器学习算法本身就容易过拟合,现在给不同的模型分配不同的权重是另一个层级的过拟合?在样本外预测中,它真的比普通的平均权重版本更好吗?
这是一个风险,但可以使用单独的验证数据集或样本外数据来拟合权重,从而降低风险。
嗨
文章说
“由于训练算法的随机性,您的结果会有所不同。”
我不太明白这一点,因为 make_blob 函数调用使用了 random_state 参数,所以它的输出应该是确定的。所以我想知道结果的差异究竟来自哪里?
谢谢
差异来自模型的随机初始化和训练。
嗨,Jason,
一如既往,我在您的文章中找到了一个问题的解决方案。谢谢。
DE 实现是否只能使用 sklearn 而不是 keras?如果是,您能否推荐一个资源?
据我所知,sklearn 没有 DE 实现。
感谢您的快速回复。
我们可以使用其他分类算法(如高斯朴素贝叶斯、KNN 等)创建异构集成模型,并仍然使用差分进化来优化权重吗?
当然,您可能希望将 sklearn 模型与神经网络结合起来。
这将是一个堆叠集成
https://machinelearning.org.cn/stacking-ensemble-for-deep-learning-neural-networks/
你好,
在执行此块之后使用另一个数据集时
def ensemble_predictions(members, weights, x_test)
yhats = [model.predict(x_test) for model in members]
yhats = array(yhats)
# 对集成成员求和
summed = tensordot(yhats, weights, axes=((0),(0)))
# 对类别求argmax
result = argmax(summed, axis=1)
我收到以下错误:
~\Anaconda3\lib\site-packages\numpy\core\fromnumeric.py in argmax(a, axis, out)
961
962 “””
–> 963 return _wrapfunc(a, ‘argmax’, axis=axis, out=out)
964
965
~\Anaconda3\lib\site-packages\numpy\core\fromnumeric.py in _wrapfunc(obj, method, *args, **kwds)
55 def _wrapfunc(obj, method, *args, **kwds)
56 try
—> 57 return getattr(obj, method)(*args, **kwds)
AxisError: axis 1 is out of bounds for array of dimension 1
您能提供一个解决方案来摆脱这个问题吗?
谢谢你。
也许可以检查一下您的数据集是否已正确加载,并且模型是否已适当修改以适应您数据集中的特征数量。
谢谢你,Jason。我检查了,得到了 4 个模型的个体性能准确率。
您能否展示一下执行以下代码后的输出应该是什么样子?
>>summed = tensordot(yhats, weights, axes=((0),(0))) #summed = np.sum(yhats, axis=0)
>>print(“summed”,summed)
在将权重(0.25)与 4 个模型的预测结果 yhats 相加后,我得到类似这样的结果
summed [ 1.5 0.5 2. 1. 1. 2. 1.25 1.25 1. 1.5 0. 1. 2.
0. 1.75 1. 0.5 0.5 1. 2. 1.25 1.5 0. 0.5 1.75
1. 0. 0. 1. 0. 1. 0. 2. 1. 1. 1.5 2. 1.
1. 1. 1. 1. 1. 2. 1. 1. 1. 2. 1.25 1. 1.
2. 1.5 0.5 1. 0. 1. 1. 0.5 1.5 0. 0. 0.
1.25 0. 1. 1.25 0. 2. 0.5 2. 1.25 0.5 1. 2. 0.5
2. 0.5 1. 2. 1.5 2. 0. 1.5 1.25 2. 1.5 1.25
1.5 1.75 0. 1. 1. 2. 1.5 0. ]
这正确吗?
抱歉,我无法为您运行或调试教程的修改版本。
X_train 和 X_test 的形状分别是 (384, 16) 和 (96, 16)
您最终解决这个问题了吗?我也遇到了同样的问题,“AxisError: axis 1 is out of bounds for array of dimension 1” 出现在“summed”数组上。
在注意到您的回复之前,我发送了下一条文本。
我只是想知道相加权重后的结构是否应该看起来像这样。
没关系。我会尝试的。
感谢您的及时回复。
您好,文章很棒,我有一些顾虑,无论是堆叠还是集成方法,模型都应该尝试捕获数据的不同方面或预测不同的结果,然后再输入到集成中,这样我们就可以在准确性上做出巨大的差异,而不仅仅是基于单个算法的随机种子。
是的。
嗨,Jason,
非常有信息量的文章。
如何在不进行循环的情况下将创建的集成用于 fit 方法,如下所示
ensemble.fit ?
谢谢。
没有 ensemble.fit。
嗨,Jason,
这里使用的差分进化方法是否有变异和交叉的默认值?或者不使用它们是否可以?
是的,默认值效果很好。
详情在此
https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.optimize.differential_evolution.html
您好,工作很棒,应该更改一个错误,行“y = to_categorical(y)”,如果 y 始终存在于内存中,例如在 jupyter 中,这会多次更改 y。
谢谢,但该脚本旨在从命令行运行一次。
谢谢 William,作为一个新手,我困惑了一整天。
您好,如何将此过程用于回归问题?
谢谢
您可以调整示例以用于回归。我现在还没有一个完整的示例。
您好 Branda,请指导我开发回归问题的集成模型?
太棒了!我还有另一件事可以玩!
这可能听起来是个愚蠢的问题,所以请原谅我的无知,但我想知道是否有办法将权重保存到一个检查点文件中以供以后使用?我看到我们在过程中创建了 5 个单独的模型,并获得了 5 个不同的准确率分数,我没问题将这 5 个不同的权重集保存为检查点文件,并将它们的准确率分数保存到文件中以便以后再次参考,然后根据这些分数权重进行前向预测,但我只是想知道是否有办法将它们合并到一个文件中以使事情更容易?再次感谢!
忽略我最后的问题!我在您的网站上找到了另一篇文章,可以回答我的问题,地址是
https://machinelearning.org.cn/polyak-neural-network-model-weight-ensemble/
谢谢!
不客气。
是的,您可以通过 save() 函数保存模型。
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
您可以将权重数组保存到文件中。
https://machinelearning.org.cn/how-to-save-a-numpy-array-to-file-for-machine-learning/
您好 Jason。感谢您的教程。我该如何处理两个模型接收两个不同输入的问题?假设我有一个 LSTM 模型,它接收时间序列数据作为输入,另一个 CNN 模型接收文本的词嵌入向量作为输入。那么,如果我想基于加权平均技术来集成这两个模型,如何组合不同的输入类型以获得最优权重?我也可以使用您使用的相同优化算法吗?
您对它们的预测(输出)进行加权,而不是对它们的输入进行加权。
从这个意义上说,它们的输入无关紧要。
嗨,Jason,
我从这个主题中学到了很多。我是一名新手,我有一个疑问。如果这是一个愚蠢的问题,请原谅我。
有一件事让我感到困惑是关于加权平均项。代码通过 argmax 函数找到每个实例的加权多数。加权平均在哪里计算?
请澄清我的疑虑。
谢谢你。
我想修改上一条查询中的句子:“代码通过选择最高加权和(使用 argmax 函数)来为每个实例给出预测类别”。
谢谢
我们对每个模型预测对最终预测的贡献进行加权,然后将预测转换为类别标签。
感谢您的回复。但我关心的是平均。平均在哪里发生?请原谅我的愚蠢。
我们对每个类别的预测概率之和进行求和,平均值只是一个归一化的和。
先生,由于我已经对深度学习模型应用了网格搜索优化。之后,我如何应用集成技术,例如,我可以将网格搜索应用于所有基础深度学习模型,还是有其他方法来应用集成技术?
通常,您不希望集成中包含经过高度优化的模型,这会使集成不稳定/脆弱。
您希望集成中包含“足够好”的模型。
您好,我的优化权重似乎不像您的那样遵循单个模型的得分,尽管最终集成模型的得分优于其他模型。我多次重新训练(与您的相同代码)。
模型 1:0.815
模型 2:0.809
模型 3:0.818
模型 4:0.808
模型 5:0.806
平均权重得分:0.814
优化权重得分:[0.07226963 0.25272131 0.10460353 0.14405271 0.42635282]
网格搜索权重:[0.07226963 0.25272131 0.10460353 0.14405271 0.42635282],得分:0.818
您有什么想法吗???
是的,请看这个
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
你好,
我非常感谢您的辛勤工作。我有一个问题
我使用了一个模型平均集成代码(做了一些回归任务的修改),现在我想将我的模型与网格搜索加权平均集成模型进行比较,用于回归应用。但我卡在了 tensordot 函数上。
您能否给我一个提示,如何在回归应用中使用该函数?
谢谢。
我相信它会是一样的,只是没有 argmax。
感谢您的回复。我已经为我的回归问题准备了加权平均集成。
我的问题是,当我使用 n_members 高达 4 时没有问题,但是当我使用 n_members >= 5 时,模型就会运行几个小时,既没有给出任何错误也没有给出最终的最佳权重。您知道可能的原因吗?
也许可以确认一下您没有引入错误?
是的,没有错误,因为当我初始化权重 w= [0,0.5,1] 时,模型可以正常运行 n_members=5,但是对于更高的 n_members 大约 >=8,它仍然既不给出错误也不给出最终的最佳权重。
我认为原因可能是更高的 n_members 的模型过于复杂?
抱歉,我不知道故障原因。
也许您遇到了内存不足的问题?
嗨,Jason,
非常感谢您撰写解释清晰的优秀文章。
我有一个问题,在这种情况下,什么将是我们的最终模型,将投入生产?在元学习(堆叠泛化)中,我们最后有一个最终模型,但在这种情况下,什么将是我们的最终模型,可以投入生产?
非常感谢!
不客气。
最终模型是模型的集成。
您将如何对具有不同窗口大小导致不同输入形状的模型进行集成,例如 LSTM 模型?因此,模型 A 的输入形状为 (window_size_A, features),模型 B 的输入形状为 (window_size_B, features)。窗口大小不同,但特征数量相同。因此,由于窗口大小不同,同一数据集的训练数据会为每个模型分开,使得模型 A 的 X_train.shape:(train_data_A, window_size_A, output) 而模型 B 的:(train_data_B, window_size_B, output)。请注意,训练数据来自同一数据集,但由于窗口大小不同,长度也不同。模型 A 和模型 B 的输出数量相同。您将如何集成这两个模型?
例如,您将如何集成这两个模型,特别是在适应不同窗口大小(即输入形状)方面?因为您帖子中的模型的输入形状都相同。
Model1
inputA= Input(shape(window_size_A, features))
hiddenA1=LSTM(units_A1, return_sequences=True)(inputA)
hiddenA2 = LSTM(units_A2, activation= ‘relu’)(hiddenA1) predictionA = Dense(output_A)(hiddenA2)
Model2
inputB= Input(shape(window_size_B, features))
hiddenB1=LSTM(units_B1, return_sequences=True)(inputB)
hiddenB2 = LSTM(units_B2, activation= ‘relu’)(hiddenB1) prediction = Dense(output_B)(hiddenB2)
我将非常感谢您在这件事上的建议。
也许一个多输入模型,带有每个输入“模型”的单独训练数据。
这会有帮助
https://machinelearning.org.cn/keras-functional-api-deep-learning/
感谢您的建议和推荐的文章。我尝试制作了一个多输入模型,然后为每个模型拥有不同的训练数据形状,即对于模型 A:(samples_A, window_size_A, features) 和对于模型 B:(samples_B, window_size_B, features)。samples_A 和 samples_B 的大小因窗口大小不同而不同。但是现在训练数据的形状不同,验证和测试数据的形状也不同。所以你可以用训练集 A i.e.(trainsamples_A, window_size_A, features) 来训练模型 A,然后将其与验证集 A i.e.(validationsamples_A, window_size_A, features) 进行比较,并用测试集 i.e.(testsamples_A, window_size_A, features) 来测试模型 A;并为模型 B 执行相同的操作。但是当组合模型时,您用什么来测试集合?测试的形状应该是什么?因为模型 A 和模型 B 的测试形状由它们的窗口大小决定。
任何见解都将非常感激。
这应该不是问题,因为每个输入模型都可以接受单独的训练和验证数据集数组/矩阵。
谢谢。我理解并同意您的观点,即每个输入模型都可以拥有独立的训练和验证集。但是一旦组合起来,要创建集成模型,应该用什么测试集来测试集成模型?因为由于窗口大小不同,两个输入模型的测试集形状也不同。每个单独的输入模型都可以用它自己的测试集进行测试,但完整的集成模型呢?
感谢您至今为止的所有指导!
您应该用未用于训练模型的数据来测试它,并以每个输入模型所需的方式进行准备。
如果这对您来说很困难,也许可以开发一些使用人为生成数据的小原型,以更好地熟悉或了解数据准备步骤。
再次感谢。我认为问题可能在于数据准备。
我成功地对 LSTM 集成进行了处理,其中每个 LSTM 模型都有一个模型输入,并且为集成模型也只有一个输入,这对于单个模型来说效果很好。
model_input = Input(shape=(50,2))
def firstmodel(model_input)
hiddenA1 = LSTM(6, return_sequences=True)(model_input)
hiddenA2 = LSTM(4, activation=’relu’)(hiddenA1)
outputA = Dense(24)(hiddenA2)
model = Model(inputs= model_input, outputs= outputA, name=”firstmodel”)
return model
def secondmodel(model_input)
hiddenB1 = LSTM(30, return_sequences=True)(model_input)
hiddenB2 = LSTM(20, activation=’relu’)(hiddenB1)
outputB = Dense(24)(hiddenB2)
model = Model(inputs= model_input, outputs= outputB, name=”secondmodel”)
return model
firstmodel = firstmodel(model_input)
secondmodel = secondmodel(model_input)
models = [firstmodel, secondmodel]
def ensemble(models, model_input)
outputs = [model.outputs[0] for model in models]
y = Average()(outputs)
model = Model(inputs = model_input, outputs = y, name=”ensemble”)
return model
ensemblemodel = (models, model_input)
def evaluate_rmse(model)
pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, pred))
return rmse
ensemble_rmse = evaluate_rmse(ensemblemodel)
但是当有两个不同的模型输入用于第一个和第二个模型时会发生什么?
first_model_input = Input(shape=(50,2))
second_model_input = Input(shape=(60,2))
那么集成模型的 model_input 是什么?集成模型的 X_test 的形状又是什么?因为当只有一个输入时,例如 first_model_input = Input(shape=(50,2)),那么 X_test.shape 是 (2554, 50, 2)。
但是现在有两个输入,所以有两个 X_test 形状,一个用于第一个模型输入,为 (2554, 50, 2),一个用于第二个模型输入,为 (2544, 60, 2)。
我仍然被同样的问题困扰,但可能会尝试使用人为生成的数据集。
很遗憾听到您遇到了麻烦,也许以下一些建议会有帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
谢谢????❤
不客气。
我想知道如何加快差分进化优化,它正在运行但花费的时间太长。
很好的问题!
也许可以尝试一个更简单的目标函数?
也许可以尝试更少的种群成员?
也许可以尝试在更快的 CPU 上运行?
我实际上是在 colab 笔记本上工作,并且我已经减少了成员数量,但仍然花费了很长时间。
也许可以尝试一个大型 AWS EC2 实例?
哦,好的!谢谢!🙂
不客气。
您好 Jason,感谢您精彩的教程。
我想知道,为什么不通过训练一个简单的全连接网络(其输入是每个模型的预测)来集成不同的模型?我觉得加权平均是一种简单的线性行为,而非线性可能会提高性能。是因为更容易解释加权平均,还是有更多原因?
是的,您可以做到。听起来像一个“堆叠”集成。
https://machinelearning.org.cn/stacking-ensemble-for-deep-learning-neural-networks/
感谢您的参考。再次感谢您的所有工作!
不客气。
集成模型中的最大模型数量是多少?
没有最大值。
到某个点,你会遇到边际收益递减。
非常感谢您的精彩文章。
如何将加权集成模型保存为一个新模型以供以后预测,例如 new_model.predict(X_test)?
另外,当我们进行 differential_evolution() 时,我们会多次调用 ensemble_predictions(members, weights, testX)。如果每个训练模型都相对复杂,model.predict() 会花费相当长的时间。实际上,我认为我们只需要得到 yhats 一次。那么我们是否可以添加一个 def 来计算 yhats (def calculat_yhats(members, testX):, return yhats),然后调用 ensemble_predictions(yhats, weights, testX)?
我不确定是否需要在每次优化权重时都计算 yhats。根据我的理解,只需要一次。请纠正我,如果我错了。非常感谢!
不客气。
也许你可以保存每个神经网络模型,然后保存权重。
非常感谢。您能否回答我的第二个问题,即我是否只需要计算一次 yhats?
如果子模型没有改变,那么在优化组合这些预测的权重时,就不需要重新计算模型所做的预测。
谢谢!在您的示例中,我认为我们只需要做一次 model.predict()。
不客气。
太棒的文章 Jason,谢谢。
话虽如此,在 LOOCV 方法中,加权平均不是一个好主意,对吗?
为什么会这样?
提前为我的愚蠢问题道歉,我正在为 tensordot 函数而苦恼,您如何将“yhats”与加权向量相乘?它给我一个 ValueError:sum of tensordot 的形状不匹配。
也许您可以从上面的工作示例开始,然后根据您的具体示例慢慢调整。
或者,也许您可以在 for 循环中手动将预测与权重相乘。
非常感谢您,先生,问题已经解决了
很高兴听到这个消息。