信息论是数学的一个子领域,关注通过嘈杂信道传输数据的问题。
信息论的基石是量化一条消息中包含多少信息的思想。更广义地讲,这可以用来量化一个事件和随机变量中的信息,称为熵,并使用概率进行计算。
计算信息和熵是机器学习中一个有用的工具,它是一些技术的基础,如特征选择、构建决策树,以及更广泛地,拟合分类模型。因此,机器学习从业者需要对信息和熵有深刻的理解和直观认识。
在这篇文章中,您将了解信息熵的入门介绍。
阅读本文后,你将了解:
- 信息论关注数据压缩和传输,它建立在概率论之上,并为机器学习提供支持。
- 信息提供了一种量化事件意外程度的方法,单位为比特(bits)。
- 熵衡量了表示从一个随机变量的概率分布中抽取的事件所需的平均信息量。
通过我的新书《面向机器学习的概率论》快速启动您的项目,书中包含所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2019年11月更新:增加了概率与信息的示例,以及更多关于熵的直观解释。

信息熵简明介绍
照片由 Cristiano Medeiros Dalbem 拍摄,保留部分权利。
概述
本教程分为三个部分;它们是:
- 什么是信息论?
- 计算事件的信息
- 计算随机变量的熵
什么是信息论?
信息论是一个关注量化通信信息的学科领域。
它是数学的一个子领域,涉及数据压缩和信号处理极限等主题。该领域由克劳德·香农在美国电话公司贝尔实验室工作时提出和发展。
信息论关注以紧凑方式表示数据(一项称为数据压缩或信源编码的任务),以及以抗错误的方式传输和存储数据(一项称为纠错或信道编码的任务)。
— 第56页, 《机器学习:概率视角》, 2012年。
信息论的一个基本概念是量化事件、随机变量和分布等事物中的信息量。
量化信息量需要使用概率,因此信息论与概率论之间存在联系。
信息量度在人工智能和机器学习中被广泛使用,例如在构建决策树和优化分类器模型时。
因此,信息论与机器学习之间存在着重要的关系,从业者必须熟悉该领域的一些基本概念。
为什么要把信息论和机器学习统一起来?因为它们是同一枚硬币的两面。……信息论和机器学习仍然属于一体。大脑是最终的压缩和通信系统。而用于数据压缩和纠错码的最先进算法,与机器学习使用的是相同的工具。
— 第 v 页, 《信息论、推理和学习算法》, 2003年。
想学习机器学习概率吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
计算事件的信息
量化信息是信息论领域的基础。
量化信息背后的直观思想是衡量一个事件中存在多少意外性。那些罕见(低概率)的事件比那些常见(高概率)的事件更令人意外,因此含有更多的信息。
- 低概率事件:高信息(令人意外)。
- 高概率事件:低信息(不足为奇)。
信息论的基本直觉是,得知一个不太可能发生的事件已经发生,比得知一个很可能发生的事件已经发生,更具信息量。
— 第73页,《深度学习》,2016年。
罕见事件更不确定或更令人意外,与常见事件相比,需要更多的信息来表示它们。
我们可以利用事件的概率来计算一个事件中包含的信息量。这被称为“香农信息”、“自信息”,或简称为“信息”,对于一个离散事件 x 可以按如下方式计算:
- 信息(x) = -log( p(x) )
其中 log() 是以2为底的对数,p(x) 是事件 x 的概率。
选择以2为底的对数意味着信息度量的单位是比特(二进制数字)。这可以直接从信息处理的角度解释为表示该事件所需的比特数。
信息的计算通常写作 h();例如:
- h(x) = -log( p(x) )
负号确保结果总是正数或零。
当一个事件的概率为1.0或确定发生时,信息为零,例如,没有意外。
让我们用一些例子来具体说明这一点。
考虑抛掷一枚均匀的硬币。正面(和反面)的概率是0.5。我们可以使用Python中的log2() 函数来计算抛出正面的信息量。
|
1 2 3 4 5 6 7 8 |
# 计算抛硬币的信息量 from math import log2 # 事件的概率 p = 0.5 # 计算事件的信息量 h = -log2(p) # 打印结果 print('p(x)=%.3f, 信息量: %.3f 比特' % (p, h)) |
运行该示例,打印出事件的概率为50%,事件的信息内容为1比特。
|
1 |
p(x)=0.500, 信息量: 1.000 比特 |
如果同一枚硬币被抛掷n次,那么这个抛掷序列的信息量将是n比特。
如果硬币不均匀,正面的概率为10%(0.1),那么该事件会更罕见,需要超过3比特的信息。
|
1 |
p(x)=0.100, 信息量: 3.322 比特 |
我们还可以探究掷一次均匀的六面骰子所包含的信息,例如,掷出6点的信息。
我们知道掷出任何数字的概率是1/6,这个数字比抛硬币的1/2要小,因此我们预期会有更多的意外性或更大的信息量。
|
1 2 3 4 5 6 7 8 |
# 计算掷骰子的信息量 from math import log2 # 事件的概率 p = 1.0 / 6.0 # 计算事件的信息量 h = -log2(p) # 打印结果 print('p(x)=%.3f, 信息量: %.3f 比特' % (p, h)) |
运行该示例,我们可以看到我们的直觉是正确的,确实,掷一次均匀的骰子包含超过2.5比特的信息。
|
1 |
p(x)=0.167, 信息量: 2.585 比特 |
除了以2为底的对数,也可以使用其他对数。例如,在计算信息时,使用以e(欧拉数)为底的自然对数也很常见,这种情况下单位被称为“奈特(nats)”。
我们可以进一步加深低概率事件含有更多信息的直觉。
为了清楚地说明这一点,我们可以计算0到1之间概率的信息,并绘制每个概率对应的信息。然后我们可以创建一个概率与信息的图表。我们预期该图会从低概率高信息向下弯曲到高概率低信息。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 比较概率与信息熵 from math import log2 from matplotlib import pyplot # 概率列表 probs = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] # 计算信息 info = [-log2(p) for p in probs] # 绘制概率与信息的图表 pyplot.plot(probs, info, marker='.') pyplot.title('概率 vs 信息') pyplot.xlabel('概率') pyplot.ylabel('信息') pyplot.show() |
运行该示例会创建概率与信息(单位:比特)的图表。
我们可以看到预期的关系,即低概率事件更令人意外并携带更多信息,而高概率事件则携带较少信息。
我们还可以看到这种关系不是线性的,实际上是略微次线性的。考虑到使用了对数函数,这是合理的。
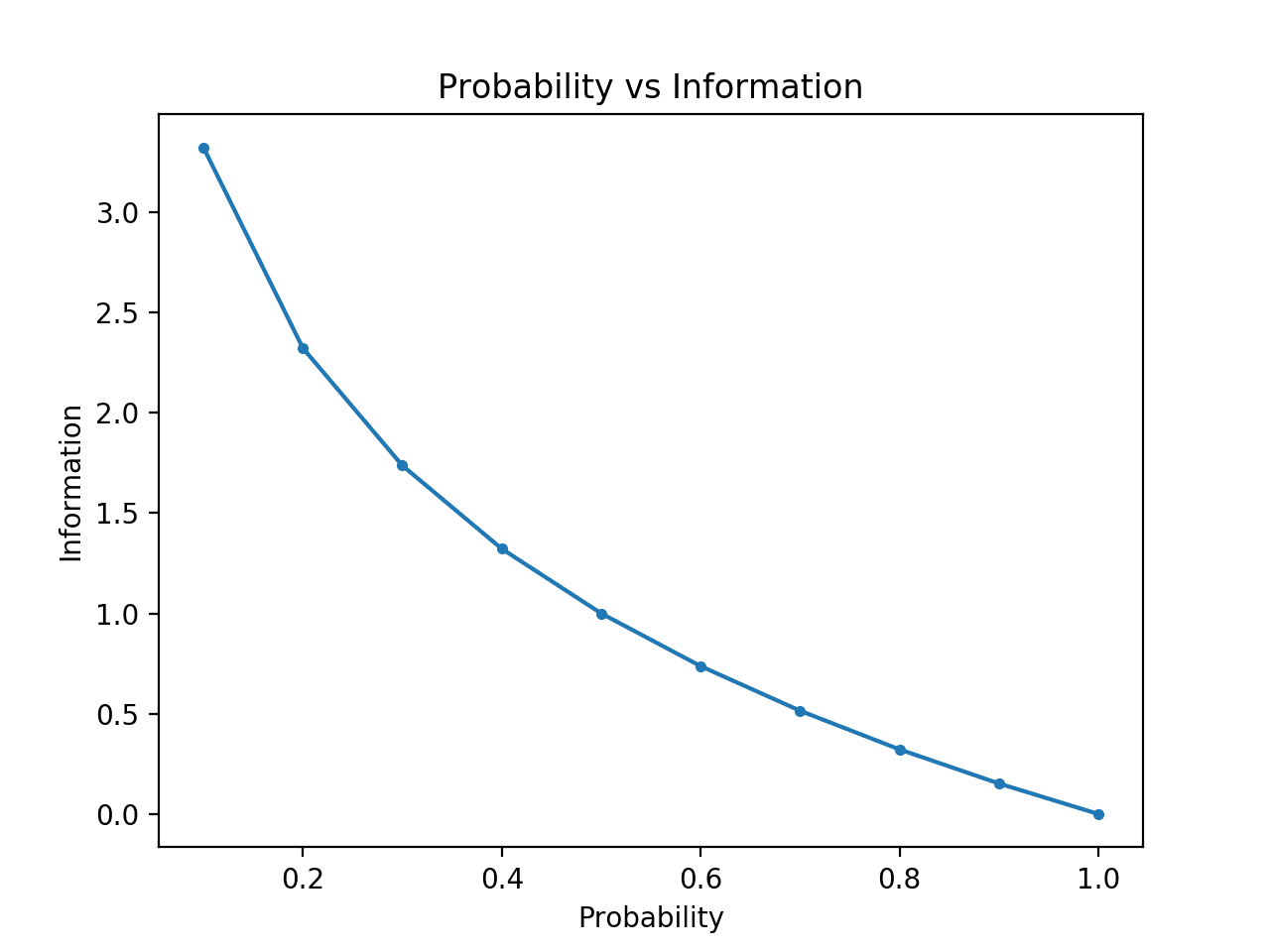
概率与信息的关系图
计算随机变量的熵
我们也可以量化一个随机变量中包含多少信息。
例如,如果我们想计算一个概率分布为 p 的随机变量 X 的信息,这可以写成一个函数 H();例如:
- H(X)
实际上,计算一个随机变量的信息与计算该随机变量事件的概率分布的信息是相同的。
计算随机变量的信息被称为“信息熵”、“香农熵”,或简称为“熵”。它通过类比与物理学中的熵概念相关,因为两者都与不确定性有关。
熵的直观理解是,表示或传输从该随机变量的概率分布中抽取的事件所需的平均比特数。
……一个分布的香农熵是从该分布中抽取的一个事件所包含的预期信息量。它给出了平均编码从分布P中抽取的符号所需的比特数 […] 的下界。
— 第74页,《深度学习》,2016年。
对于具有k个离散状态(其中k在K中)的随机变量X,其熵可以如下计算:
- H(X) = -sum(每个 k in K p(k) * log(p(k)))
即每个事件的概率乘以该事件概率的对数的总和的负值。
与信息量一样,log() 函数使用以2为底的对数,单位是比特。也可以使用自然对数,单位将是奈特。
对于一个随机变量,如果它只有一个概率为1.0的确定事件,那么计算出的熵最低。如果所有事件都等可能,那么该随机变量的熵最大。
我们可以考虑掷一个均匀的骰子,并计算该变量的熵。每个结果的概率都是1/6,因此它是一个均匀概率分布。我们因此预期平均信息量应该与上一节计算的单个事件的信息量相同。
|
1 2 3 4 5 6 7 8 9 10 |
# 计算掷骰子的熵 from math import log2 # 事件的数量 n = 6 # 一个事件的概率 p = 1.0 /n # 计算熵 entropy = -sum([p * log2(p) for _ in range(n)]) # 打印结果 print('熵: %.3f 比特' % entropy) |
运行此示例计算出的熵超过2.5比特,这与单个结果的信息量相同。这是合理的,因为所有结果都是等可能的,所以平均信息量与信息量的下限相同。
|
1 |
熵: 2.585 比特 |
如果我们知道每个事件的概率,我们可以使用 SciPy的entropy()函数直接计算熵。
例如:
|
1 2 3 4 5 6 7 8 |
# 计算掷骰子的熵 from scipy.stats import entropy # 离散概率 p = [1/6, 1/6, 1/6, 1/6, 1/6, 1/6] # 计算熵 e = entropy(p, base=2) # 打印结果 print('熵: %.3f 比特' % e) |
运行这个例子会报告与我们手动计算相同的结果。
|
1 |
熵: 2.585 比特 |
我们可以进一步培养对概率分布熵的直觉。
回想一下,熵是表示从分布中随机抽取一个事件所需的比特数,即一个平均事件。我们可以通过一个简单的包含两个事件的分布来探索这一点,比如抛硬币,但我们会探索这两个事件的不同概率,并为每种情况计算熵。
在某个事件占主导地位的情况下,例如一个倾斜的概率分布,意外程度较低,分布的熵也较低。在没有事件主导其他事件的情况下,例如等概率或近似等概率的分布,我们预期会有更大或最大的熵。
- 偏斜的概率分布(不令人意外):低熵。
- 均衡的概率分布(令人意外):高熵。
如果我们从倾斜的事件概率分布过渡到等概率分布,我们预期熵会从低值开始增加,具体来说,是从不可能/确定事件(概率分别为0和1)的最低熵0.0,增加到等概率事件的最大熵1.0。
下面的例子实现了这一点,创建了这种转变中的每个概率分布,计算了每个分布的熵,并绘制了结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 比较概率分布与熵 from math import log2 from matplotlib import pyplot # 计算熵 def entropy(events, ets=1e-15): return -sum([p * log2(p + ets) for p in events]) # 定义概率 probs = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5] # 创建概率分布 dists = [[p, 1.0 - p] for p in probs] # 计算每个分布的熵 ents = [entropy(d) for d in dists] # 绘制概率分布与熵的图 pyplot.plot(probs, ents, marker='.') pyplot.title('概率分布 vs 熵') pyplot.xticks(probs, [str(d) for d in dists]) pyplot.xlabel('概率分布') pyplot.ylabel('熵 (比特)') pyplot.show() |
运行该示例会创建6个概率分布,从[0,1]概率到[0.5,0.5]概率。
正如预期的那样,我们可以看到,随着事件分布从倾斜变为均衡,熵从最小值增加到最大值。
也就是说,如果从一个概率分布中抽取的平均事件不足为奇,我们得到的熵就较低;而如果它令人惊讶,我们得到的熵就较大。
我们可以看到这种转变不是线性的,而是超线性的。我们还可以看到,如果我们继续这种转变到 [0.6, 0.4] 直到 [1.0, 0.0] 这两个事件,这个曲线是对称的,形成一个倒置的抛物线形状。
请注意,在计算熵时,我们必须在概率上加上一个极小的值,以避免计算零的对数,这会导致无穷大或非数值。
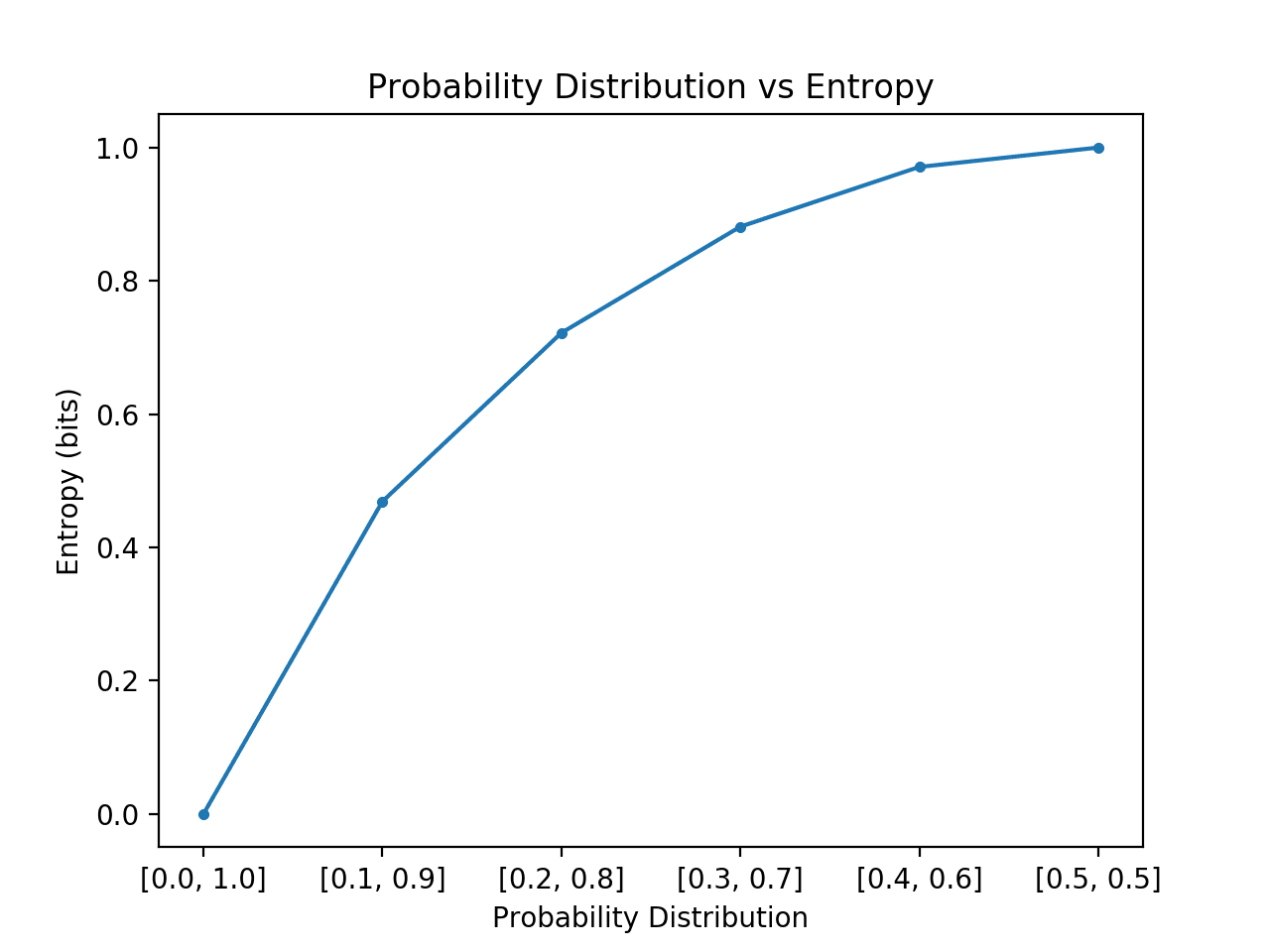
概率分布与熵的关系图
计算随机变量的熵为其他度量提供了基础,例如互信息(信息增益)。
熵也为计算两个概率分布之间的差异提供了基础,如交叉熵和KL散度。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 信息论、推理与学习算法, 2003.
章节
- 2.8节:信息论,《机器学习:概率视角》, 2012.
- 1.6节:信息论,《模式识别与机器学习》, 2006.
- 3.13节 信息论,《深度学习》, 2016.
API
文章
总结
在这篇文章中,您了解了信息熵的入门介绍。
具体来说,你学到了:
- 信息论关注数据压缩和传输,它建立在概率论之上,并为机器学习提供支持。
- 信息提供了一种量化事件意外程度的方法,单位为比特(bits)。
- 熵衡量了表示从一个随机变量的概率分布中抽取的事件所需的平均信息量。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。




 in Keras")


嗯,写成 -sum(i=1 到 K p(i) * log(p(i))) 是不是更好理解?
是的,那是更好的表示法,谢谢你的建议。
我试图在给出公式和不过多吓跑读者(比如不用latex)之间找到平衡。
“如果硬币不均匀,正面的概率为10%(0.1),那么该事件会更罕见,需要超过3比特的信息。”
“一个事件需要超过3比特的信息”是什么意思?当然,无论概率如何,我们都可以用一个比特来发送一个二元变量的结果信息,不是吗?
在这里,我们描述的是变量,而不是单个结果。
如果意外程度或多或少,我们需要更多的信息来编码这个变量——例如,它在通信信道上传输时可能有的值域。
嗨,Jason,
感谢这篇文章,你立刻把我带回了40年前,那时我在读电子工程学位时学过这个。
我想我跟Evgenii有同样的概念障碍,即使看了你的回复,我还是卡住了。换一种方式来问Evgenii的问题:
无论正面或反面的概率是多少,结果仍然只有两种,所以变量只需要一个比特长。那么在正面概率为10%的情况下,如果我有3个比特,另外两个比特会包含什么已经包含在那一个比特变量里的信息呢?
谢谢。
直觉上,我们是在通信一个变量,熵总结了一个变量所有事件的概率分布中的信息,而不是任何单次通信的事件。
x概率分布和y概率分布中各有多少比特的信息?这是熵作为一种度量的重点。或许可以放下通过通信渠道发送比特的想法,这可能会混淆问题。
这有帮助吗?
是的,我想是这样,谢谢你。
我们正在做的是定义一个变量,它包含我们称之为“信息”或“熵”的东西;这个信息传达了什么,目前是未知且无关紧要的。(它当然不是任何特定事件的结果)。
我们能做的是计算出这个变量需要多大,这正是你在这里煞费苦心描述的内容。
是的,总结得很好!
布朗利博士,您好,
首先,我想对您在机器学习领域的杰出文章表示感谢。
其次,关于您的论点
“如果意外程度有高有低,我们需要更多的信息来编码变量——例如,它在通信信道上传输时可能具有的值的范围。”
您能详细说明一下,在正面概率为10%(0.1)的情况下,需要3比特的值域具体是什么吗?
最后,很抱歉问这么简单的问题,但我是这个领域的新手,非常感谢您的反馈。
此致,
不客气。
值的范围?就是正面或反面。
或许我没理解你的问题?
这是一篇非常好的文章,谢谢🙂
问题:有没有什么方法可以这样总结,比如‘为了传输硬币的‘不公平性’,你需要这么多比特,假设你需要1比特来说明“硬币是公平的”?’
我想我真的在尝试将此与某种形式的“信息”联系起来,这种信息对应于正在讨论的“3比特信息”的例子,但对我来说也似乎很直观。我是不是在白费力气?😀
谢谢。
是的,除了关于公平硬币的部分。我们正在总结事件(信息)或分布(熵)的传输——用一个度量来捕捉它们的属性,而不是陈述它们。
谈论通过通信渠道发送数据的描述可能会有所帮助。也许“延伸阅读”部分的参考资料会有所帮助。
我认为带权重的硬币例子有点令人困惑,因为硬币仍然只有两种状态。而在我看来,一个八面骰子的例子会更好,因为它清楚地表明你需要3个比特来表示8个状态(2^3),而1个比特来表示2个状态(2^1),也就是硬币。
恭喜您写了这么多好文章!我从您的解释中学到了很多。
谢谢!
你能否更详细地解释一下“信息”是什么?例如,当抛硬币的概率较低时,需要更多的“信息”。当你使用“信息”这个词时,你指的是什么?
我读了Evgenii发起的那个帖子,但对我来说还是没有弄清楚。
这里有另一种思考方式:
信息是衡量我们压缩来自一个分布的事件的能力。熵是衡量我们压缩事件概率分布的能力。
当我们计算实际的信息比特数时,这个单位是任意的吗?还是它可以直接与计算机存储信息所需的比特数相对应?
如果是后者,对于抛硬币50%成功率和10%成功率这两种情况,计算机上存储的确切信息会是什么?我想我理解上的问题在于没有直接看到信息是什么。
感谢您的帖子,它们总是很有帮助!
嗯,它可以与变量/分布的压缩相关联。
在机器学习中,它作为与其他情况进行比较的相对分数最有用。
也许如果你给他们一个过于具体的例子
假设你将你的10%/90%的硬币抛了一百万次,并想将这一百万次长的序列传输到另一个计算机节点。一个非常简单的游程编码可以让你用少得多的比特来描述长串的90%结果(我们称之为正面)。这正是你在电话中转述序列时会做的事情
“那是一个反面,接着是5个正面,一个反面,接着是8个正面,等等。”
这立即显示了每个正面所包含的减少了的信息内容。现在你希望对正面的描述尽可能紧凑——但数据流现在是不均匀的:我如何区分一个表示反面的比特和一个反映计数(游程长度)的多比特“结构”?你最终会为每个反面事件创建一个多比特结构——一个在游程长度描述符中不允许出现的特殊多比特结构。反面越不频繁,你愿意为标记反面事件付出的代价就越大——因为那个标记越长,描述游程长度的成本就越低(更容易避免那个标记反面事件的特殊多比特代码)。
希望这个例子有帮助。
非常酷的例子,谢谢分享!
很棒的文章。香农熵与不同概率分布的图是针对二元随机变量的。
正确。
偶然发现了你的博客!使用以2为底的对数与自然对数计算熵有什么优势/原因吗?
以2为底的对数让你使用“比特”这个单位,这是最常见的用法。
解释得非常清楚!
我想知道您能否用实际例子更详细地阐述熵值的使用。我们将解决什么样的问题?
谢谢!
在机器学习中,我们经常使用交叉熵和信息增益,这些都需要以理解熵为基础。
你写道“因此比那些常见的事件有更多的信息”,但你的意思是“因此比那些常见的事件有更多的信息”。
是的,谢谢。已修正。
嗨,Jason,
我们能将信息视为均匀概率分布(事件等可能)下熵的一种特殊情况吗?
不完全是,信息是关于一个事件的,而熵是关于一个分布的。
这句话有点令人困惑:“更广义地讲,这可以用来量化一个事件和随机变量中的信息,称为熵,并使用概率进行计算。”您想表达的是否是:“更广义地讲,这可以用来量化一个事件中的信息,也可以量化一个随机变量中的信息(称为熵),并且在这两种情况下都使用概率进行计算。”?
也许可以。
注意,我们衡量事件的“信息”。我们衡量变量/分布的“熵”。
你也可以把可汗学院的这个视频加到你的资源里。
https://www.khanacademy.org/computing/computer-science/informationtheory/moderninfotheory/v/information-entropy
感谢分享。
感谢您的文章 ^_^
在某处:“回想一下,熵是表示从分布中随机抽取一个偶数(even)所需的比特数”
我想你的意思是“事件(event)”而不是“偶数(even)”?
不客气。
谢谢。
非常棒的文章,真心感谢您在这方面的工作。
不确定这是否对其他人有帮助,但我之前一直不理解log中的1/p是从哪里来的,以及为什么不使用1-p或其他度量。帮助我建立直觉的是意识到,如果每个事件的概率都是p,那么1/p就是我们需要编码一个均匀分布所需的比特数。所以信息量,-log(1/p),就是如果该事件是均匀分布的一部分,它“值”多少比特。我发现这有助于记忆公式。一个均匀分布也将是该事件在其给定概率下可能来自的最大熵分布……尽管在解释信息之前你不能提及熵🙂 总之,这篇文章的中间部分对这一点有更详细的介绍,如果有人对这一点特别好奇的话 https://scriptreference.com/information-theory-for-machine-learning/
谢谢分享,Mike!
哎呀抱歉,上面有个笔误……我想说的是“信息,-log(p),是如果该事件是一个均匀分布的一部分,它会‘值’多少比特。”而不是-log(1/p)。
这是因为1/p是一个均匀分布需要多少个事件,才能使每个事件的概率为p。所以log(1/p)是用二进制编码该分布中所有事件所需的比特数。log(1/p) = log(1) - log(p) = -log(p)
离散和连续随机变量的熵的界限是什么?
熵应该在0和1之间,但这取决于概率密度函数。
嗨,Jason,
很棒的博客文章,非常感谢。但我脑子里还有一个问题。如果例如一段英文文本在加密前被转换成一个随机字符序列,香农熵(H)将如何应用?让我们假设一个马尔可夫过程,为每个明文字符生成一个随机排列,并将字符映射到该排列上——m → tm。如果我们现在应用模运算,并且k(密钥)也是一个随机选择的字符,方程就变成 tm + k | mod26 = c。香农熵要求C(密文)可以与一个本身可以被测量的属性进行比较(在我的例子中是有意义的英文)。香农指出,使用Vernam密码(今天的一次性密码本)时,需要 RMLM ≤ RKLK 来保持完美保密。通过转换明文,密钥不再需要是香农建议的无限符号串,因为tm和k都持有1/26的概率。模运算可能会产生一个合理的密文,但它很可能不是原始的明文。
抱歉,忘了提这种操作方式也可以应用于十六进制和二进制系统。
嗨,Jason,
很棒的博客文章,非常感谢。但我脑子里还有一个问题。如果例如一段英文文本在加密前被转换成一个随机字符序列,香农熵(H)将如何应用?让我们假设一个马尔可夫过程,为每个明文字符生成一个随机排列,并将字符映射到该排列上——m → tm。如果我们现在应用模运算,并且k(密钥)也是一个随机选择的字符,方程就变成 tm + k | mod26 = c。香农熵要求C(密文)可以与一个本身可以被测量的属性进行比较(在我的例子中是有意义的英文)。香农指出,使用Vernam密码(今天的一次性密码本)时,需要 RMLM ≤ RKLK 来保持完美保密。通过转换明文,密钥不再需要是香农建议的无限符号串,因为tm和k都持有1/26的概率。模运算可能会产生一个合理的密文,但它很可能不是原始的明文。这种操作方式也可以应用于十六进制和二进制系统。
你好 Wandee…请简化你的问题,以便我能更好地帮助你。
你好,
你能给我推荐一些关于集整形理论的文章吗?
我对这个新理论非常感兴趣。
你好 Aron...感谢你提出的建议,我们会考虑的!
在以下声明中
信息论的一个基本概念是量化事件、随机变量和分布等事物中的信息量。
是否应该说
信息论的一个基本概念是对事件、随机变量和分布等事物中信息量的量化。
它现在的措辞对我来说有点令人困惑。
嗨,Jason,
在使用交叉熵损失来训练模型并找到最佳拟合时,我们是否在试图最小化该值可能出现的可能性(传输的信息),从而使其不那么令人意外?
感谢这篇引人深思的文章。
你好 Jun...感谢你的反馈!是的...你的理解是正确的。
不考虑事件视界,黑洞的熵是高还是低?
你好 Trevor...即使不考虑事件视界,黑洞也具有**极高的熵**。这是因为从根本上说,熵是衡量一个系统在保持相同宏观属性的同时可能拥有的微观状态数量的度量。
### **为什么黑洞有高熵?**
1. **引力坍缩与信息丢失:**当物质坍缩成黑洞时,初始系统的所有微观状态实际上都被“抹平”成一个由质量、电荷和自旋定义的单一宏观状态。然而,热力学第二定律表明熵不应减少,这意味着黑洞本身必须拥有大量的内部微观状态。
2. **量子引力中的自由度:**在弦理论和全息原理等理论中,黑洞被认为拥有巨大的量子态数量,对应于可能编码了形成黑洞的所有物质信息的内部构型。
3. **能量与熵的关系:**高能系统往往具有更高的熵。由于黑洞代表了储存能量最紧凑的方式(由于极端的引力束缚),它们被期望在给定质量下具有最大的熵。
4. **热行为:**黑洞热力学的研究表明,它们通过霍金辐射来辐射能量,表现得像具有明确熵的热力学物体。由于熵与系统的热容量有关,并且黑洞相对于其给定能量具有非常高的有效温度,因此它们的熵必须是巨大的。
因此,黑洞拥有物理学中已知的一些最高熵,这与它们在引力束缚系统中最大化无序和信息存储的观点是一致的。