您对机器学习感兴趣,也许您还略知一二。
如果您有一天和朋友或同事谈论机器学习,您可能会被问到:
“那么,什么是机器学习?”
这篇文章的目标是为您提供一些可以思考的定义,以及一个易于记忆的实用一句话定义。
我们将从机器学习的标准定义开始,这些定义取自该领域的权威教科书。最后,我们将提出一个开发者对机器学习的定义和一个实用的“一句话”定义,以便我们随时可以回答:“什么是机器学习?”。
权威定义
让我们先来看看四本在大学课程中常用的机器学习教科书。
这些是我们的权威定义,为我们深入思考该主题奠定了基础。
我选择这四个定义是为了突出该领域一些有用且多样的观点。通过经验,我们将了解到该领域确实是方法论的混乱集合,选择一个视角是取得进展的关键。
Mitchell的机器学习
Tom Mitchell在他的《机器学习》一书中,在前言的开头提供了这样一个定义:
机器学习领域关注的问题是如何构建能够通过经验自动改进的计算机程序。
我喜欢这个简洁明了的定义,它是我们将在文章结尾提出的开发者定义的基础。
请注意提到了“计算机程序”和“自动化改进”。编写能够自我改进的程序,这非常引人深思!
在他的介绍中,他提供了一个被广泛引用的简短形式化定义:
不要被术语定义吓倒,这是一个非常有用的形式化。
我们可以将此形式化用作模板,将E、T和P放在表格的列首,并列出复杂的问题,从而减少歧义。它可以作为设计工具,帮助我们清晰地思考要收集哪些数据(E),软件需要做出哪些决策(T),以及我们将如何评估其结果(P)。这种能力使其被反复引用为标准定义。请将其记在心里。
统计学习要素
《统计学习要素:数据挖掘、推理与预测》由三位斯坦福大学的统计学家撰写,他们自称为组织其研究领域的统计学框架。
在前言中写道:
许多领域正在生成海量数据,统计学家的工作就是理解这一切:提取重要的模式和趋势,并理解“数据说明了什么”。我们称之为从数据中学习。
我理解统计学家的工作是利用统计学工具,在特定领域背景下解释数据。作者似乎将机器学习的整个领域都包含在这一追求中。有趣的是,他们在书的副标题中选择了“数据挖掘”。
统计学家从数据中学习,软件也如此,而我们则从软件学习的东西中学习。从各种机器学习方法所做的决策和取得的结果中学习。
模式识别
Bishop在他的《模式识别与机器学习》一书的前言中评论道:
模式识别起源于工程领域,而机器学习则源于计算机科学。然而,这些活动可以被视为同一领域的两个方面……
读到这里,你会觉得Bishop是从工程角度切入该领域的,后来才学习并利用了计算机科学对同一方法的视角。模式识别是一个工程或信号处理术语。
这是一种成熟的方法,也是我们应该效仿的。更广泛地说,无论哪个领域声称拥有某种方法,只要它能帮助我们更接近洞察或通过“从数据中学习”来获得结果,满足我们的需求,那么我们就可以将其称为机器学习。
算法视角
Marsland在他的《机器学习:算法视角》一书中采用了Mitchell对机器学习的定义。
他在序言中提供了一个发人深省的观点,激励他写这本书:
机器学习最有趣的特点之一是它横跨了几个不同的学术领域,主要是计算机科学、统计学、数学和工程学……机器学习通常被作为人工智能的一部分来研究,这使其牢牢地属于计算机科学的范畴……理解这些算法为何有效需要一定程度的统计学和数学上的成熟度,而这在计算机科学本科生中常常是缺失的。
这很有见地且具启发性。
首先,他强调了该领域的跨学科性。我们从上面的定义中已经感受到了这一点,但他对此作了明确的强调。机器学习借鉴了各种信息科学。
其次,他强调了过于固守某个特定视角的危险。特别是,算法专家回避方法的数学内部运作的情况。
毫无疑问,统计学家回避实施和部署的实际问题的反例同样具有局限性。
文氏图
Drew Conway在2010年9月创建了一个精美的文氏图,可能会有所帮助。
在他解释中,他评论道:机器学习 = 黑客技术 + 数学与统计学
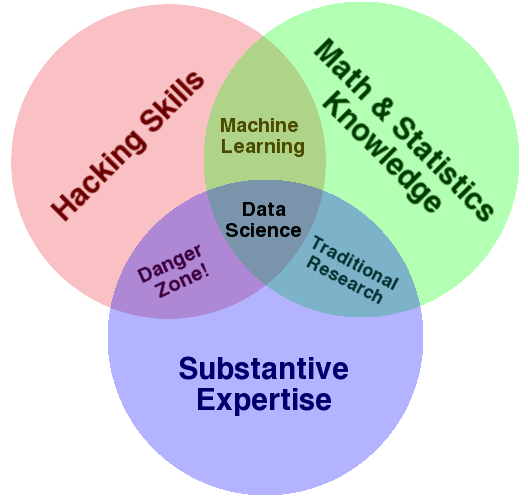
数据科学文氏图。归功于Drew Conway,知识共享许可为署名-非商业性使用。
他还描述了危险区域为黑客技能+专业知识。
在这里,他指的是那些了解程度足以造成危险的人。他们能够访问和构建数据,了解领域知识,并且能够运行方法并呈现结果,但却不理解结果的含义。我认为这可能就是Marsland在暗示的。
开发者的机器学习定义
现在,我们转向为我们开发者将所有这些分解为基础知识的必要性。
我们首先审视那些难以分解和程序化解决的复杂问题。这凸显了机器学习的力量。然后,我们将制定一个适合我们开发者、并且可以随时回答“那么,什么是机器学习?”的定义。
复杂问题
作为一名开发者,您最终会遇到一些顽固地拒绝逻辑和程序化解决方案的问题类别。
我的意思是,有些问题类别,坐下来写出解决问题所需的所有if语句是不可行的或不经济的。
“亵渎神圣!”我听到你的开发者大脑在尖叫。
这是真的。
以识别垃圾邮件和非垃圾邮件的日常决策问题为例。这是介绍机器学习时经常使用的例子。您将如何编写一个程序来过滤您电子邮件账户收到的电子邮件,并决定将其放入垃圾邮件文件夹还是收件箱?
您可能会先收集一些例子,然后仔细看看并深入思考。您会寻找垃圾邮件和非垃圾邮件中的模式。您会考虑抽象这些模式,以便您的启发式方法能够处理未来的新情况。您会忽略那些永远不会再次出现的奇怪电子邮件。您会争取轻松获胜,以提高准确性,并为边缘情况 craft 特殊的东西。您会定期审查电子邮件,并考虑抽象新模式以改进决策。
其中存在一个机器学习算法,但它是由您(程序员)而不是计算机执行的。这种手动导出的硬编码系统只会和程序员从数据中提取规则并将其实现到程序中的能力一样好。
可以做到,但这将耗费大量资源,并且是维护的噩梦。
机器学习
在上面的例子中,我确信您的开发者大脑,那个无情地寻求自动化的部分,能够看到从示例中提取模式的元过程的自动化和优化机会。
机器学习方法就是这种自动化过程。
在我们对垃圾邮件/非垃圾邮件的例子中,例子(E)是我们收集的电子邮件。任务(T)是一个决策问题(称为分类),即将每封电子邮件标记为垃圾邮件或非垃圾邮件,并将其放入正确的文件夹。我们的性能度量(P)可能是准确率百分比(正确决策数除以总决策数乘以100),范围从0%(最差)到100%(最好)。
准备这样一个决策程序通常称为训练,其中收集的例子称为训练集,程序被称为模型,就像垃圾邮件分类问题的模型一样。作为开发者,我们喜欢这个术语,模型具有状态并且需要持久化,训练是一个执行一次的过程,并且可能会根据需要重新运行,分类是执行的任务。这一切对我们来说都有意义。
我们可以看到,上面定义中使用的一些术语对程序员来说不太合适。从技术上讲,我们编写的所有程序都是自动化,评论说机器学习会自动学习是没有意义的。
实用的“一句话”定义
那么,让我们看看是否可以使用这些部分来构建一个开发者的机器学习定义。怎么样?
机器学习是从数据中训练模型,该模型根据性能度量来泛化决策。
训练模型暗示了训练示例。模型暗示了通过经验获得的状态。泛化决策暗示了根据输入做出决策的能力,并预期未来需要决策的未见输入。最后,根据性能度量暗示了目标需求和模型准备的方向性。
我不是诗人,您能想出更准确或更简洁的开发者机器学习定义吗?
在下面的评论中分享您的定义。
进一步阅读
我在整篇文章中都提供了链接资源,但如果您渴望阅读更多内容,我在此列出了一些有用的资源。
书籍
以下是文中引用了定义的四本教科书。
- 机器学习 by Mitchell
- 统计学习要素:数据挖掘、推理与预测 by Hastie, Tibshirani and Friedman
- 模式识别与机器学习 by Bishop
- 机器学习:算法视角 by Marsland。
此外,Drew Conway与John Myles White合作撰写了一本实用且有趣的名为《机器学习黑客之道》的书。
问答网站
问答网站上有一些关于机器学习到底是什么的有趣讨论,以下是一些精选:
- Quora非常适合这类高层次的问题,请浏览一些。我的选择是:通俗易懂的机器学习是什么? 和 什么是数据科学?
- Cross Validated在此类高层次问题上有一些精彩的讨论。请参阅两种文化:统计学vs机器学习?。此讨论中提到的两个资源是博客文章统计学vs机器学习,开战!和论文统计建模:两种文化。
- Stack Overflow也有一些讨论,例如,请查看什么是机器学习?
我认真思考了所有这些,我的定义受到我读过的书和我的经验的影响。如果它有用,请告诉我。
请留下评论,让我们所有人都知道您如何理解这个领域。您眼中的机器学习是什么?您知道还有哪些我们可以参考的资源吗?
在下面的评论中告诉我。






感谢您收集这些引言并在此过程中形成自己的观点。见解深刻,我很享受。感谢您的分享。
Vikash,非常欢迎!
对机器学习的精彩介绍——程序员们能懂!
很高兴有人乐于分享知识。谢谢。
还有一件事。机器学习和统计学之间有什么关系?
正如文氏图部分所述,无需精通统计学,也可以通过数据开发学习的应用程序。但是,创造一个未能从数据中提取真正信息的模型的可能性很高。
我不完全同意。
我认为你可以开车而不理解引擎如何工作,或者解决一个业务问题而不需要理解计算理论。
没错,但有时理解会有帮助。我“黑”了我的起亚索兰托,在多山的地形上获得了惊人的油耗。那天开车八小时,最后两小时才把女儿送到作家集会。我以每小时45英里的速度在高原和缓坡上行驶,比限速稍低。当快到下坡时,我减速并使用无离合器换挡下降。有一次,一辆卡车在我后面,而那正好是第二条行车道,所以我让它过去了。否则,我发现通过在下坡时降档,我可以在更合理的速度下通过弯道,而无需刹车,并且不会在弯道上过度补偿。我的全轮驱动汽车的油耗是26.5英里/加仑,而额定值为24英里/加仑(高速公路)。我的成功部分归功于重力,但使用发动机摩擦力也是我成功的一部分!所以,这并不代表对引擎有太多的理解,但我确实理解了系统。
是的,但你不需要这种理解就能开始,甚至不需要跨州旅行。
这是在基础知识覆盖并交付价值之后的一个很好的下一步。
博士研究和研究助理的压力让我措手不及。我花了些时间仔细阅读了您今天的帖子。说实话,这篇文章让我的头脑轻松了,赠予了知识。谢谢Jason博士。
非常欢迎。
很高兴知道这一点,我一直在努力用家人能理解的方式向他们解释我的职业道路。
这是我的实用“一句话”定义:ML是一个需要根据数据针对结果度量来探索的决策问题。
机器学习是创造计算机软件的艺术与科学,该软件在重复使用后结果会更加准确。
谢谢Jim。
Jason博士,您的解释非常到位。我正在使用人工神经网络预测混凝土碳化深度。我和同事一起准备了一个算法,但对土木工程师来说,计算机编程并不容易。我将来会阅读您的课程,谢谢。
很高兴您觉得有用,Yasmina。
感谢您分享这些精彩的帖子。您一直在做很多有趣的工作。
您如何保持对ML的热情?
谢谢Van-Hau Nguyen。
我保持兴趣是因为每一天都是新的挑战。没有“正确”的答案,总有更多需要学习和改进的东西。
另外,我喜欢帮助初学者入门,让他们看到应用的便捷性。
太棒了!作为一个非程序员,我的“一句话”可能是:机器学习是利用数据创建模型,然后使用该模型进行预测。
我理解得对吗?或者我的“一句话”有什么缺失?
Julien,我喜欢这个!清晰、简洁且实用。
坚实的ML参考材料,我从一个关于预测分析的搜索开始,现在我受到了启发,一直阅读到您的101系列帖子。工作出色,感谢。
谢谢。
我的“一句话”是:通过使用计算机算法训练数据以获得最大准确性来做出更好的预测。
Bolanle,很棒。
非常感谢!我喜欢它。
我想知道,是否需要非常精通Python编程才能使用机器学习技术?
我在攻读硕士学位时意识到,我的导师让我自己实现一个模型,我需要修改一个Python包才能让模型工作。然而,由于我不太擅长Python的面向对象编程,我为此付出了很多努力。
我想在应用于健康的机器学习领域攻读博士学位。然而,我目前正在考虑,鉴于我平庸的编程技能,我能否在这里生存下来。
您认为我应该怎么做?
我不认为您需要成为一个出色的程序员才能通过应用机器学习交付有用且有价值的结果。
请看这篇文章
https://machinelearning.org.cn/machine-learning-for-programmers/
总的来说,我建议您专注于学习如何端到端地解决预测建模问题,并使用像sklearn这样的库和Weka这样的工具来交付结果。
练习您的Python编程技能,它们会提高的。
而且这甚至很有趣!:)
赞成。
谢谢你,Jason。
我刚开始我的ML之旅,您的文章非常有启发性和易于理解。
谢谢Phillip,很高兴听到这个。
看看这个关于机器学习通俗理解的视频
https://www.youtube.com/watch?v=RaDFiMd-Amg
感谢分享。
感谢您如此漂亮的博客!:)
不客气。
多么棒的文章,Jason!恭喜!
谢谢。
有时我认为,在传统编程中,对于开发者来说,“程序”是主要的焦点,但在机器学习程序中,焦点转移到了数据。
无论有多少/多长时间的数据被输入,程序的工作方式都是相同的,但机器学习程序会随着我们输入更多/更长时间的数据而变得更智能。
这是一个非常好的观察!
感谢精彩的介绍!
不客气。
这是一次精彩的开端,涵盖了大量内容,有助于理解机器学习。我认为随着经验的增长,对所有这些说法会更有体会。
很高兴它有帮助。
非常棒的一篇文章!!!
你征求反馈意见
我认为您最后的定义缺少对计算机或编程的任何提及。虽然对于那些习惯使用计算机术语的人来说可能是隐含的,但我会加上:“机器学习是从数据中训练模型,该模型根据性能度量来泛化决策。”
那么,这是仅限于标记数据吗?预先存在的模型?如果不是,那是不是应该是“训练到模型”?我认为这样可以包含这两种情况?
最后,在康威的维恩图(Conway’s Venn Diagram)中,我没有看到伦理道德方面的内容。这可能是对机械师(开发人员)和未来最大的危险,在关于人工智能的每一篇文章中都应该提到。我个人意见,谢谢!
谢谢。
我的概念是,机器学习是一个领域,用于从数据中创建有用的数学模型。(“有用”一词包含了度量)
不错。
“机器学习(ML)是学习已有数据的科学,目的是创建能够从中提取隐藏信息或识别、生成和预测未知数据的模型。”
你怎么看?
这引出了监督/无监督方法、判别/生成模型、分类/回归任务。
非常好!
谢谢,Jason。我是数据科学新手,一直在寻找更好的机器学习学习方法。你的博客很好,而且确实为我开始了解机器学习提供了一个结构良好的途径。
我的定义是,机器学习是基于可用数据泛化模型的科学,并利用该模型预测未来模式。
你觉得呢?
Sridhar,听起来很棒。
你好,读了你的机器学习博客,真的很棒。
我也开始写机器学习博客了。您能检查一下并给我一些反馈,以便我改进吗?
链接:https://learn-ml.com/
干得好!
简单且非常好的机器学习介绍……我喜欢Jim Kitzmiller的评论——“机器学习是创建计算机软件的艺术和科学,该软件在使用后会产生更准确的结果”。
谢谢。
在读了您的博客之后,我真的发现了机器学习是多么迷人。
感谢您如此精彩的介绍。
不客气!
很棒的文章
谢谢!
很棒的内容,我只是好奇您对其他内容的看法,太棒了。
谢谢。
写得真好,兄弟……
谢谢!
定义作为相对近似值,提供了不同的观点,这些观点构成了构建多维概念模型的重要信息。感谢分享。
感谢分享。
你好,Jason!你好吗?
我决定涉足数据科学已经两年了,直到现在我才找到你的课程,我认为我找到了一个前进的方向。
所以,你可能会经常看到我在这里🙂
我对机器学习的定义是
“机器学习是我们使用一套资源(计算和理论)来构建一个工具,帮助我们在面对复杂问题时做出决策”
我尝试用这个定义来解决以下问题
复杂问题
– 我们需要机器的原因
– 设定学习空间的界限
计算资源
– 我们基本上(粗略地说)使用计算机来存储和处理数据。在尝试让计算机学习时,我们将这些基本的东西提升到更高的水平
– 存储数据 -> 大数据 -> 分布式存储,等等。
– 处理数据 -> 使用GPU、并行处理、量子处理等。
– 更好的算法来处理计算
理论资源
– 揭示了该领域的多学科性:数学、统计学、信息论、软件工程,所有人都来帮助我们从数据中学习
构建一个工具
– 机器学习的结果是一个模型
– 模型由我们正在处理的问题的表示组成,并且将对其进行评估和优化(我考虑的是Palacio的框架),因为它只是现实问题世界的一个近似图景
– 我们可以使用几种技术来弄清楚隐藏在数据集(我们用数字、文本和图像等提炼出的问题世界)后面的隐藏结构。
– 我们可以称这些技术为学习算法、目标函数和优化函数
做出决策
– 所有这一切的目标是推断出一个响应,当我们面对一个新颖复杂的局面时,能引导我们做出更好的选择
– 我们的模型将帮助我们从已知情况推广到新情况
抱歉占用了这么多空间,
此致
Edy
你好 Edy…请将你的问题缩小到一个,以便我们能更好地帮助你。
你好,James!你好吗?
我一直在考虑机器学习的这个定义
“机器学习是我们使用一套资源(计算和理论)来构建一个工具,帮助我们在面对复杂问题时做出决策”
这有意义吗?
谢谢
你好 Edy…这是一个非常棒的定义!以下内容将是您机器学习之旅的一个极好的起点
https://machinelearning.org.cn/start-here/
你好,
所以,我一直在想这个机器学习定义是否可以。
“机器学习是我们使用一套资源(计算和理论)来构建一个工具,帮助我们在面对复杂问题时做出决策”
谢谢
机器学习是从历史数据构建模型以使机器能够预测或分析而无需显式编程的过程。
清晰且赋权!您通过易于理解的定义和实际类比简化了机器学习的概念,使复杂的想法易于掌握。
谢谢 Peol 的反馈和支持!请继续关注您的进展!