在本教程中,您将学习如何为复杂的优化问题实现**贝叶斯优化算法**。
全局优化是一个具有挑战性的问题,它需要在给定的目标函数中找到产生最小或最大成本的输入。
通常,目标函数的形式复杂且难以分析,并且通常是非凸的、非线性的、高维的、有噪声的,并且评估计算成本高昂。
贝叶斯优化提供了一种基于贝叶斯定理的原则性技术,可以指导对全局优化问题的搜索,使其高效且有效。它通过构建目标函数的概率模型(称为代理模型)来工作,然后通过一个采集函数来高效地搜索该模型,之后选择候选样本在真实目标函数上进行评估。
贝叶斯优化常用于应用机器学习中,以在验证数据集上调整给定表现良好的模型的超参数。
完成本教程后,您将了解:
- 全局优化是一个具有挑战性的问题,涉及黑盒优化,并且通常是非凸、非线性、有噪声且计算成本高昂的目标函数。
- 贝叶斯优化为全局优化提供了一种基于概率的原则性方法。
- 如何从头开始实现贝叶斯优化以及如何使用开源实现。
启动您的项目,阅读我的新书《机器学习概率》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- **2020年1月更新**:已针对 scikit-learn v0.22 API 的变更进行更新。

贝叶斯优化入门简介
照片作者:Beni Arnold,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 函数优化挑战
- 什么是贝叶斯优化
- 如何进行贝叶斯优化
- 使用贝叶斯优化进行超参数调优
函数优化挑战
全局函数优化,或简称函数优化,涉及找到目标函数的最小值或最大值。
从域中抽取样本,并通过目标函数进行评估,以给出得分或成本。
我们来定义一些常用术语
- 样本。来自域的一个示例,表示为一个向量。
- 搜索空间:可以从中抽取样本的域的范围。
- 目标函数。接受样本并返回成本的函数。
- 成本。通过目标函数计算出的样本的数值分数。
样本由一个或多个变量组成,通常易于设想或创建。一个样本通常被定义为一个具有预定范围的向量,存在于一个 n 维空间中。必须对该空间进行采样和探索,以找到导致最佳成本的变量值的特定组合。
成本通常具有特定于给定域的单位。优化通常描述为最小化成本,因为最大化问题可以通过反转计算出的成本轻松转化为最小化问题。一起,函数的最小值和最大值被称为函数的极值(或复数极值)。
目标函数通常易于指定,但计算起来可能在计算上具有挑战性,或者随时间产生有噪声的成本计算。目标函数的形状是未知的,并且通常是高度非线性的,由输入变量的数量定义的高维度的。该函数也可能是非凸的。这意味着局部极值可能等于或不等于全局极值(例如,可能具有误导性并导致过早收敛),因此该任务的名称为全局优化而非局部优化。
尽管对目标函数了解很少(已知需要寻找函数的最小或最大成本),因此,它通常被称为黑盒函数,搜索过程也称为黑盒优化。此外,目标函数有时被称为神谕(oracle),因为它只能提供答案。
函数优化是机器学习的基础。大多数机器学习算法涉及对模型参数(权重、系数等)进行优化,以响应训练数据。优化也指寻找配置机器学习算法训练的最佳超参数集的过程。再进一步,训练数据的选择、数据准备以及机器学习算法本身也是一个函数优化问题。
机器学习优化总结
- 算法训练。模型参数优化。
- 算法调优。模型超参数优化。
- 预测建模。数据、数据准备和算法选择的优化。
存在许多函数优化方法,例如随机采样变量搜索空间,称为随机搜索,或系统地在搜索空间中评估样本网格,称为网格搜索。
更原则性的方法能够从空间采样中学习,以便将未来的样本定向到最有可能包含极值的搜索空间部分。
一种使用概率进行全局优化的定向方法称为贝叶斯优化。
想学习机器学习概率吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
什么是贝叶斯优化
贝叶斯优化是一种使用贝叶斯定理来指导搜索以找到目标函数的最小值或最大值的方法。
这是一种对于复杂、有噪声和/或评估成本高昂的目标函数最有用的方法。
贝叶斯优化是一种强大的策略,用于寻找评估成本高昂的目标函数的极值。[...] 它在这些评估成本高昂、无法访问导数或手头问题是非凸时特别有用。
— 关于昂贵成本函数贝叶斯优化的教程,应用于主动用户建模和分层强化学习,2010。
回想一下,贝叶斯定理是一种计算事件条件概率的方法
- P(A|B) = P(B|A) * P(A) / P(B)
我们可以通过移除 P(B) 的归一化值来简化此计算,并将条件概率描述为比例量。这很有用,因为我们不关心计算特定的条件概率,而是优化一个量。
- P(A|B) = P(B|A) * P(A)
我们计算的条件概率通常被称为*后验*概率;反向条件概率有时被称为似然度,而边际概率被称为*先验*概率;例如
- 后验 = 似然度 * 先验
这提供了一个框架,可用于量化在给定域样本并通过目标函数进行评估的情况下,对未知目标函数的信念。
我们可以设计特定的样本(x1, x2, ..., xn)并使用目标函数 f(xi) 对它们进行评估,该函数返回样本 xi 的成本或结果。样本及其结果按顺序收集并定义我们的数据 D,例如 D = {xi, f(xi), … xn, f(xn)},并用于定义先验。似然函数定义为在给定函数 P(D | f) 的情况下观察数据的概率。此似然函数会随着收集到更多观测值而改变。
- P(f|D) = P(D|f) * P(f)
后验代表我们关于目标函数的一切知识。它是目标函数的近似值,可用于估计我们可能想要评估的不同候选样本的成本。
这样,后验概率就是代理目标函数。
后验捕获了关于未知目标函数更新后的信念。也可以将贝叶斯优化的此步骤解释为使用代理函数(也称为响应面)来估计目标函数。
— 关于昂贵成本函数贝叶斯优化的教程,应用于主动用户建模和分层强化学习,2010。
- 代理函数:目标函数的贝叶斯近似,可以被高效地采样。
代理函数为我们提供了目标函数的估计值,可用于指导未来的采样。采样涉及仔细使用后验函数,该函数称为“*采集*”函数,例如为了获取更多样本。我们希望利用我们对目标函数的信念来采样最有可能产生回报的搜索空间区域,因此采集函数将优化搜索位置的条件概率,以生成下一个样本。
- 采集函数:一种通过后验选择搜索空间中的下一个样本的技术。
一旦收集了额外的样本及其通过目标函数 f() 的评估,它们将被添加到数据 D 中,然后更新后验。
重复此过程,直到找到目标函数的极值、找到足够好的结果或资源耗尽。
贝叶斯优化算法可以总结如下:
- 1. 通过优化采集函数选择一个样本。
- 2. 使用目标函数评估样本。
- 3. 更新数据,进而更新代理函数。
- 4. 转到 1。
如何进行贝叶斯优化
在本节中,我们将通过从头开始为一个简单的单维测试函数开发实现来探讨贝叶斯优化如何工作。
首先,我们将定义测试问题,然后介绍如何使用代理函数对输入到输出的映射进行建模。接下来,我们将了解如何使用采集函数高效地搜索代理函数,最后将所有这些元素整合到贝叶斯优化过程中。
测试问题
第一步是定义一个测试问题。
我们将使用一个具有五个峰的多峰问题,计算方法如下:
- y = x^2 * sin(5 * PI * x)^6
其中 x 是 [0,1] 范围内的实数值,PI 是 pi 的值。
我们将通过添加均值为零、标准差为 0.1 的高斯噪声来增强此函数。这意味着实际评估将添加一个正值或负值的随机值,使函数难以优化。
下面的 objective() 函数实现了这一点。
|
1 2 3 4 |
# 目标函数 def objective(x, noise=0.1): noise = normal(loc=0, scale=noise) return (x**2 * sin(5 * pi * x)**6.0) + noise |
我们可以通过首先定义一个从 0 到 1 的网格采样输入,步长为 0.01 来测试此函数。
|
1 2 3 |
... # 域 [0,1] 的网格采样 X = arange(0, 1, 0.01) |
然后,我们可以在不添加噪声的情况下使用目标函数评估这些样本,以查看真实的目标函数是什么样的。
|
1 2 3 |
... # 无噪声采样域 y = [objective(x, 0) for x in X] |
然后,我们可以使用噪声评估相同的点,以查看在优化目标函数时它将是什么样的。
|
1 2 3 |
... # 带噪声采样域 ynoise = [objective(x) for x in X] |
我们可以查看所有无噪声的目标函数值,找到产生最佳得分的输入并报告它。这将是极值,在本例中是最大值,因为我们正在最大化目标函数的输出。
在实践中,我们不会知道这一点,但对于我们的测试问题来说,了解函数实际的最佳输入和输出以查看贝叶斯优化算法是否能找到它,这是很有好处的。
|
1 2 3 4 |
... # 查找最佳结果 ix = argmax(y) print('Optima: x=%.3f, y=%.3f' % (X[ix], y[ix])) |
最后,我们可以创建一个图,首先显示带噪声的评估作为散点图,其中输入在 x 轴上,得分在 y 轴上,然后显示没有噪声的得分的线图。
|
1 2 3 4 5 6 7 |
... # 绘制带噪声的点 pyplot.scatter(X, ynoise) # 绘制无噪声的点 pyplot.plot(X, y) # 显示绘图 pyplot.show() |
下面列出了回顾我们想要优化的测试函数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 测试问题示例 from math import sin from math import pi from numpy import arange from numpy import argmax from numpy.random import normal from matplotlib import pyplot # 目标函数 def objective(x, noise=0.1): noise = normal(loc=0, scale=noise) return (x**2 * sin(5 * pi * x)**6.0) + noise # 域 [0,1] 的网格采样 X = arange(0, 1, 0.01) # 无噪声采样域 y = [objective(x, 0) for x in X] # 带噪声采样域 ynoise = [objective(x) for x in X] # 查找最佳结果 ix = argmax(y) print('Optima: x=%.3f, y=%.3f' % (X[ix], y[ix])) # 绘制带噪声的点 pyplot.scatter(X, ynoise) # 绘制无噪声的点 pyplot.plot(X, y) # 显示绘图 pyplot.show() |
运行该示例,首先报告全局极值为输入值为 0.9,得分 0.81。
|
1 |
Optima: x=0.900, y=0.810 |
然后创建一个图,显示样本的带噪声评估(点)和目标函数的无噪声真实形状(线)。
注意:鉴于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
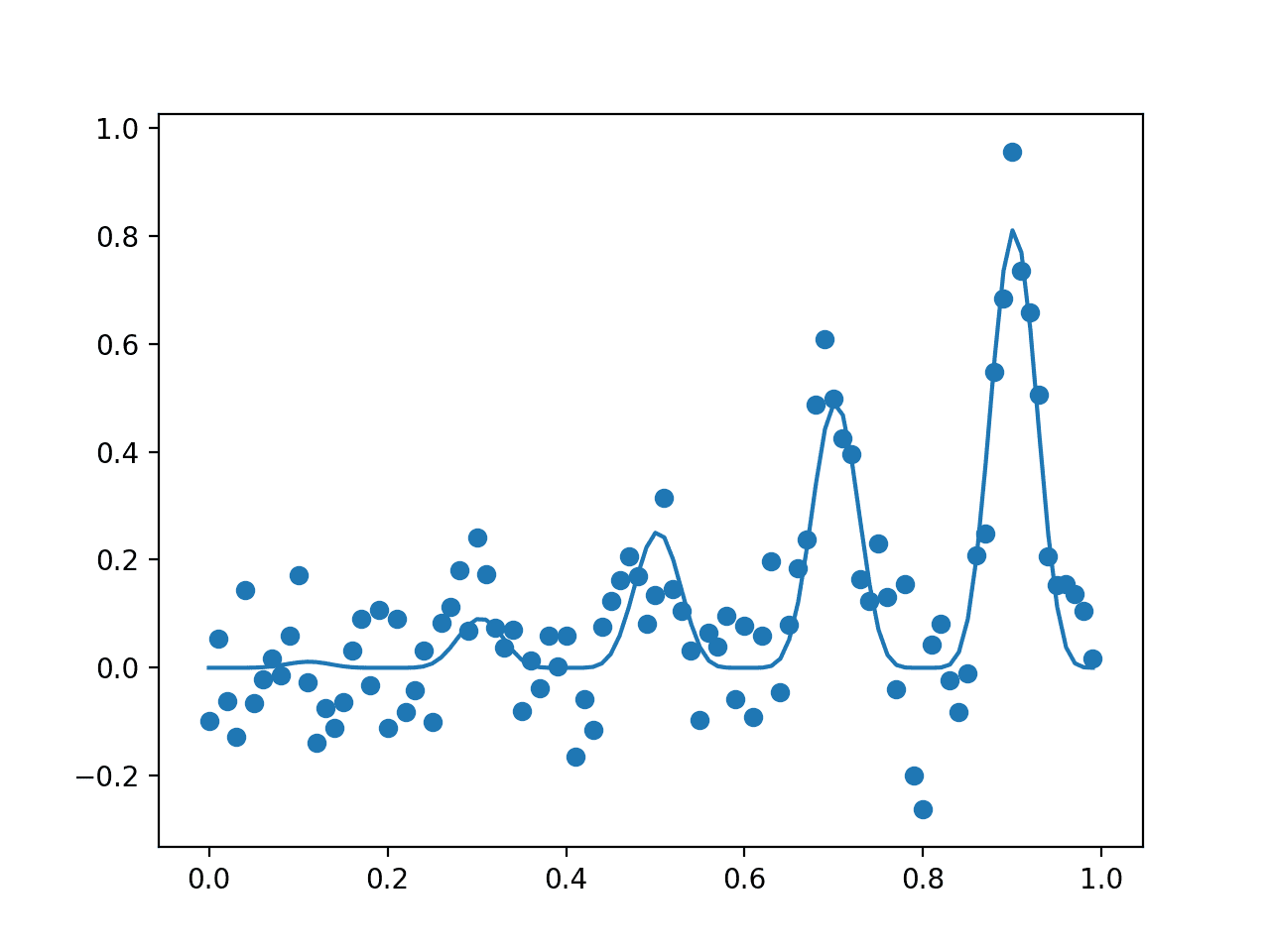
输入样本经过带噪声(点)和无噪声(线)目标函数评估的点图
现在我们有了一个测试问题,让我们回顾一下如何训练一个代理函数。
代理函数
代理函数是一种用于最佳近似输入示例到输出得分的映射的技术。
从概率上讲,它总结了目标函数(f)在给定可用数据(D)的条件概率,或 P(f|D)。
有多种技术可用于此,但最流行的是将问题视为回归预测建模问题,其中数据代表输入,得分代表模型的输出。这通常最好使用随机森林或高斯过程进行建模。
高斯过程(Gaussian Process),简称 GP,是一种在变量上构建联合概率分布的模型,假设为多元高斯分布。因此,它能够高效有效地总结大量函数,并随着更多观测值提供给模型而实现平滑过渡。
这种平滑结构以及基于数据的向新函数的平滑过渡是我们采样域的理想属性,而模型的多变量高斯基数意味着模型的估计将是具有标准差的分布的均值;这将有助于后续的采集函数。
因此,使用 GP 回归模型通常是首选。
我们可以使用 scikit-learn 的`GaussianProcessRegressor` 实现,通过输入样本 (X) 和目标函数的带噪声评估 (y) 来拟合 GP 回归模型。
首先,必须定义模型。定义 GP 模型的一个重要方面是核函数。它根据实际数据观测值之间的距离度量来控制函数在特定点的形状。可以使用许多不同的核函数,其中一些可能为特定数据集提供更好的性能。
默认情况下,使用可以很好工作的径向基函数(Radial Basis Function),简称 RBF。
|
1 2 3 |
... # 定义模型 model = GaussianProcessRegressor() |
定义后,可以通过直接调用 `fit()` 函数来拟合模型于训练数据集。
定义的模型可以随时使用附加到现有数据的数据再次拟合,只需再次调用 `fit()` 即可。
|
1 2 3 |
... # 拟合模型 model.fit(X, y) |
该模型可以估计提供给它的一个或多个样本的成本。
通过调用 `predict()` 函数来使用模型。给定样本的结果将是该点分布的均值。通过指定参数 `return_std=True`,我们还可以获得该函数中该点的分布标准差;例如
|
1 2 |
... yhat = model.predict(X, return_std=True) |
如果分布在感兴趣的某个点处较稀疏,此函数可能会产生警告。
因此,我们在进行预测时可以抑制所有警告。下面的 `surrogate()` 函数采用拟合的模型和一个或多个样本,并返回估计成本的均值和标准差,同时不打印任何警告。
|
1 2 3 4 5 6 7 |
# 目标函数的代理或近似 def surrogate(model, X): # 捕获预测时生成的任何警告 with catch_warnings(): # 忽略生成的警告 simplefilter("ignore") return model.predict(X, return_std=True) |
我们可以随时调用此函数来估计一个或多个样本的成本,例如当我们想在下一节中优化采集函数时。
目前,在对随机样本进行训练后,看看代理函数在整个域上的样子很有趣。
为此,我们首先在 100 个数据点及其带噪声的真实目标函数值上拟合 GP 模型。然后,我们可以绘制这些点的散点图。接下来,我们可以对输入域进行基于网格的采样,并使用代理函数估计每个点的成本,然后将结果绘制为线图。
我们期望代理函数能够粗略地近似真实的无噪声目标函数。
下面的 `plot()` 函数在给定真实带噪声目标函数的随机数据样本和拟合模型的情况下创建此图。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 绘制真实观测值与代理函数 def plot(X, y, model): # 输入和真实目标函数的散点图 pyplot.scatter(X, y) # 整个域上的代理函数的线图 Xsamples = asarray(arange(0, 1, 0.001)) Xsamples = Xsamples.reshape(len(Xsamples), 1) ysamples, _ = surrogate(model, Xsamples) pyplot.plot(Xsamples, ysamples) # 显示图表 pyplot.show() |
将这一切联系起来,下面列出了拟合高斯过程回归模型于带噪声样本并绘制样本与代理函数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# 高斯过程代理函数示例 from math import sin from math import pi from numpy import arange from numpy import asarray from numpy.random import normal from numpy.random import random from matplotlib import pyplot from warnings import catch_warnings from warnings import simplefilter from sklearn.gaussian_process import GaussianProcessRegressor # 目标函数 def objective(x, noise=0.1): noise = normal(loc=0, scale=noise) return (x**2 * sin(5 * pi * x)**6.0) + noise # 目标函数的代理或近似 def surrogate(model, X): # 捕获预测时生成的任何警告 with catch_warnings(): # 忽略生成的警告 simplefilter("ignore") return model.predict(X, return_std=True) # 绘制真实观测值与代理函数 def plot(X, y, model): # 输入和真实目标函数的散点图 pyplot.scatter(X, y) # 整个域上的代理函数的线图 Xsamples = asarray(arange(0, 1, 0.001)) Xsamples = Xsamples.reshape(len(Xsamples), 1) ysamples, _ = surrogate(model, Xsamples) pyplot.plot(Xsamples, ysamples) # 显示图表 pyplot.show() # 稀疏采样带噪声的域 X = random(100) y = asarray([objective(x) for x in X]) # 重塑为行和列 X = X.reshape(len(X), 1) y = y.reshape(len(y), 1) # 定义模型 model = GaussianProcessRegressor() # 拟合模型 model.fit(X, y) # 绘制代理函数 plot(X, y, model) |
运行示例,首先绘制随机样本,使用带噪声的目标函数对其进行评估,然后拟合 GP 模型。
然后绘制数据样本和整个域上的点网格,这些点通过代理函数进行评估,分别显示为点和线。
注意:鉴于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,正如我们所预期的,该图呈现了底层无噪声目标函数的粗略版本,重要的是在已知真实最大值所在的 0.9 附近有一个峰。
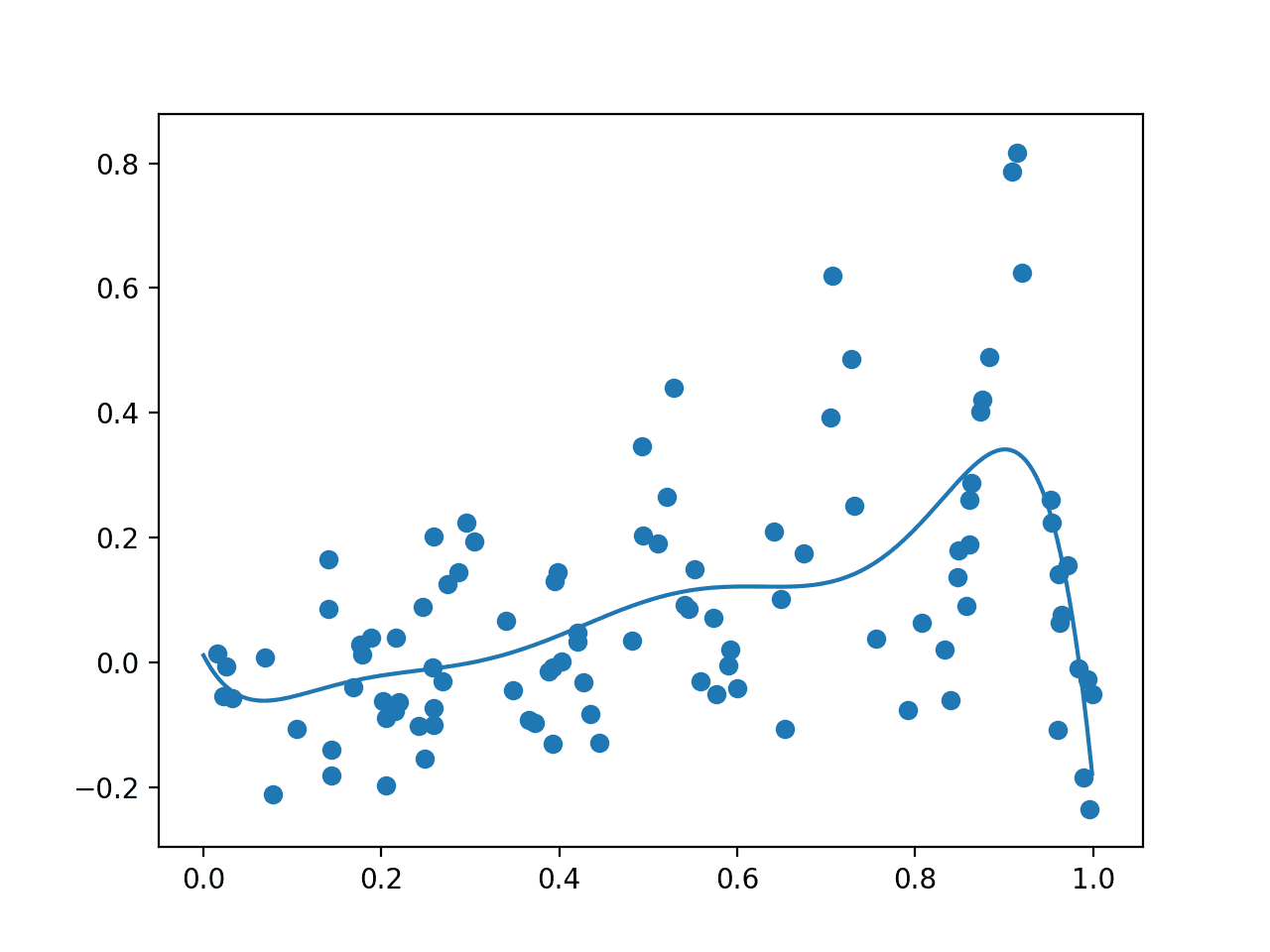
显示随机样本(点)和整个域上的代理函数(线)的图。
接下来,我们必须定义一个采样代理函数的策略。
采集函数
代理函数用于测试域中的一系列候选样本。
根据这些结果,可以选择一个或多个候选样本,并使用真实的(在正常实践中)计算成本高昂的成本函数进行评估。
这涉及两个部分:用于响应代理函数导航域的搜索策略,以及用于解释和评分代理函数响应的采集函数。
可以使用简单的搜索策略,例如随机采样或基于网格的采样,尽管使用局部搜索策略更常见,例如流行的BFGS 算法。在本例中,我们将使用随机搜索或随机采样域,以使示例保持简单。
这包括首先从域中抽取随机候选样本,使用采集函数评估它们,然后最大化采集函数或选择给出最佳得分的候选样本。下面的 `opt_acquisition()` 函数实现了这一点。
|
1 2 3 4 5 6 7 8 9 10 |
# 优化采集函数 def opt_acquisition(X, y, model): # 随机搜索,生成随机样本 Xsamples = random(100) Xsamples = Xsamples.reshape(len(Xsamples), 1) # 计算每个样本的采集函数 scores = acquisition(X, Xsamples, model) # 定位最大分数的索引 ix = argmax(scores) return Xsamples[ix, 0] |
采集函数负责对给定候选样本(输入)值得用真实目标函数评估进行评分或估算。
我们也可以直接使用代理得分。或者,鉴于我们已选择高斯过程模型作为代理函数,我们可以使用此模型中的概率信息在采集函数中计算给定样本值得评估的概率。
有许多不同类型的概率采集函数可供使用,每种函数在贪婪(exploitative)和探索(explorative)方面提供了不同的权衡。
三个常见示例包括
- 改进概率 (Probability of Improvement, PI)。
- 预期改进 (Expected Improvement, EI)。
- 置信下界 (Lower Confidence Bound, LCB)。
改进概率方法是最简单的,而预期改进方法是最常用的。
在本例中,我们将使用更简单的改进概率方法,该方法计算为归一化的预期改进的正常累积概率,计算如下:
- PI = cdf((mu – best_mu) / stdev)
其中 PI 是改进的概率,cdf() 是正态累积分布函数,mu 是给定样本 x 的代理函数的均值,stdev 是给定样本 x 的代理函数的标准差,best_mu 是迄今为止找到的最佳样本的代理函数的均值。
我们可以向标准差添加一个非常小的数字,以避免除以零错误。
下面的 `acquisition()` 函数在给定当前输入样本的训练数据集、一组新的候选样本以及拟合的 GP 模型的情况下实现这一点。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 改进概率采集函数 def acquisition(X, Xsamples, model): # 计算迄今为止找到的最佳代理得分 yhat, _ = surrogate(model, X) best = max(yhat) # 通过代理函数计算均值和标准差 mu, std = surrogate(model, Xsamples) mu = mu[:, 0] # 计算改进的概率 probs = norm.cdf((mu - best) / (std+1E-9)) return probs |
完整的贝叶斯优化算法
我们可以将所有这些整合到贝叶斯优化算法中。
主要算法涉及选择候选样本、使用目标函数评估它们,然后更新 GP 模型的循环。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... # 执行优化过程 for i in range(100): # 选择下一个采样点 x = opt_acquisition(X, y, model) # 采样点 actual = objective(x) # 总结发现以供我们自己报告 est, _ = surrogate(model, [[x]]) print('>x=%.3f, f()=%3f, actual=%.3f' % (x, est, actual)) # 将数据添加到数据集中 X = vstack((X, [[x]])) y = vstack((y, [[actual]])) # 更新模型 model.fit(X, y) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
# 从头开始为一维函数进行贝叶斯优化示例 from math import sin from math import pi from numpy import arange from numpy import vstack from numpy import argmax from numpy import asarray from numpy.random import normal from numpy.random import random from scipy.stats import norm from sklearn.gaussian_process import GaussianProcessRegressor from warnings import catch_warnings from warnings import simplefilter from matplotlib import pyplot # 目标函数 def objective(x, noise=0.1): noise = normal(loc=0, scale=noise) return (x**2 * sin(5 * pi * x)**6.0) + noise # 目标函数的代理或近似 def surrogate(model, X): # 捕获预测时生成的任何警告 with catch_warnings(): # 忽略生成的警告 simplefilter("ignore") return model.predict(X, return_std=True) # 改进概率采集函数 def acquisition(X, Xsamples, model): # 计算迄今为止找到的最佳代理得分 yhat, _ = surrogate(model, X) best = max(yhat) # 通过代理函数计算均值和标准差 mu, std = surrogate(model, Xsamples) mu = mu[:, 0] # 计算改进的概率 probs = norm.cdf((mu - best) / (std+1E-9)) return probs # 优化采集函数 def opt_acquisition(X, y, model): # 随机搜索,生成随机样本 Xsamples = random(100) Xsamples = Xsamples.reshape(len(Xsamples), 1) # 计算每个样本的采集函数 scores = acquisition(X, Xsamples, model) # 定位最大分数的索引 ix = argmax(scores) return Xsamples[ix, 0] # 绘制真实观测值与代理函数 def plot(X, y, model): # 输入和真实目标函数的散点图 pyplot.scatter(X, y) # 整个域上的代理函数的线图 Xsamples = asarray(arange(0, 1, 0.001)) Xsamples = Xsamples.reshape(len(Xsamples), 1) ysamples, _ = surrogate(model, Xsamples) pyplot.plot(Xsamples, ysamples) # 显示图表 pyplot.show() # 稀疏采样带噪声的域 X = random(100) y = asarray([objective(x) for x in X]) # 重塑为行和列 X = X.reshape(len(X), 1) y = y.reshape(len(y), 1) # 定义模型 model = GaussianProcessRegressor() # 拟合模型 model.fit(X, y) # 事先绘制 plot(X, y, model) # 执行优化过程 for i in range(100): # 选择下一个采样点 x = opt_acquisition(X, y, model) # 采样点 actual = objective(x) # 总结发现 est, _ = surrogate(model, [[x]]) print('>x=%.3f, f()=%3f, actual=%.3f' % (x, est, actual)) # 将数据添加到数据集中 X = vstack((X, [[x]])) y = vstack((y, [[actual]])) # 更新模型 model.fit(X, y) # 绘制所有样本和最终的代理函数 plot(X, y, model) # 最佳结果 ix = argmax(y) print('Best Result: x=%.3f, y=%.3f' % (X[ix], y[ix])) |
运行该示例,首先创建对搜索空间的初始随机采样和结果的评估。然后,在这些数据上拟合 GP 模型。
注意:鉴于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
创建一张图,显示原始观测值(点)和整个域上的代理函数。在这种情况下,初始样本在整个域上具有良好的分布,并且代理函数偏向于我们知道极值所在的区域。
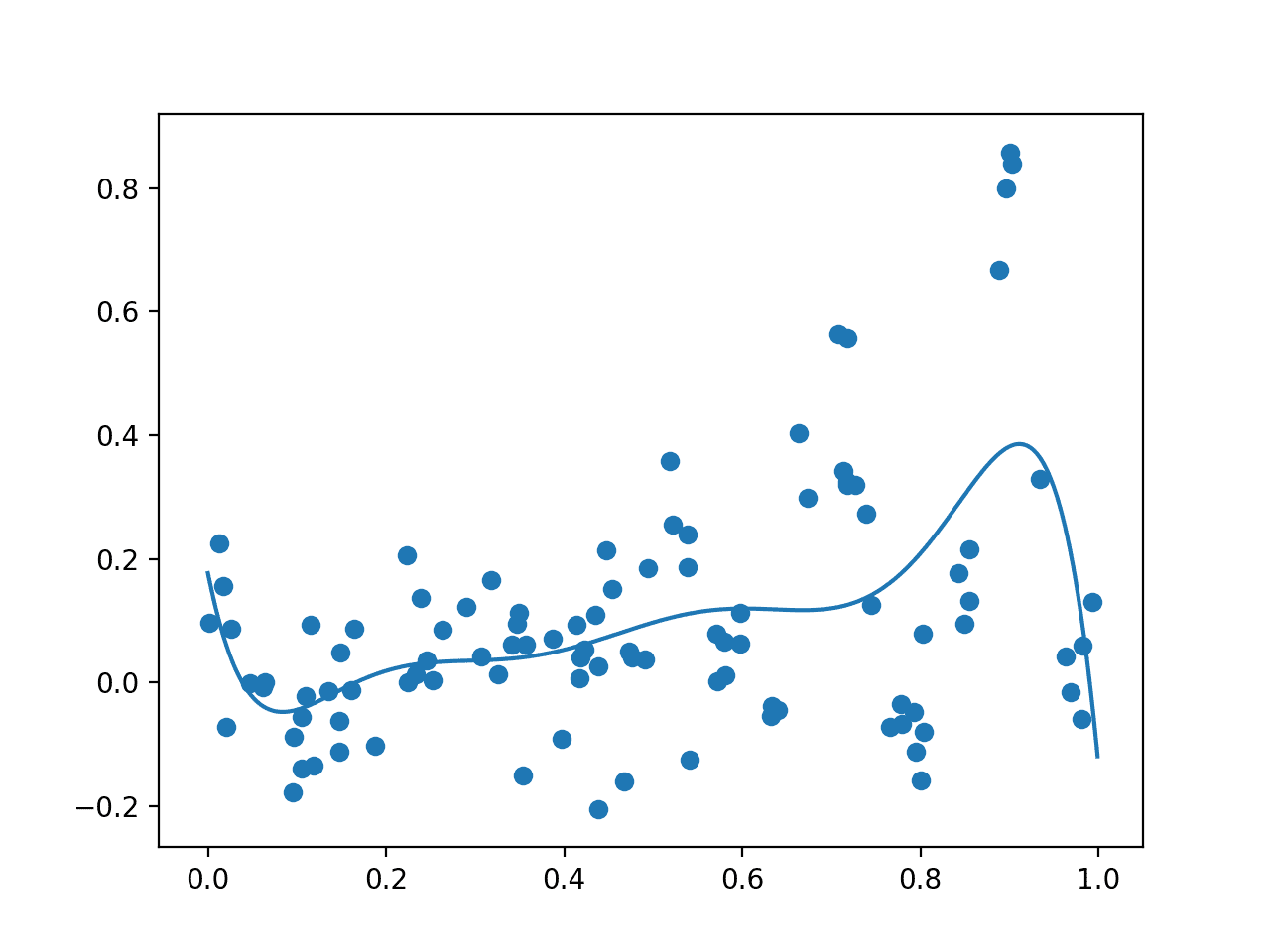
初始样本(点)和整个域上的代理函数(线)的图。
然后,算法迭代 100 个周期,选择样本,评估它们,并将它们添加到数据集中以更新代理函数,如此循环往复。
每个周期都会报告选定的输入值、代理函数的估计得分以及实际得分。理想情况下,随着算法收敛于搜索空间的一个区域,这些得分会越来越接近。
|
1 2 3 4 5 6 |
... >x=0.922, f()=0.661501, actual=0.682 >x=0.895, f()=0.661668, actual=0.905 >x=0.928, f()=0.648008, actual=0.403 >x=0.908, f()=0.674864, actual=0.750 >x=0.436, f()=0.071377, actual=-0.115 |
接下来,创建最后一个图,其形式与之前的图相同。
这次,绘制了优化任务中评估的所有 200 个样本。我们期望在已知极值周围有大量的采样,而这正是我们看到的,0.9 附近有许多点。我们还看到代理函数对底层目标域具有更强的表示。
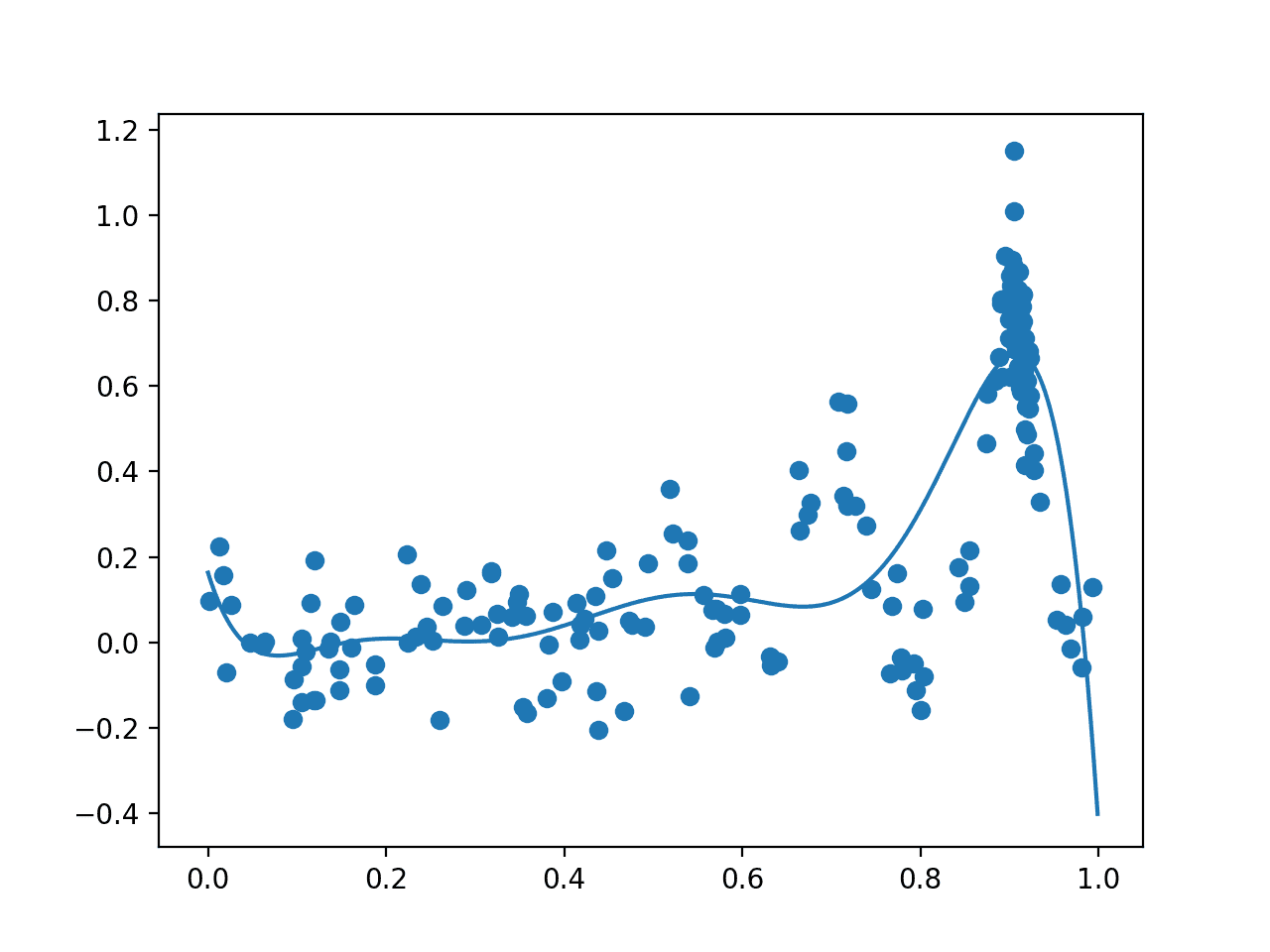
贝叶斯优化后,所有样本(点)和整个域上的代理函数(线)的图。
最后,报告最佳输入及其目标函数得分。
如果我们没有采样噪声,我们知道极值是输入 0.9,输出 0.810。
考虑到采样噪声,在本例中优化算法非常接近,表明输入值为 0.905。
|
1 |
Best Result: x=0.905, y=1.150 |
使用贝叶斯优化进行超参数调优
实现贝叶斯优化以了解其工作原理是一个有用的练习。
在实践中,当在项目中使用贝叶斯优化时,最好使用开源库提供的标准实现。这是为了避免错误,并利用更广泛的配置选项和速度改进。
两个流行的贝叶斯优化库包括Scikit-Optimize和HyperOpt。在机器学习中,这些库通常用于调整算法的超参数。
超参数调优非常适合贝叶斯优化,因为评估函数在计算上是昂贵的(例如,为每组超参数训练模型)并且有噪声(例如,训练数据中的噪声和随机学习算法)。
在本节中,我们将简要介绍如何使用 Scikit-Optimize 库来优化 k-近邻分类器的超参数,以解决一个简单的测试分类问题。这将提供一个有用的模板,您可以在自己的项目中使用。
Scikit-Optimize 项目旨在为使用 SciPy 和 NumPy 的应用程序,或使用 scikit-learn 机器学习算法的应用程序提供贝叶斯优化访问。
首先,必须安装该库,这可以使用 pip 轻松完成;例如
|
1 |
sudo pip install scikit-optimize |
本示例还假设您已安装scikit-learn。
安装后,scikit-optimize 可以通过两种方式用于优化 scikit-learn 算法的超参数。第一种是直接在搜索空间上执行优化,第二种是使用 BayesSearchCV 类,它是 scikit-learn 本地随机搜索和网格搜索类的同级类。
在本例中,我们将使用更简单的方法直接优化超参数。
第一步是准备数据并定义模型。我们将使用`make_blobs()` 函数通过一个简单的测试分类问题,该问题包含 500 个示例,每个示例有两个特征和三个类别标签。然后我们将使用`KNeighborsClassifier` 算法。
|
1 2 3 4 5 |
... # 生成二维分类数据集 X, y = make_blobs(n_samples=500, centers=3, n_features=2) # 定义模型 model = KNeighborsClassifier() |
接下来,我们必须定义搜索空间。
在这种情况下,我们将调整邻居的数量(n_neighbors)和邻域函数的形状(p)。这需要为给定的数据类型定义范围。在本例中,它们是整数,通过最小值、最大值以及 scikit-learn 模型参数的名称来定义。对于您的算法,您可以轻松地优化 Real() 和 Categorical() 数据类型。
|
1 2 3 |
... # 定义要搜索的超参数空间 search_space = [Integer(1, 5, name='n_neighbors'), Integer(1, 2, name='p')] |
接下来,我们需要定义一个函数来评估给定的一组超参数。我们希望最小化此函数,因此返回的较小值必须表示模型性能较好。
我们可以使用 scikit-optimize 项目的 `use_named_args()` 装饰器应用于函数定义,该装饰器允许函数直接使用搜索空间中的一组特定参数进行调用。
因此,我们的自定义函数将接受超参数值作为参数,这些参数可以直接提供给模型以进行配置。我们可以使用 `**params` 参数在 Python 中通用地定义这些参数,然后通过 `set_params(**)` 函数将它们传递给模型。
现在模型已配置好,我们可以对其进行评估。在本例中,我们将使用 5 折交叉验证在我们的数据集上进行评估,并计算每个折的准确率。然后,我们可以将模型性能报告为这些折的平均准确率减去一。这意味着准确率为 1.0 的完美模型将返回 0.0(1.0 - 平均准确率)。
此函数在加载数据集并定义模型之后定义,以便数据集和模型都在作用域内并可直接使用。
|
1 2 3 4 5 6 7 8 9 10 |
# 定义用于评估给定配置的函数 @use_named_args(search_space) def evaluate_model(**params): # 某事 model.set_params(**params) # 计算 5 折交叉验证 result = cross_val_score(model, X, y, cv=5, n_jobs=-1, scoring='accuracy') # 计算得分的平均值 estimate = mean(result) return 1.0 - estimate |
接下来,我们可以执行优化。
这通过调用 `gp_minimize()` 函数并传入目标函数的名称和定义的搜索空间来实现。
默认情况下,此函数将使用“`gp_hedge`”采集函数,该函数会尝试找出最佳策略,但这可以通过 `acq_func` 参数进行配置。默认情况下,优化还将运行 100 次迭代,但这可以通过 `n_calls` 参数进行控制。
|
1 2 3 |
... # 执行优化 result = gp_minimize(evaluate_model, search_space) |
运行后,我们可以通过“fun”属性访问最佳得分,并通过“x”数组属性访问最佳超参数集。
|
1 2 3 4 |
... # 总结发现 print('Best Accuracy: %.3f' % (1.0 - result.fun)) print('Best Parameters: n_neighbors=%d, p=%d' % (result.x[0], result.x[1])) |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 使用 scikit-optimize 的贝叶斯优化示例 from numpy import mean from sklearn.datasets import make_blobs from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsClassifier from skopt.space import Integer from skopt.utils import use_named_args from skopt import gp_minimize # 生成二维分类数据集 X, y = make_blobs(n_samples=500, centers=3, n_features=2) # 定义模型 model = KNeighborsClassifier() # 定义要搜索的超参数空间 search_space = [Integer(1, 5, name='n_neighbors'), Integer(1, 2, name='p')] # 定义用于评估给定配置的函数 @use_named_args(search_space) def evaluate_model(**params): # 某事 model.set_params(**params) # 计算 5 折交叉验证 result = cross_val_score(model, X, y, cv=5, n_jobs=-1, scoring='accuracy') # 计算得分的平均值 estimate = mean(result) return 1.0 - estimate # 执行优化 result = gp_minimize(evaluate_model, search_space) # 总结发现 print('Best Accuracy: %.3f' % (1.0 - result.fun)) print('Best Parameters: n_neighbors=%d, p=%d' % (result.x[0], result.x[1])) |
运行示例,执行使用贝叶斯优化进行的超参数调优。
代码可能会报告许多警告消息,例如
|
1 |
UserWarning: The objective has been evaluated at this point before. |
这是可以预期的,并且是由于相同的超参数配置被评估了不止一次。
注意:鉴于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,该模型通过平均 5 折交叉验证,在 3 个邻居和 p 值为 2 的情况下,达到了大约 97% 的准确率。
|
1 2 |
Best Accuracy: 0.976 Best Parameters: n_neighbors=3, p=2 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 关于昂贵成本函数贝叶斯优化的教程,应用于主动用户建模和分层强化学习, 2010.
- 机器学习算法的实践贝叶斯优化, 2012.
- 贝叶斯优化教程, 2018.
API
文章
- 全局优化,维基百科.
- 贝叶斯优化,维基百科.
- 贝叶斯优化, 2018.
- 贝叶斯优化是如何工作的?,Quora.
总结
在本教程中,您了解了用于复杂优化问题的定向搜索的贝叶斯优化。
具体来说,你学到了:
- 全局优化是一个具有挑战性的问题,涉及黑盒优化,并且通常是非凸、非线性、有噪声且计算成本高昂的目标函数。
- 贝叶斯优化为全局优化提供了一种基于概率的原则性方法。
- 如何从头开始实现贝叶斯优化以及如何使用开源实现。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







> # 域 [0,1] 的网格采样
> X = arange(0, 1, 0.01)
严格来说,这是域 [0, 1) 的网格采样,arange 的工作方式类似于 range,它不包含右边界。这虽然细微,但曾让我头疼过几次……
我认为 linspace 更适合构建网格。
非常棒的提示,谢谢!
嗨
感谢您又一篇精彩的博文。
我只是好奇想知道一些您可能不想回答的问题,当然,这也没关系。
您在开始写作之前就已经知道要写的主题的所有细节,还是您首先通过阅读、研究和尝试事物来让自己对主题本身充满信心?
无论如何,两种情况我都感谢您 🙂
很好的问题。
大多数情况下,我熟悉这些主题,然后阅读/编码来撰写帖子。我现在已经做了很久了 :)
有时我了解很少,不得不花几天时间阅读论文/代码来跟上进度。
我有一些帖子概述了如何在新主题/算法上加倍努力,大概就在这里,“如何学习/理解机器学习算法”下。
https://machinelearning.org.cn/start-here/#algorithms
Phyton 是一种高级编程语言,非常适合处理复杂的情况。
贝叶斯优化是一项非平凡的任务,即使应用于简单情况也是如此。
使用与 Phyton 不同的编程语言的想法是一个坏主意。
感谢分享。
嗨 Jason,感谢您的文章。我只是想指出,截至 2019 年 11 月(参见 github 上的项目 README),scikit-optimize 已不再积极维护。
谢谢。
该项目现在看起来很活跃,并且今年已经发布了许多版本 https://scikit-optimize.github.io/stable/
同意,它已经启动起来了!
例如
https://machinelearning.org.cn/scikit-optimize-for-hyperparameter-tuning-in-machine-learning/
嗨 Jason
我是新手,但您的程序似乎完全无法预测该函数。拥有如此多的数据,我本以为足以预测倒数第二个峰,但它完全错过了。我想也许噪声太高导致预测不准确,所以我进去将噪声降低到 0.01,但得到了相同的功能。我只是不明白这个例子的价值。
嗨 Peter,我认为您误解了教程的重点——或者我未能突出重点。
在这里,我们试图找到最大的峰——这是一个优化问题。
我们不是在试图近似底层函数,即所谓的函数近似。
一个问题,您提到一个常见的采集函数是置信下界。但这对我来说意义不大,为什么置信下界是一个好的指标?它会阻碍在高不确定性区域的探索。也许您是指置信上限?因为那将是有意义的,因为它会鼓励在高均值和高不确定性的地方进行探索。
这些是方法的名称,也许可以参考“进一步阅读”部分来了解它们的计算方式。
我非常熟悉 LCB 和 UCB,它们分别计算为均值 - 标准差和均值 + 标准差,置信下界将给出给定置信水平下的函数下界,我猜混淆之处在于您最大化值(因此您应该使用 UCB),但许多论文谈论函数最小化,在这种情况下 LCB 是合适的采集函数。
Jason,这是关于这个主题的最好的帖子。您是否为您的学习材料提供新冠折扣?
谢谢!
如果您想要折扣,请直接联系我
https://machinelearning.org.cn/contact/
嗨 Jason
感谢精彩的文章。您能否为预期改进 (EI) 添加解释?Python 中一些常见的 HP 调优库(hyperopt、optuna 等)使用 EI 作为采集函数……我尝试阅读了几篇博客,但它们数学含量很高,而且没有提供 EI 的直观解释。
到目前为止我所理解的是,它正在计算一个期望值(X x P(x)),并且 EI 应该被最大化……
您能否用更简单的术语解释一下?
谢谢
不客气。
好建议,谢谢!
嗨,Jason,
我对您计算模型均值向量的部分不确定。
我认为您应该使用当前训练数据点,而不是使用随机采样数据点(surrogate(model, Xsamples))。
为什么?
你好,
我正在为我的冰厚模型调整模型参数。该模型有 2 个输入变量和 3 个模型参数(需要我调整)。我的测量冰厚数据约为 3000 个点,并且希望自动化整个训练和测试过程。我的目标是估算冰厚,使其与测量的偏差最小,并找到最佳的三组模型参数。所以我的问题是,我应该尝试哪种代码形式?我需要代理函数和采集函数吗?
也许如果有少数参数需要测试,您可以使用网格搜索来枚举所有参数,而不是使用贝叶斯搜索?
嘿 Jason,首先感谢您的精彩帖子。
我只是有一个问题。我正在处理波士顿房价数据集,并尝试使用贝叶斯优化来获得 ridge、net 和 XGBoost 的更好参数。我想知道是否可以对它们实施相同的方法。我还遇到另一个名为 BayesianOptimization 的软件包。您认为哪种方法更适合处理我的问题?
是的,您可以尝试使用贝叶斯优化来调整您的模型。
嗨 Jason,您能告诉我目标函数是否是特定于问题的(例如,指定的函数取决于我们试图解决的问题)?如果不是,这是否意味着我们可以指定任何我们想要的函数,因为它是一个黑盒函数?
不是。正确。
非常感谢您的精彩文章。
在您的示例中,X, y = make_blobs(n_samples=500, centers=3, n_features=2),如果 n_features >>2,BO 还能正常工作吗?
我想优化维度远高于 2 的潜在空间。您的建议非常宝贵。
是的。试试看,或许可以与其他方法进行比较。
感谢您的回复。我不想搜索超参数,我想搜索 X 的特征。也就是说,哪个 X (feature_1, feature_2, …., feature_n) 可以使 y 最大化。优化后,我可以得到 feature_1 到 feature_n 的值,而不是模型的超参数。
例如,我使用 VAE 来训练大量的分子。然后我可以得到一个潜在空间 Z。我使用这个潜在空间向量来训练一个模型来预测分子的性质,例如分子的毒性。现在我想搜索这个潜在空间 Z 来找到一个毒性最小的点 z。这里 z 是一个高维向量。
听起来很棒!
但我不知道如何实现。有什么建议吗?谢谢。
也许你可以从上面列出的例子开始,尝试为你的需求进行调整?
具体是哪部分让你卡住了?
嗨,Jason,
你给出了一个非常清晰的解释。
能否请您解释一下,在优化输入变量以最大化目标函数时,遗传算法是否会更好?
另外,请提供我的问题陈述中可用于机器学习技术的资源。
谢谢你。
谢谢。
这取决于被优化的函数,哪种方法效果最好。尝试直接比较。
问题陈述是什么?
好的。
基本上,我没有一个明确的解析函数 y=f(x)。我使用一个模拟器,它能为给定的输入/输入向量 x 提供输出 y。因此,模拟器充当函数。
输入向量包含 10 个变量(x1、x2 等)。
现在,我想找到最大化输出的输入的最佳值。
(瓶颈:从模拟器获取大量数据非常昂贵。所以我的想法是尽可能少地模拟点来达到最优解。)
所以,我正在寻找可以解决这个问题的某种方法。
您能否提供关于从哪里开始最好的信息?
另外,请阐明我可以探索的各种优化技术和机器学习技术,以便尝试和比较结果!
是的,您可以使用上述方法,并将解析函数替换为您模拟器的结果。
我建议使用该库而不是自定义版本,以提高速度和可靠性。
好的。谢谢 Jason。
嗨,Jason,
谢谢发帖,非常有信息量。或许可以解释一下如何将这种贝叶斯优化方法应用于分类问题?
感谢您的建议。
谢谢这篇好文章。
我猜提供的代码中的所有行,如
Xsamples = asarray(arange(0, 1, 0.001))
可以替换为
Xsamples = arange(0, 1, 0.001)
谢谢。
你好 Jason,你的帖子真的很有帮助。我有一个问题……如果获取函数中的概率都为零,那么 ix = argmax(scores) 在 opt_aquistion 下是否总是取 ix=0?这是正确的吗?
谢谢。
是的。
嗨,Jason,
谢谢。代理模型的输出何时会为零?也就是说,
在 mu, std = surrogate(model, Xsamples) 中,何时 mu = 0?我已经定义了作为代理模型一部分的目标函数,对模型进行了拟合,现在正在为新样本点进行预测。但我无法理解为什么我会得到零预测?高斯过程回归器何时会给出零预测?
整个域的零输出听起来像是一个问题。也许你的实现中存在 bug?
嗨 PK,
你解决问题了吗?我的代理模型遇到了同样的问题,只是我还有一个额外的问题,改进的概率也总是零。我实现了 Jason 的原始代码并打印了概率,结果发现它们都像我的模型一样是零。
嗨,Jason,
感谢您出色的教程。它确实很有帮助。
我有一个问题,如果我没有目标函数,但有一些已知的离散点,比如输入 [1,2] 和输出 [3] 以及许多其他点。如果这是我的原始样本,我该如何获得目标函数?你能给我一些建议吗?
目标函数将根据您的点来定义——我预期是这样。
很棒的教程。终于有人成功让我理解了 BO 的工作原理!🙂
我有一个小的建议。
在这个例子中,我们在 [0,1] 中采样 X 100 次,并添加标准差为 0.1 的噪声。考虑到相对较小的噪声,函数的最大值通常出现在 x=0.9。因此,即使在开始 BO 迭代之前,我们已经在先验中得到了最大值。这没有问题,但它使得算法不那么有趣。
从 X 的一个子集(最好不包含最大值点)开始作为初始先验怎么样?
例如,我做了
X_ans = np.arange(0, 1, 0.001)
y_ans = objective(X_ans)
X = X_ans[::71] # <— 子采样以避免最大值
y = y_ans[::71]
X = X.reshape(-1,1)
y = y.reshape(-1,1)
……以此类推……
现在,我的 BO 算法比我拥有的初始数据能够更接近“真实”的最大值,我觉得更有趣。
此外,为新点着色让我感觉更好!
再次感谢您出色的教程。
谢谢。
好建议。
你好 Jason!感谢您的发帖,它帮助我更好地理解了算法!
我有一个与 Xuan Wang 提出的问题类似的问题。我没有一个明确的解析目标函数,我实际上使用了一个高斯过程回归器来模拟我的数据,因此假设这是我的真实目标函数。所以,我想找到我的高斯过程模型的值。
在这种情况下,我是否应该在贝叶斯优化中使用我的目标函数和模型作为同一个高斯过程回归器(具有相同的参数)?我通过使用这个获得了良好的结果,但我并不完全确定这是否正确。
不客气。
不确定我是否理解,您必须有一个需要近似的评估。
我有 4D 数据(x1、x2、x3 和 y),这些是现场传感器的读数,我使用高斯过程回归器来推导一个黑盒模型,使得 y = GPR(x1,x2,x3)。
现在,我的最终目标是找到 GRP(x1,x2,x3) 的最大值,例如,假设评估 y 的唯一方法来自高斯过程。贝叶斯优化在此情况下仍然适用吗?该算法是否会有两个高斯过程,其中一个用于最大化?
感谢您的快速回复!
也许可以尝试一下。
嗨,Jason,
再次感谢一篇非常具有启发性的文章。
我有一个关于目标函数评估的问题。您在每个周期中从带噪声的版本中获得“实际”最优值。为什么?
我最初以为您会最小化解析模型。似乎不是这样。您是在生成“合成数据”并尝试优化某个“未知决策函数”吗?
如果是这样,在实际场景中我该如何执行?我的意思是,假设我不知道目标函数的解析形式(只有数据点)。鉴于我只有数据,我应该如何评估每个周期的“实际”候选者?
此问题设置假定函数评估存在噪声。如果您的问题的实际情况并非如此,则贝叶斯优化可能不适用。
你好,
感谢您的文章。
我有一个问题:如果我的优化参数不是整数而是整数元组,我该如何定义我的搜索空间?即 ARIMA 的阶数 = (p,d,q)
我想在这个三维空间上进行优化,但我无法正确定义我的搜索空间。
这将是所有组合,例如嵌套的 for 循环,例如
https://machinelearning.org.cn/grid-search-arima-hyperparameters-with-python/
我刚刚阅读了您发送的文章。
然而,我觉得嵌套的 for 循环与实现搜索算法相比,资源消耗太大了。
如果我想调整 SARIMAX (p,d,q,P,D,Q,m) 模型并进行 7 次嵌套 for 循环,我的计算时间将增加 o(x^7)。
有没有办法对 ARIMA 调优应用随机搜索方法?
不完全是,请看这个例子
https://machinelearning.org.cn/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
非常感谢您的快速回复!我曾热切阅读了您的许多文章,它们确实是金矿。
不客气!
你好 Jason,
感谢您出色的文章。
我们有一个用例,其中黑盒优化为问题提供了解决方案(查找数学性质未知的基于物理的模型参数)。
目前我对贝叶斯优化的内部工作原理不太了解。我会学习并尝试实现。这篇帖子将对开始实现非常有帮助。
我有一个问题。贝叶斯优化是否需要像监督学习那样的大量数据?根据我天真的理解,贝叶斯优化不需要数据。算法本身进行采样和搜索最优参数。它只需要对输出(参数)进行评估。
如果我的理解是正确的,请告知。
谢谢你
感谢您的精彩帖子!
不客气。
它可能需要也可能不需要许多问题样本,这确实取决于问题。
谢谢您的快速回复。这里的样本需求是指算法本身进行采样吗?还是我们必须提供先验分布(也许我的问题没有意义,因为我不知道算法的工作原理)?
谢谢你
抱歉,“样本”是指输入与目标函数的评估。
感谢您的回复。在此实现中,目标函数是连续的。
它是否必须是连续的?在我正在解决的问题(寻找最佳低通滤波器系数)中,目标函数本质上是离散的。无法确定中间值的目标函数值。在这种情况下,我们如何制定目标函数?
是的,我相信对于这个实现是这样。严格来说,我认为不是。
嘿,Jason
很棒的博客,我刚刚下载了全套书籍。
我来自不确定性决策领域——很多年前——并且以前使用过 Hooke-Jeeves 方法,但它在不确定性/可变性方面表现非常糟糕。所以我非常渴望尝试贝叶斯优化。
对我来说,单变量示例非常有限。由于我对 Python 比较陌生,我想知道您是否可以将其示例扩展到 Rosenbrock Banana 函数,该函数使用 2 个变量。https://en.wikipedia.org/wiki/Rosenbrock_function
感谢您的建议。确实,扩展示例应该不难。如果您能花一些时间阅读 Python 入门书籍,那应该会对您更有帮助。
感谢分享。我想指出,GP 没有被调整,因为它的超参数不是在迭代中估计的。这是因为您为 GP 使用了以下核
ConstantKernel(1.0, constant_value_bounds=”fixed” * RBF(1.0, length_scale_bounds=”fixed”) 这是默认核。
另一个效果更好的选择是:kernel = C(1.0, (1e-3, 1e3)) * RBF(10, (1e-2, 1e2)),然后编写 model = GaussianProcessRegressor(kernel=kernel)。
感谢指出!
你好 Dambling。您能否详细说明一下?
你好,
非常感谢您的详细解释。如果您能指导我关于贝叶斯优化和强化学习的比较和对比资源,那将非常有帮助。尤其是当我想要理解一系列导致最优值的输入时,哪种方法更好:RL 还是 SMBO?另外,我很好奇贝叶斯优化除了超参数调优之外的具体用例。
非常感谢!
嗨 Yashaswini…您可能想回顾以下内容
https://towardsdatascience.com/reinforcement-learning-vs-bayesian-optimization-when-to-use-what-be32fd6e83da
此致,
哈哈,
> model = GaussianProcessRegressor()
> model.fit()
我非常感谢您发布这篇文章,但这并不是“从头开始的贝叶斯优化”。也许如果 scikit-learn 是从头开始实现的?但我有点怀疑。
感谢您的反馈,Matthew!
你好,James Carmichael!
精彩的文章!
在“获取函数”部分,我无法理解 cdf() 函数的作用。
> # 原始代码
> probs = cdf((mu – best) / (std+1E-9))
>
> # opt_acquisition() 查找 probs 值最大的点。
> # 如果 x 最大,cdf 值也最大。
> # cdf([0.1, 0.1, 0.4, 0.5, 0.2, 0.5, 0.7, 0.1, 0.1])
> # array([0.53982784, 0.53982784, 0.65542174, 0.69146246, 0.57925971,
> # 0.69146246, 0.75803635, 0.53982784, 0.53982784])
> # 我想知道我是否可以这样写并获得相同的结果
> probs = (mu – best) / (std+1E-9)
你好 Song……以下内容可能有助于进一步阐明
https://machinelearning.org.cn/empirical-distribution-function-in-python/#:~:text=The%20CDF%20returns%20the%20expected,Kernel%20Density%20Estimation%20(KDE).
你好,James Carmichael!
CDF 的作用我已看过您的这篇文章,它对我的帮助很大。我想我没有清楚地表达我的观点。我的意思是,我无法理解这篇文章“获取”函数中的 cdf() 函数。
“获取”函数中的原始代码是
> probs = norm.cdf( (mu – best) / (std+1E-9) )
如果我只删除 cdf() 函数,代码将给出相同的结果。
> probs = (mu – best) / (std+1E-9)
因为“opt_acquisition”函数获取“acquisition”函数的返回向量并计算最大值索引。然而,cdf 函数返回值的累积。如果值最大,cdf() 的返回值也最大,所以删除 cdf 可能会得到相同的结果。
> # 这是一个 cdf 测试
> from scipy.stats import norm
> x = [0.1, 0.1, 0.4, 0.5,
0.2, 0.5, 0.7, 0.1,
0.1]
> norm.cdf( x )
# array([0.53982784, 0.53982784, 0.65542174, 0.69146246,
# 0.57925971, 0.69146246, 0.75803635, 0.53982784,
# 0.53982784 ]
谢谢!
亲爱的Jason Brownlee,
感谢您出色的教程,我真的很喜欢动手的方法,可以 100% 清楚地理解这些想法。不过我有一个关于您示例的问题,更具体地说是关于获取函数,我已将其从您的帖子中复制到下面
# 改进概率采集函数
def acquisition(X, Xsamples, model)
# 计算到目前为止已找到的最佳代理分数
yhat, _ = surrogate(model, X)
best = max(yhat)
# 通过代理函数计算均值和标准差
mu, std = surrogate(model, Xsamples)
mu = mu[:, 0]
# 计算改进的概率
probs = norm.cdf((mu – best) / (std+1E-9))
return probs
我有点难以理解这里发生了什么,也就是选择逻辑(选择下一个点的标准),但我会尝试逐行分解
1. 在“yhat, _ = surrogate(model, X)”中,我们计算已观察数据 (X,y) 的模型拟合均值(即在观测 x 位置的预测)。
2. “best = max(yhat)”对应于最大均值预测。
3. 在“mu, std = surrogate(model, Xsamples)”中,我们计算从我们希望选择最优新样本位置的新 x 位置(Xsamples)的预测均值和标准差。
4. 在“probs = norm.cdf((mu – best) / (std+1E-9))”中,我们计算 CDF 概率值,当“mu”到“best”的标准距离(即 z 分数)尽可能为正时,该值最大。设“mu_best”是“mu”中具有此属性的值。
现在我感到困惑的是可能是步骤 2 和 4。我不理解这个选择逻辑,为什么我们要采样下一个位置 x,其均值预测是“mu_best”?
假设预测的标准差相等。在这种情况下,PI 规则指导我们选择从“mu”尽可能大的 x 位置进行采样(例如 mu >> best)。所以我们总是选择具有尽可能大预测 y 值的样本点。
这为什么是个好主意?这正是我不理解的。预先感谢您。
附言:为了补充我之前的问题,我不明白“改进概率”规则在何种意义上改进我们的选择,通过总是选择例如具有最大预测均值的 x 位置,我们可以如何改进我们估计的代理模型?
你好 Jjep……以下内容可能有助于进一步阐明
https://towardsdatascience.com/a-conceptual-explanation-of-bayesian-model-based-hyperparameter-optimization-for-machine-learning-b8172278050f
亲爱的 James Carmichael,
感谢您的回复和链接。我从其他来源找到了一个很好的解释
https://www.borealisai.com/en/blog/tutorial-8-bayesian-optimization/
“改进概率考虑了我们迄今为止观察到的最佳函数值 f(x)(水平虚线),并衡量了新点处的样本超过该值的概率。”
因此,在我看来,“最佳”和“改进”这两个词可能有点误导。“最佳”实际上是当前拟合模型的最大值,但我看不出它在某种意义上是如何“最佳”的。“改进”也应该更清楚。我不明白“在最有可能超过最佳 f(x) 的新点处进行采样”的规则如何被视为改进。
附言。
补充之前的内容:我认为如果函数 f 是一种得分/性能函数,那么“最佳”和“改进”这两个术语才有意义,您怎么看?
有一个说明,y = np.vstack((y, [[actual]])) 这一行是不正确的。我们不知道目标函数导出的实际值。它应该是 y = np.vstack((y, [[est]])。
上一个评论有误。附加估计意味着您从未更新代理函数。附加实际值意味着您拥有真实情况。应该附加的是实际值 + 噪声。
感谢您的反馈 Tim!
感谢您精彩的解释!
我感到困惑,当您说获取函数是似然函数时。
您能否将贝叶斯定理中的每个组件(先验、似然、后验)与此处介绍的概念(代理模型、获取函数)进行映射?
我们不就是为了最大化后验概率吗?那么获取函数就对应后验?但我不知道这如何确定,如果确定了,先验是什么?
p(H|E) = p(E|H)*p(H) = p(E|H)*surrogate(H) = acquisition???
你好 Moon……下面的资源应该能让你更清楚
https://arxiv.org/abs/1807.02811
你好,
感谢精彩教程。您知道是否有其他库可以调用我自己的代理模型(比如说,我想使用 DNN)?
你好 Hanser……您可能会发现以下资源很有趣
https://towardsdatascience.com/bayesian-hyperparameter-optimization-for-a-deep-neural-network-590be92bb0c0
https://ieeexplore.ieee.org/document/9612061
嗨 James,
感谢这些资源。这些帖子中提供的选项尝试使用高斯过程作为代理模型来调整 DNN 的超参数。然而,我想做的是使用 DNN 作为代理模型(或任何其他我可以自己构建的代理模型)。
嗨 James,
再次感谢您出色的教程。我实现了帖子的原始脚本(“如何执行 Bayes 优化”部分),我发现改进的概率(代码中的 probs)总是零。起初,我假设这是因为最优值已经存在于初始数据集中,因此所有其他样本都不是更好的点。但是,我大大减少了初始样本的数量(只有 10 或 20 而不是 100),以避免捕捉到最优值并获得优化空间,但 probs 仍然是零。您知道这是为什么吗?
感谢您出色的教程和绝佳的网站。
我有两个问题
– 关于噪声参数的大小,是否有原则性的思考方法?
– 可以改进 opt_aquisition 中的采样过程以更好地捕捉先验信念吗?
另外,如果有一个关于 TensorFlow Probabilty 的电子书会很棒!🙂 继续保持出色的工作!
你好,
我有一个关于 gp_minimize 的目标函数的问题。
gp_minimize 期望一个标量适应度函数。但是,当我们有一个多输出神经网络(对于一个或多个输入,我们预测多输出)时,如何使用 gp_minimize?在这种情况下,为了调整超参数,我们将有多个目标(适应度)函数。
谢谢!
嗨 Jane……以下讨论提供了一些该领域的有趣想法
https://stats.stackexchange.com/questions/309287/multivariate-gaussian-processing-bayesian-optimization-with-multiple-features
非常感谢您的快速回复。我研究了一下,发现有几本库可以用于使用高斯过程进行多目标贝叶斯优化。您对目前最适合此目的的库有什么推荐吗?
谢谢!
嗨 Jane……您太客气了!有很多很棒的选择,例如以下选项
https://github.com/bayesian-optimization/BayesianOptimization
你好 Jason,我有一个关于贝叶斯优化的问题,我能否使用它来查找由多元线性回归、随机森林等机器学习算法预测的输出的最大值和相应的特征(输入)值?
你好 Usama……是的,贝叶斯优化可以用来查找由多元线性回归、随机森林和其他机器学习算法预测的输出的最大值和相应的特征(输入)值。这种优化方法对于优化昂贵评估的复杂函数特别有用,并且非常适合机器学习模型的超参数调优。
贝叶斯优化通过构建一个概率模型来优化您试图优化的函数,并利用该模型智能地猜测最优点的可能位置。关键思想是利用概率模型来平衡对未访问区域(函数可能达到更高值的区域)的探索与对已知区域(函数已被观察到达到高值的区域)的开发。
在多元线性回归、随机森林等机器学习模型的上下文中,可以使用贝叶斯优化自动查找最大化模型性能的超参数集(或用于特征工程任务的输入特征)。这是通过考虑模型的性能(例如,准确性、F1 分数等)作为要优化的函数来完成的。
例如,如果您正在使用随机森林模型,贝叶斯优化可以帮助您找到最大化模型预测准确性的最佳树的数量、树的深度、每个叶子的最小样本数等。同样,对于多元线性回归,它可能有助于选择影响模型性能的特征或调整其他参数。
为此类目的使用贝叶斯优化,您需要
1. **定义目标函数**:这是以一组参数作为输入并返回性能指标(例如,准确性)作为输出的函数,您希望最大化该函数。
2. **选择一个域空间**:这是您希望优化参数的取值范围。
3. **指定一个代理模型**:这是近似目标函数的概率模型。高斯过程是常用的,但也有其他选择。
4. **决定一个获取函数**:该函数用于决定下一步在哪里采样,平衡探索和开发。
然后,贝叶斯优化通过优化获取函数来迭代地选择要评估的下一组参数,用结果更新代理模型,并重复此过程直到满足停止标准。
它是一个强大的工具,尤其是在目标函数评估非常昂贵(在时间或资源方面)时,并且参数空间高维且难以用简单的优化方法导航时。
你好,
贝叶斯优化、网格搜索和随机搜索可以被视为模型选择技术,如交叉验证、AIC、BIC 等吗?
此致