在语言模型文献中,您会经常遇到“零样本提示”和“少样本提示”这两个术语。了解大型语言模型如何生成输出非常重要。在本帖中,您将学到:
- 什么是零样本和少样本提示?
- 如何在 GPT4All 中进行实验

什么是零样本提示和少样本提示
图片由作者使用 Stable Diffusion 生成。保留部分权利。
开始使用并应用 ChatGPT,阅读我的书 《最大化 ChatGPT 的生产力》。该书提供了真实世界的用例和提示示例,旨在帮助您快速使用 ChatGPT。
让我们开始吧。
概述
这篇博文分为三部分;它们是:
- 大型语言模型如何生成输出?
- 零样本提示
- 少样本提示
大型语言模型如何生成输出?
大型语言模型通过海量文本数据进行训练。它们被训练来根据输入预测下一个词。研究发现,只要模型足够大,不仅可以学会人类语言的语法,还可以学会词语的含义、常识和基本逻辑。
因此,如果您将碎片化的句子“我的邻居的狗是”作为输入(也称为提示)提供给模型,它可能会预测出“聪明”或“小”,但不太可能预测出“顺序”,尽管这些都是形容词。同样,如果您向模型提供一个完整的句子,您可以期望模型的输出自然地跟随。重复地将模型的输出附加到原始输入并再次调用模型,可以使模型生成冗长的响应。
零样本提示
在自然语言处理模型中,零样本提示是指向模型提供未包含在训练数据中的提示,但模型可以生成您期望的结果。这项有前景的技术使大型语言模型在许多任务中都很有用。
为了理解为什么这很有用,可以想象一下情感分析的案例:您可以将不同观点的段落进行分类,并用情感分类进行标记。然后,您可以训练一个机器学习模型(例如,在文本数据上训练的 RNN)来接收段落作为输入并生成分类作为输出。但您会发现这样的模型适应性不强。如果您向分类添加一个新类别,或者要求不要对段落进行分类而是进行摘要,则必须修改和重新训练此模型。
然而,大型语言模型无需重新训练。如果您知道如何正确提问,您可以要求模型对段落进行分类或对其进行摘要。这意味着模型可能无法将段落分类到 A 或 B 类别,因为“A”和“B”的含义不明确。但是,它可以分类为“积极情感”或“消极情感”,因为模型知道“积极”和“消极”应该是什么意思。这是因为在训练过程中,模型学习了这些词的含义,并获得了遵循简单指令的能力。以下是一个使用 GPT4All 和 Vicuna-7B 模型演示的例子:
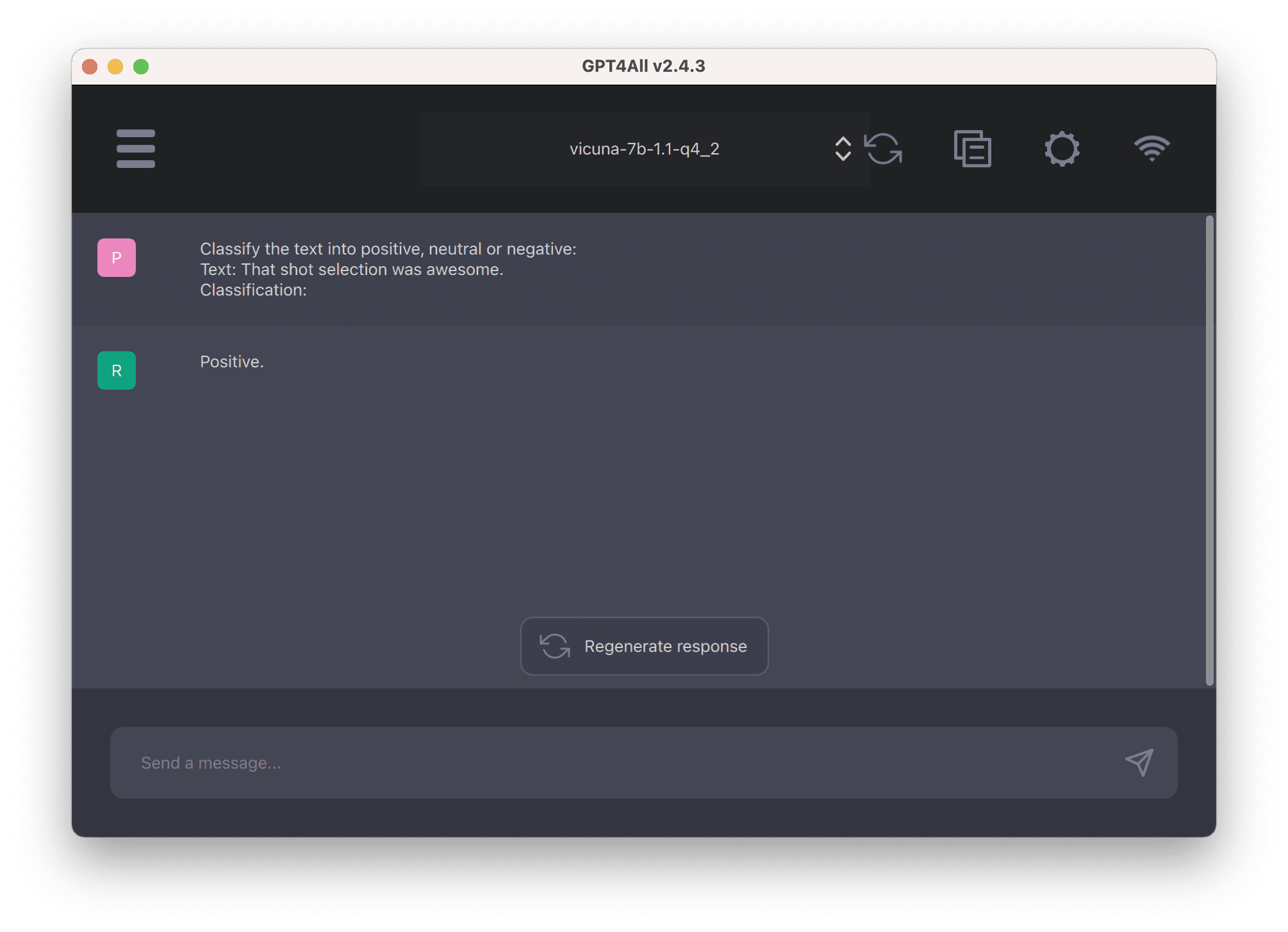
提供的提示是:
|
1 2 3 |
将文本分类为积极、中性或消极 文本:那个投篮选择太棒了。 分类 |
响应是一个词,“positive”。这是正确的且简洁的。模型显然可以理解“awesome”是一种积极的感受,但知道识别这种感受是因为开头的指令“将文本分类为积极、中性或消极”。
在这个例子中,您发现模型是因为理解了您的指令而做出响应的。
少样本提示
如果您无法描述您想要什么,但仍希望语言模型为您提供答案,您可以提供一些示例。用以下示例来说明会更容易:
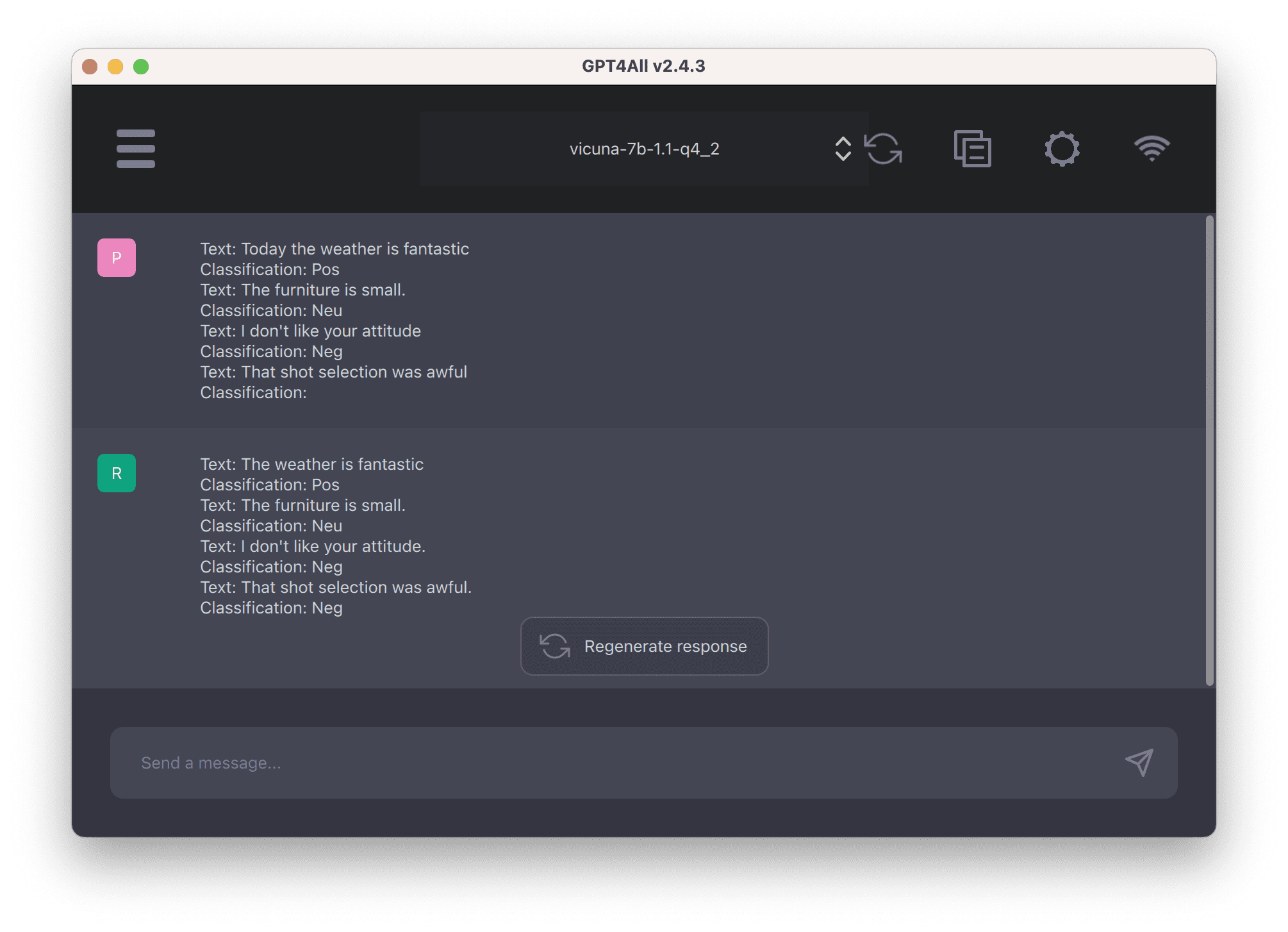
仍然使用 GPT4All 中的 Vicuna-7B 模型,但这次我们提供提示:
|
1 2 3 4 5 6 7 8 |
文本:今天天气真好 分类:Pos 文本:家具有点小。 分类:Neu 文本:我不喜欢你的态度 分类:Neg 文本:那个投篮选择太糟糕了 分类 |
在这里您可以看到,没有提供关于做什么的指令,但通过一些示例,模型可以弄清楚如何响应。另外,请注意,模型响应的是“Neg”而不是“Negative”,因为这正是示例中提供的。
注意:由于模型的随机性,您可能无法完全复现确切结果。每次运行模型时,您也可能会得到不同的输出。
通过示例引导模型响应称为少样本提示。
总结
在本帖中,您学习了一些提示的示例。具体来说,您学习了:
- 什么是单样本和少样本提示
- 模型如何处理单样本和少样本提示
- 如何使用 GPT4All 测试这些提示技术
利用 ChatGPT 最大化你的生产力!

让生成式 AI 助您更智能地工作
...通过利用 ChatGPT、Google Bard 和许多其他在线工具的先进 AI 力量
在我的新电子书中探索如何实现
使用 ChatGPT 最大化生产力
它提供了各种类型的出色提示和示例,让你成为 AI 机器人的老板
用于头脑风暴、编辑、专家助手、翻译器等等...






非常清晰的解释,让我再次有追随您的冲动!
谢谢。这对我很有帮助。但我还有两个问题。
首先,什么是零样本学习、少样本学习、单样本学习,你能给我一些例子吗?
其次,单样本学习和单样本提示有什么区别?
这让我困扰了很久,请帮我解决。
嗨 Summer…以下资源可能对您有帮助
https://towardsdatascience.com/zero-and-few-shot-learning-c08e145dc4ed