词嵌入是一种词表示形式,它允许具有相似含义的词拥有相似的表示。
它们是文本的一种分布式表示,这可能是深度学习方法在具有挑战性的自然语言处理问题上取得令人印象深刻的性能的关键突破之一。
在这篇文章中,您将了解词嵌入方法如何表示文本数据。
完成这篇文章后,您将了解:
- 词嵌入文本表示方法是什么,以及它与其他特征提取方法有何不同。
- 有3种主要算法用于从文本数据中学习词嵌入。
- 您
可以训练新的嵌入,也可以在您的自然语言处理任务中使用预训练的嵌入。
通过我的新书《深度学习在自然语言处理中的应用》启动您的项目,包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

什么是文本的词嵌入?
图片由Heather提供,保留部分权利。
概述
这篇文章分为3个部分;它们是
- 什么是词嵌入?
- 词嵌入算法
- 使用词嵌入
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
什么是词嵌入?
词嵌入是一种学习到的文本表示形式,其中具有相同含义的词拥有相似的表示。
正是这种表示词和文档的方法,被认为是深度学习在具有挑战性的自然语言处理问题上取得的关键突破之一。
使用密集且低维向量的好处之一是计算方面:大多数神经网络工具包对非常高维、稀疏的向量表现不佳。……密集表示的主要好处是泛化能力:如果我们认为某些特征可能提供相似的线索,那么提供一种能够捕捉这些相似性的表示是值得的。
——《自然语言处理中的神经网络方法》第92页,2017年。
词嵌入实际上是一类技术,其中单个词被表示为预定义向量空间中的实值向量。每个词被映射到一个向量,并且向量值以类似于神经网络的方式学习,因此该技术通常被归入深度学习领域。
该方法的关键思想是为每个词使用密集的分布式表示。
每个词由一个实值向量表示,通常是几十或几百维。这与稀疏词表示(如独热编码)所需的数千或数百万维形成对比。
将词汇表中的每个词与一个分布式词特征向量关联起来……特征向量代表词的不同方面:每个词都与向量空间中的一个点相关联。特征数量……远小于词汇表的大小
——《一种神经概率语言模型》,2003年。
分布式表示是根据词的使用方式学习的。这使得以相似方式使用的词能够产生相似的表示,自然地捕捉它们的含义。这与词袋模型中清晰但脆弱的表示形成对比,在该模型中,除非明确管理,否则不同的词具有不同的表示,无论它们如何使用。
这种方法背后有更深层次的语言学理论,即Zellig Harris的“分布假说”,可以概括为:具有相似上下文的词将具有相似的含义。更深入的讨论请参见Harris 1956年的论文“分布结构”。
这种让词的使用定义其含义的观念可以用约翰·弗斯经常重复的一句话来概括:
你将通过其所伴随的词来认识一个词!
——《语言学理论概要1930-1955》第11页,《语言分析研究1930-1955》,1962年。
词嵌入算法
词嵌入方法从文本语料库中为预定义的固定大小词汇表学习实值向量表示。
学习过程要么与神经网络模型在某些任务(如文档分类)上联合进行,要么是一个无监督过程,使用文档统计数据。
本节回顾了三种可用于从文本数据中学习词嵌入的技术。
1. 嵌入层
嵌入层(姑且称之为嵌入层)是一种词嵌入,它与神经网络模型在特定的自然语言处理任务上联合学习,例如语言建模或文档分类。
它要求文档文本经过清洗和准备,以便每个词都进行独热编码。向量空间的大小作为模型的一部分指定,例如50、100或300维。向量用小的随机数初始化。嵌入层用作神经网络的前端,并使用反向传播算法以监督方式进行拟合。
……当神经网络的输入包含符号分类特征(例如,从封闭词汇表中获取k个不同符号之一的特征,例如词)时,通常将每个可能的特征值(即词汇表中的每个词)与某个d维向量关联起来。这些向量随后被视为模型的参数,并与其他参数一起训练。
——《自然语言处理中的神经网络方法》第49页,2017年。
独热编码的词被映射到词向量。如果使用多层感知器模型,则词向量在作为模型输入之前被连接起来。如果使用循环神经网络,则每个词可以作为序列中的一个输入。
这种学习嵌入层的方法需要大量的训练数据并且可能很慢,但它将学习到针对特定文本数据和NLP任务的嵌入。
2. Word2Vec
Word2Vec是一种统计方法,用于从文本语料库中高效地学习独立的词嵌入。
它由Tomas Mikolov等人于2013年在Google开发,旨在提高基于神经网络的嵌入训练效率,此后成为开发预训练词嵌入的事实标准。
此外,这项工作还涉及对学习到的向量的分析以及对词表示的向量运算的探索。例如,从“King”中减去“男性特质”并加上“女性特质”会得到“Queen”一词,捕捉了“国王之于女王,如男性之于女性”的类比。
我们发现这些表示在捕捉语言中的句法和语义规律方面表现出惊人的良好,并且每种关系都由一个特定于关系的向量偏移量来表征。这允许基于词之间偏移量的向量导向推理。例如,男性/女性关系是自动学习的,并且通过诱导的向量表示,“国王 - 男性 + 女性”会产生一个非常接近“女王”的向量。
——《连续空间词表示中的语言规律性》,2013年。
引入了两种不同的学习模型,可以作为word2vec方法的一部分来学习词嵌入;它们是:
- 连续词袋模型(Continuous Bag-of-Words,CBOW)。
- 连续跳字模型(Continuous Skip-Gram Model)。
CBOW模型通过根据上下文预测当前词来学习嵌入。连续跳字模型通过给定当前词预测周围词来学习。
连续跳字模型通过给定当前词预测周围词来学习。
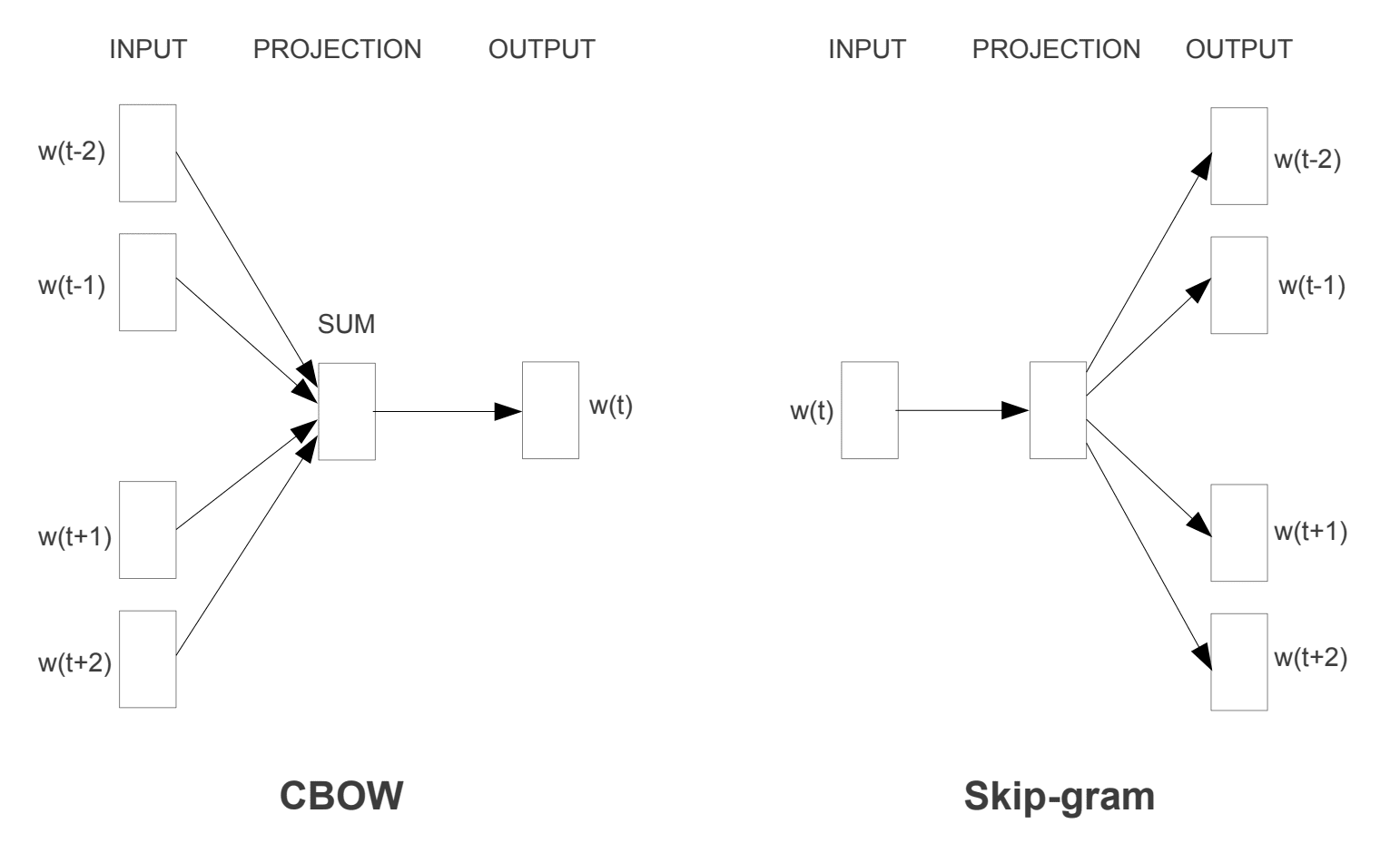
Word2Vec 训练模型
摘自《向量空间中词表示的有效估计》,2013年
这两个模型都侧重于学习基于词的局部使用上下文的词,其中上下文由相邻词的窗口定义。这个窗口是模型的一个可配置参数。
滑动窗口的大小对结果向量相似性有强烈影响。大窗口往往会产生更多的主题相似性[…], 而小窗口往往会产生更多的功能和句法相似性。
——《自然语言处理中的神经网络方法》第128页,2017年。
这种方法的关键优势在于可以高效地学习高质量的词嵌入(低空间和时间复杂度),从而允许从更大的文本语料库(数十亿词)中学习更大的嵌入(更多维度)。
3. GloVe
GloVe(Global Vectors for Word Representation)算法是Word2Vec方法的一种扩展,用于高效学习词向量,由斯坦福大学的Pennington等人开发。
经典的词向量空间模型表示是使用矩阵分解技术(如潜在语义分析LSA)开发的,这些技术在利用全局文本统计方面做得很好,但在捕捉含义和在计算类比(例如上面国王和女王的例子)等任务上表现不如Word2Vec等学习方法。
GloVe 是一种将矩阵分解技术(如 LSA)的全局统计与 Word2Vec 中基于局部上下文的学习相结合的方法。
GloVe 不使用窗口来定义局部上下文,而是通过使用整个文本语料库的统计数据构建一个显式的词-上下文或词共现矩阵。结果是一个学习模型,可能会产生普遍更好的词嵌入。
GloVe 是一种新的全局对数双线性回归模型,用于词表示的无监督学习,它在词类比、词相似度和命名实体识别任务上优于其他模型。
——《GloVe:词表示的全局向量》,2014年。
使用词嵌入
在您的自然语言处理项目中使用词嵌入时,您有一些选择。
本节概述了这些选项。
1. 学习嵌入
您可以选择为您的问题学习词嵌入。
这将需要大量的文本数据,以确保学习到有用的嵌入,例如数百万或数十亿个词。
训练词嵌入时,您有两个主要选择:
- 独立学习,即训练一个模型来学习嵌入,然后保存并作为另一个模型的组件用于您的任务。如果您想在多个模型中使用相同的嵌入,这是一个很好的方法。
- 联合学习,即嵌入作为大型任务特定模型的一部分学习。如果您只打算在一个任务上使用嵌入,这是一个很好的方法。
2. 重用嵌入
研究人员通常会免费提供预训练的词嵌入,通常在宽松的许可下,以便您可以在自己的学术或商业项目中使用它们。
例如,Word2Vec 和 GloVe 词嵌入都可免费下载。
您可以在项目中使用它们,而不是从头开始训练自己的嵌入。
在使用预训练嵌入时,您有两个主要选择:
- 静态,即嵌入保持静态,并用作模型的组件。如果嵌入非常适合您的问题并能提供良好结果,这是一种合适的方法。
- 更新,即使用预训练嵌入来初始化模型,但在模型训练期间联合更新嵌入。如果您希望在任务中充分利用模型和嵌入,这可能是一个不错的选择。
您应该选择哪种方案?
探索不同的选项,如果可能,测试哪种能在您的问题上获得最佳结果。
或许可以从快速方法开始,比如使用预训练的嵌入,只有当新嵌入在您的问题上带来更好的性能时才使用。
词嵌入教程
本节列出了一些您可以遵循的分步教程,以使用词嵌入并将词嵌入引入您的项目。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
文章
- 维基百科上的词嵌入
- 维基百科上的Word2vec
- 维基百科上的GloVe
- 词嵌入及其与分布式语义模型的联系概述, 2016.
- 深度学习、自然语言处理和表示, 2014.
论文
- 分布结构, 1956.
- 一个神经概率语言模型, 2003.
- 一种统一的自然语言处理架构:带有多任务学习的深度神经网络, 2008.
- 连续空间语言模型, 2007.
- 向量空间中词表示的有效估计, 2013
- 词和短语的分布式表示及其组合性, 2013.
- GloVe:用于词语表示的全局向量, 2014.
项目
书籍
- 自然语言处理中的神经网络方法, 2017.
总结
在这篇文章中,您了解了词嵌入作为深度学习应用程序中文本的一种表示方法。
具体来说,你学到了:
- 词嵌入文本表示方法是什么,以及它与其他特征提取方法有何不同。
- 有3种主要算法用于从文本数据中学习词嵌入。
- 您可以训练新的嵌入,也可以在您的自然语言处理任务中使用预训练的嵌入。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






感谢您的简化和更好的解释
很高兴它有帮助。
好文章。我正在使用预训练的词嵌入来开发聊天机器人模型。我遇到一个问题,我相信您也遇到过同样的问题,即如何在文本中编码数字,例如1或2017,或者更糟糕的是,像1.847440343这样的数字,这在预训练词嵌入的字典中不太可能出现?
有什么建议吗?
在许多情况下,我看到数字从文本数据中被移除。
这可能是一个很好的第一步,以便让一些东西开始工作。
好文章,以及关于NLP中NN方法的书籍链接。我打算买它。
但我有一个问题,词嵌入算法如何应用于文本流中检测新兴趋势(或仅趋势分析)?是否可以使用?有没有相关的论文或链接?
抱歉,我没有见过这种用例。也许可以在Google学术上搜索一下。
词嵌入的精确介绍!非常感谢
很高兴它有帮助!
简单地说,您是最棒的。您有将非常复杂的概念解释得更简单的才能。万分感谢您的所有著作。我正计划购买您的一些书籍,但我需要先弄清楚我需要什么。再次感谢!
非常感谢,穆罕默德!坚持住。
感谢您对NLP中词嵌入的精确解释,到目前为止我一直专注于深度学习在图像和音频等密集数据上的应用,现在我学习了一些如何将稀疏文本数据转换为密集低维向量的基础知识,所以感谢您让我进入NLP的世界。
很高兴它有帮助。
关于处理数字,一个选择可能是将它们转换为文本,例如1 = one等。
好建议,彼得。
有没有使用Glove或Word2vec进行句子嵌入的方法?
也许有,但我没有使用过,抱歉。可以尝试谷歌搜索一下。
这对我来说是一篇非常有用的文章。您以简单易懂的方式解释了几乎所有关键点。我的许多疑问都得到了解答。
非常感谢,继续保持!
谢谢,很高兴对您有帮助。
大家好
贾森先生,我阅读了您的文章,确实从中学到了很多信息,您能解释一下句子级别的情感分析吗?
这篇文章将帮助您入门
https://machinelearning.org.cn/develop-word-embedding-model-predicting-movie-review-sentiment/
感谢您的解释。
我有一个问题。维度到底是什么意思?
起初,我以为单词的每个字母代表一个维度,但想到一百个维度……?!
你能帮我解答一下吗?
具体在什么语境下?抱歉我没明白。
在这篇目前的文章中。就像这里说的:“每个词都由一个实值向量表示,通常是几十或几百维。这与稀疏词表示(如独热编码)所需的数千或数百万维形成对比。”
我不明白您说的维度是什么意思
向量中的每个元素都是一个新的维度。
谢谢你
这些元素只是像男性气质、年龄等特征吗?什么决定选择哪个特征呢?
感谢您的文章,我从中受益匪浅。
关于您在嵌入层部分引用的词,我有一个问题。为什么嵌入层的权重可以被视为独热编码词的词向量?在我看来,权重只是模型的参数,它们不承载任何来自原始输入的信息。
它们是一种一致的表示。每个词都映射到连续空间中的一个向量,其中词之间的关系(含义)得以表达。
感谢您写了一篇好文章,简单明了。
一个快速问题:词嵌入可以用于从文本文档中提取信息吗?如果可以,您有什么好的参考资料可以推荐吗?
谢谢。
具体是哪方面?
最简单的形式是指:总结对某个特定问题的回答。
是的,我相信你问的是“文本摘要”。你可以在这里了解更多
https://machinelearning.org.cn/?s=text+summarization&post_type=post&submit=Search
嗨
您能否详细说明一下“文档统计”在下面这句话中的确切含义(它到底是什么)
学习过程要么与神经网络模型在某些任务(如文档分类)上联合进行,要么是一个无监督过程,使用文档统计数据。
通常Word2Vec和GloVe都是无监督学习,对吗?相反,监督学习中词嵌入的一个示例用法是垃圾邮件检测,对吗?
谢谢
文档统计只意味着词的使用方式——排序的统计。
是也不是。词嵌入是“无监督”的,但实际上是使用一种巧妙的监督学习问题进行训练的。
好文章!谢谢!
是否可以将两个预训练的词嵌入进行拼接(合并),这两个嵌入由不同的文本语料库训练,并且维度数量也不同?这样做有意义吗?
是的,如果嵌入中存在不同的词。对于相同的词则不行。
嗨~我有一个问题。现在我想做的是估计两个嵌入向量之间的相似性。如果这两个向量是从相同的数据集中嵌入的,点积可以用来计算相似性。但是,如果这两个向量是从不同的数据集中嵌入的,点积可以用来计算相似性吗?
您可以使用向量范数(例如L1或L2)来计算任意两个向量之间的距离,无论其来源如何。
非常感谢您,布朗利博士。您的解释非常清晰和有帮助
谢谢,很高兴对您有帮助。
亲爱的Jason,感谢您精彩的帖子。
我需要在我的论文中数学地解释Keras的词嵌入层。我知道Keras会随机初始化嵌入向量,然后使用程序员指定的优化器更新参数。是否有任何论文详细解释了该方法以供引用?
是的,这里有API文档中的链接
https://keras.org.cn/layers/embeddings/
感谢您对像我这样NLP新手清晰明了地解释词嵌入。也感谢您提供的链接
谢谢,很高兴对您有帮助。
你好,我有一个问题。假设我想使用词嵌入(100维)与逻辑回归。我的特征是推特。我想将它们编码成一个有100列的数组。推特不仅仅是词,而是包含可变数量词的句子。我如何使每个句子具有相同数量的列?
-> 句子中每个词的向量平均值,
-> 句子中每个词的向量总和?
可能有一些更智能的方法来聚合它们,使其不失去语义?
提前感谢您的回复。
噢,逻辑回归可能不适合这个。
尽管如此。一个样本或一条推文是多个词。每个词都被转换为一个向量,然后这些向量被连接起来作为模型的长输入。
更好的方法是使用支持序列的模型,例如RNN或1D CNN。
你好Jason,感谢您的回复。实际上,我在这里对逻辑回归不感兴趣 🙂 我更想了解如何编码不同长度的文本,使其具有相同的向量长度,并可以输入到任何机器学习算法中。
至于您提到的向量连接,我在这里看到了问题。
假设我第一句话(推文)有5个词,那么连接后我将得到长度为500的向量。
假设另一句话(推文)有10个词,那么编码和连接后我将得到长度为1000的向量。
所以我不能一起使用这些向量,因为它们长度不同(表格中的列数不同),所以算法无法处理它们。
可能我误解了词嵌入的概念,并试图将其视为词袋模型:) 您能给我一些关于我问题的阅读材料吗?因为我感觉即使阅读了您博客上的几篇文章,我仍然没有找到我的问题的答案。
谢谢!
罗斯
是的,通常我们会选择一个固定长度,然后修剪或填充所有示例使其长度相同,然后进行编码
https://machinelearning.org.cn/data-preparation-variable-length-input-sequences-sequence-prediction/
我建议使用词嵌入,它涉及将词编码为数字,然后将其作为输入提供给嵌入层,再通过CNN。
https://machinelearning.org.cn/best-practices-document-classification-deep-learning/
非常感谢!
嗨,Jason,
用于分类的嵌入网络,它是否只与文本和词处理相关,还是可以应用于其他上下文?如果是这种情况,您推荐我阅读哪些文章和论文来了解更多关于这些应用的信息。
先谢谢您了。
嵌入可以用来建模任何分类数据,而不仅仅是文本。
我希望很快会有一些关于这方面的教程。
我希望如此。
我不在这个领域,数学技能生疏。您能解释一下典型向量空间中每个维度代表什么样的信息吗?我的直觉是,减少维度以获得计算优势,会灾难性地限制可以记录的含义。显然,我错了!这希望能说明我对向量空间中向量如何存储信息的困惑。
谢谢!
与词相比,它的维度增加了,与独热编码相比,维度减少了。
这种表示将“相似”的词分组到向量空间中。
词嵌入与使用独热编码词作为单个特征的PCA有什么不同?
它们非常不同。
PCA消除线性依赖。
嵌入是一种分布式表示。
太棒了!!!
谢谢。
嗨,Jason,
我很高兴我找到了您的网站!您解释词嵌入的方式简单易懂,让概念变得清晰。
我有一个关于使用深度学习进行NER的问题。目前我正在开发一个NER系统,它使用词嵌入来表示语料库,然后使用深度学习来提取命名实体。我想知道您的网站上是否有资源或教程可以帮助我使用Python澄清这个想法,或者至少指导我可以在哪里找到关于我主题的有用资源。
提前非常感谢。
迪娜
谢谢,迪娜!
抱歉,我没有NER的教程,我无法立即给出好的建议。
没关系。再次万分感谢 🙂
嗨!从上面我了解到嵌入是单词的数值表示,并且所有向量的维度都相同。
我的问题是,所有的单词都有相同的维度名称(列名)还是因单词而异?
所有词都具有相同数量的维度(具有相同元素数量的向量,例如100)。
亲爱的 Jason,
感谢您的精彩帖子。
我想问,我们能否将嵌入用于程序语言建模以进行代码生成或预测?
在这种情况下,使用嵌入层或word2vec有什么好处吗?
是的。
是的,学习到的嵌入很可能比其他方法更好地表示输入中的符号。
感谢Jason您的回复,
我想澄清一下,有一个用例是生成代码片段之间缺失的代码,研究人员已经在代码模型上使用了嵌入。
但是,我想解决一个基于用户先前的输入来预测下一个令牌的问题。
对于这个问题,我需要您的建议,应用嵌入和双向LSTM会有什么好处吗?
也许可以尝试一下,并将结果与其他方法进行比较?
嗨 Jason
谢谢您!阅读您的文章非常有益。
是否有可能为不同语料库训练多个词嵌入模型,以便比较语料库之间的各种嵌入?请记住它们来自同一个领域,唯一的区别是作者特征。
如果可以,您对如何实现这一点有什么初步想法吗?
我很高兴它有用。
是的,也许可以尝试一下,并将其用作多输入模型的输入。
非常感谢,学习词嵌入这个概念对我很有帮助。
再次感谢您。
不客气,我很高兴听到这个消息。
杰森,文章写得太棒了!
我正在尝试为特定主题的词生成词嵌入,但语料库不够大,无法训练。
参考第2节“重用嵌入”,我认为第2点“更新”(预训练嵌入用于初始化模型…)可能是我正确的选择。
您能分享一些关于如何使用有限语料库更新预先存在的特定词模型的方法吗?
Google预训练
https://code.google.com/archive/p/word2vec/
Glove预训练
https://nlp.stanford.edu/projects/glove/
嗨 Jason,感谢您的这篇文章!
据您所知,除了独热编码、tokenizer API 和 Word2Vec 之外,还有其他词嵌入算法吗?
是的,您可以使用独立的Word2Vec或GloVe等方法,或者直接将嵌入作为模型的一部分进行学习。
你好,
感谢您的精彩教程!
BERT和xLNET也是预训练的词嵌入,我们可以用于我们的模型吗?
BERT是一个预训练的语言模型。
感谢您对嵌入概念和方法进行了精彩、全面且简化的解释。
不客气!
你好,
好文章!!
我有一个疑问,我们能否使用通过word2vec获得的词嵌入并将其作为一组特征传递给机器学习模型?
实际上,我正在处理一个多类别分类问题。之前我使用了CountVectorizer和TfidfTransformer作为特征提取方法。我能否改用word2vec并将它传递给SVM模型?
谢谢!
当然可以。
亲爱的杰森,您好,
首先,我要感谢您这篇精彩的文章,
其次,我有一个问题,
如果我想对历史等特定领域进行有监督的多类别分类,并使用深度学习技术之一。我应该使用哪种词嵌入技术最好?
1- 基于连续词袋模型的Word2vec,
2- 基于连续跳字模型的Word2vec,
3- Glove。
非常感谢……
不客气。
我们无法先验得知。
也许可以尝试用你的数据集对每个方法进行测试,并使用能够带来最佳模型性能的方法。
杰森,您真是“牛人”!!非常感谢您,好人!每当我在机器学习方面有任何问题,或者不理解任何东西,或者某些东西不清楚时,我总会来这里找到一个好的、易懂的答案。
再次感谢。
谢谢!
嗨,Jason,
感谢您的文章,我从中受益匪浅。
我想使用NLP将关于RISK的报告分类为高风险或低风险。
我不知道您是否能推荐任何词嵌入字典或库(基于庞大语料库预训练的,像一个查找表,可能需要付费)。通过使用它,那些含义相似的词具有相似的表示(关于RISK,从最消极的含义到最积极的含义)。
谢谢,杰克
不客气。
也许可以尝试直接将嵌入作为模型的一部分进行学习——根据我的经验,这可能会更有效。
我刚刚开始学习词嵌入,尝试使用FastText等现有的嵌入。您如何处理没有分配任何向量并返回空值的词?我担心将0分配来替换空值,或任何其他归因方法会产生错误的影響。
词汇表中没有的新词被编码为全零向量,例如“未知”。
这太不可思议了。在仔细阅读了您的解释之后,我发现我现在对词嵌入的理解比以前更少了。
感谢您的支持和反馈,Gabriel!我们非常感谢!