大型语言模型(LLM)是深度学习模型在处理人类语言方面的最新进展。它们已经展示了一些出色的应用案例。大型语言模型是一种经过训练的深度学习模型,能够以类似人类的方式理解和生成文本。在幕后,是一个庞大的Transformer模型在发挥魔力。
在这篇文章中,您将了解大型语言模型的结构及其工作原理。具体来说,您将了解到:
- 什么是Transformer模型
- Transformer模型如何读取文本并生成输出
- 大型语言模型如何以类似人类的方式生成文本

什么是大型语言模型。
图片由作者使用Stable Diffusion生成。保留部分权利。
通过我的书《使用ChatGPT最大化生产力》开始并应用ChatGPT。它提供了真实世界的用例和提示示例,旨在帮助您快速使用ChatGPT。
让我们开始吧。
概述
这篇博文分为三部分;它们是:
- 从Transformer模型到大型语言模型
- 为什么Transformer可以预测文本?
- 大型语言模型是如何构建的?
从Transformer模型到大型语言模型
作为人类,我们将文本视为单词的集合。句子是单词的序列。文档是章节、部分和段落的序列。然而,对于计算机来说,文本仅仅是字符的序列。为了使机器能够理解文本,可以构建一个基于循环神经网络的模型。该模型一次处理一个单词或字符,并在整个输入文本被消费后提供输出。这种模型工作得很好,除了有时在序列末尾到达时“忘记”序列开头发生的事情。
2017年,Vaswani等人发表了一篇名为《Attention Is All You Need》的论文,提出了一个Transformer模型。它基于注意力机制。与循环神经网络相反,注意力机制允许您一次性查看整个句子(甚至段落),而不是一次一个单词。这使得Transformer模型能够更好地理解单词的上下文。许多最先进的语言处理模型都基于Transformer。
要使用Transformer模型处理文本输入,您首先需要将其分词为一系列单词。这些词元随后被编码为数字并转换为嵌入,即保留其含义的词元向量空间表示。接下来,Transformer中的编码器将所有词元的嵌入转换为上下文向量。
下面是文本字符串、其分词和向量嵌入的示例。请注意,分词可以是子词,例如文本中的单词“nosegay”被分词为“nose”和“gay”。
|
1 |
她这么说着,低头看了看自己的手,惊讶地发现自己说话的时候已经戴上了一只兔子的小手套。“我怎么会做到的?”她想,“我一定是又变小了。”她站起来走到桌子旁边量了一下自己,发现,据她猜测,她现在大约有两英尺高,并且正在迅速缩小:很快她发现原因是她手里拿着的花束:她赶紧扔掉了花束,及时挽救了自己,免于完全缩小,她发现自己现在只有三英寸高。 |
|
1 |
['As', ' she', ' said', ' this', ',', ' she', ' looked', ' down', ' at', ' her', ' hands', ',', ' and', ' was', ' surprised', ' to', ' find', ' that', ' she', ' had', ' put', ' on', ' one', ' of', ' the', ' rabbit', "'s", ' little', ' gloves', ' while', ' she', ' was', ' talking', '.', ' "', 'How', ' can', ' I', ' have', ' done', ' that', '?"', ' thought', ' she', ',', ' "', 'I', ' must', ' be', ' growing', ' small', ' again', '."', ' She', ' got', ' up', ' and', ' went', ' to', ' the', ' table', ' to', ' measure', ' herself', ' by', ' it', ',', ' and', ' found', ' that', ',', ' as', ' nearly', ' as', ' she', ' could', ' guess', ',', ' she', ' was', ' now', ' about', ' two', ' feet', ' high', ',', ' and', ' was', ' going', ' on', ' shrinking', ' rapidly', ':', ' soon', ' she', ' found', ' out', ' that', ' the', ' reason', ' of', ' it', ' was', ' the', ' nose', 'gay', ' she', ' held', ' in', ' her', ' hand', ':', ' she', ' dropped', ' it', ' hastily', ',', ' just', ' in', ' time', ' to', ' save', ' herself', ' from', ' shrinking', ' away', ' altogether', ',', ' and', ' found', ' that', ' she', ' was', ' now', ' only', ' three', ' inches', ' high', '.'] |
|
1 2 3 4 5 |
[ 2.49 0.22 -0.36 -1.55 0.22 -2.45 2.65 -1.6 -0.14 2.26 -1.26 -0.61 -0.61 -1.89 -1.87 -0.16 3.34 -2.67 0.42 -1.71 ... 2.91 -0.77 0.13 -0.24 0.63 -0.26 2.47 -1.22 -1.67 1.63 1.13 0.03 -0.68 0.8 1.88 3.05 -0.82 0.09 0.48 0.33] |
上下文向量就像整个输入的精髓。使用这个向量,Transformer解码器根据线索生成输出。例如,您可以将原始输入作为线索,让Transformer解码器生成自然紧随其后的下一个单词。然后,您可以重复使用相同的解码器,但这次线索将是之前生成的下一个单词。这个过程可以重复,从一个引导句开始,创建一整段。
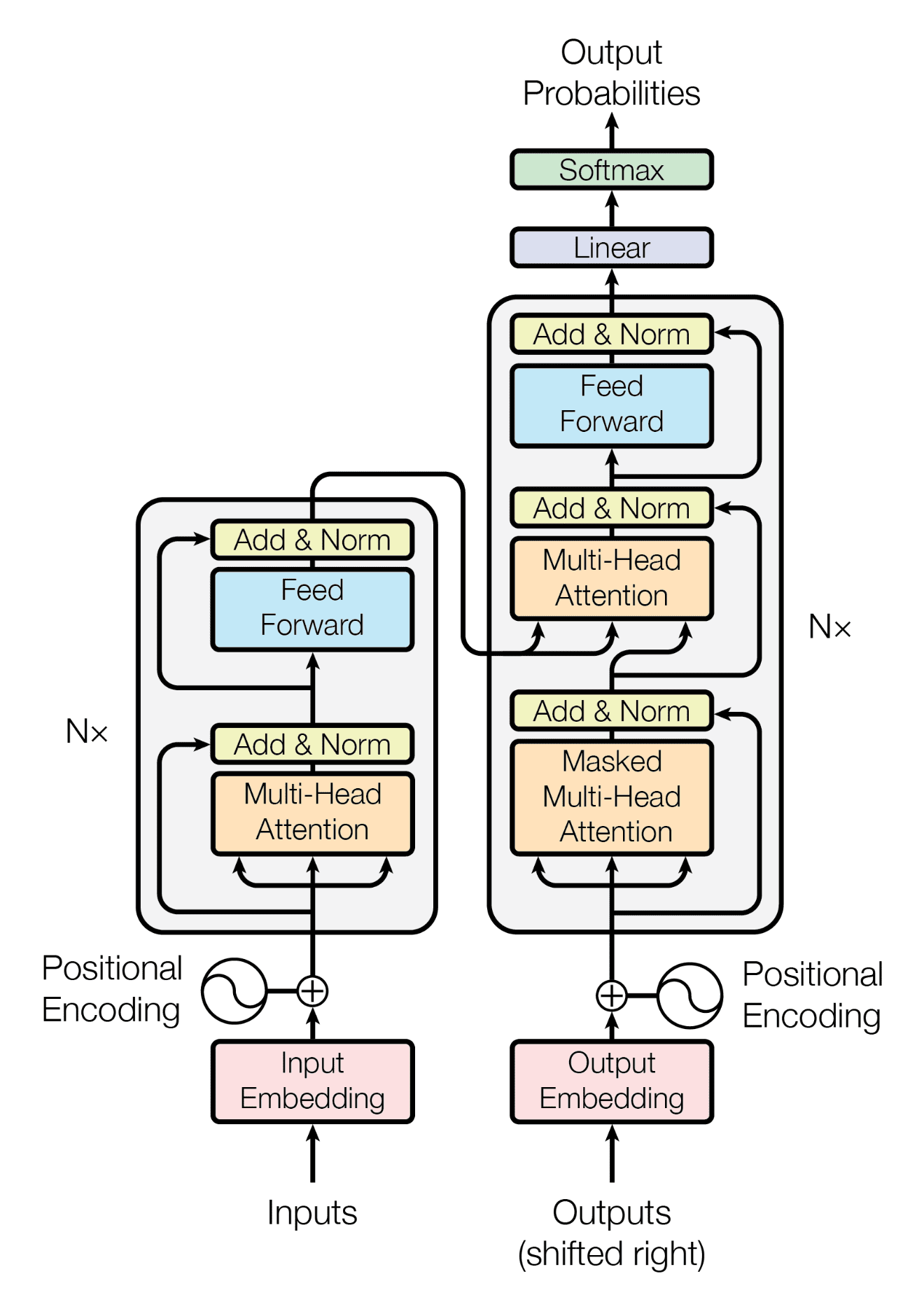
Transformer架构
这个过程称为自回归生成。这就是大型语言模型的工作原理,只不过这种模型是一个可以接受很长输入文本的Transformer模型,上下文向量很大,因此可以处理非常复杂的概念,并且其编码器和解码器具有许多层。
为什么Transformer可以预测文本?
Andrej Karpathy在他的博客文章《循环神经网络的非凡有效性》中证明,循环神经网络可以相当好地预测文本的下一个单词。这不仅因为人类语言中存在限制单词在句子不同位置使用的规则(即语法),还因为语言中存在冗余。
根据克劳德·香农(Claude Shannon)有影响力的论文《印刷英语的预测与熵》,英语的熵为每字母2.1比特,尽管有27个字母(包括空格)。如果字母是随机使用的,熵将是4.8比特,这使得预测人类语言文本中接下来出现的内容更容易。机器学习模型,特别是Transformer模型,擅长进行此类预测。
通过重复这个过程,Transformer模型可以逐字生成整个段落。然而,Transformer模型眼中的语法是什么?本质上,语法表示单词在语言中的使用方式,将它们归类为不同的词性,并要求在句子中遵循特定的顺序。尽管如此,列举所有语法规则是具有挑战性的。实际上,Transformer模型并没有明确存储这些规则,而是通过示例隐式地学习它们。模型可能不仅可以学习语法规则,还可以扩展到这些示例中提出的思想,但Transformer模型必须足够大。
大型语言模型是如何构建的?
大型语言模型是大型规模的Transformer模型。它如此之大,以至于通常无法在单台计算机上运行。因此,它自然是通过API或Web界面提供的服务。正如您所预期的那样,这种大型模型在能够记住语言的模式和结构之前,需要从大量的文本中进行学习。
例如,支持ChatGPT服务的GPT-3模型是在互联网上的海量文本数据上训练的。这包括书籍、文章、网站和各种其他来源。在训练过程中,模型学习单词、短语和句子之间的统计关系,使其能够在给定提示或查询时生成连贯且上下文相关的响应。
从如此大量的文本中提炼,GPT-3模型因此可以理解多种语言,并掌握各种主题的知识。这就是它能够生成不同风格文本的原因。虽然您可能会对大型语言模型能够执行翻译、文本摘要和问答感到惊讶,但如果您认为这些是与引导文本(即提示)匹配的特殊“语法”,那就不足为奇了。
总结
目前已经开发了多种大型语言模型。例如,OpenAI的GPT-3和GPT-4,Meta的LLaMA,以及Google的PaLM2。这些模型能够理解语言并生成文本。在这篇文章中,您了解到:
- 大型语言模型基于Transformer架构
- 注意力机制使LLM能够捕捉词语之间的长程依赖关系,从而使模型能够理解上下文
- 大型语言模型基于先前生成的词元自回归地生成文本
利用 ChatGPT 最大化你的生产力!

让生成式 AI 助您更智能地工作
...通过利用 ChatGPT、Google Bard 和许多其他在线工具的先进 AI 力量
在我的新电子书中探索如何实现
使用 ChatGPT 最大化生产力
它提供了各种类型的出色提示和示例,让你成为 AI 机器人的老板
用于头脑风暴、编辑、专家助手、翻译器等等...






感谢您让这一切变得如此简单易懂!
嗨 Carrie... 我们感谢您的支持和反馈!
非常感谢。我是一名医疗专业人士,但由于您努力简化复杂内容,我对LLM有了一定程度的理解。
因为您努力简化复杂内容。
非常欢迎!您可以通过此资源深入了解
https://machinelearning.org.cn/productivity-with-chatgpt/
很容易理解。谢谢!
感谢您的反馈和支持,Hyejeong!我们很感激!
我正在写一篇关于大型语言模型的大学论文,我一定会引用您的文章,因为您把它解释得太清楚了,我完全能理解。作为未来的BSCS毕业生,我相信LLM是未来,并将最终改变我们对“成为人类”的看法。我绝对想在我仅有的一点空闲时间里多了解这些东西。
感谢您的反馈,Derek!请订阅我们的时事通讯,以确保您能收到与此主题相关的额外内容通知!
https://machinelearning.org.cn/newsletter/
LLM真的很容易理解。谢谢。
感谢您的反馈和支持,jack!我们很感激!
LLM真的很容易理解。谢谢。
非常欢迎您,Arvindra!我们感谢您的反馈!
干得真好。谢谢!
非常欢迎您,Carolina!请随时向我们汇报您的进展!