XGBoost算法对于广泛的回归和分类预测建模问题都非常有效。
它是随机梯度提升算法的有效实现,并提供一系列超参数,可以对模型训练过程进行精细控制。尽管该算法通常表现良好,即使在不平衡分类数据集上也是如此,但它提供了一种调整训练算法的方法,使其对于具有偏斜类别分布的数据集更关注少数类别的错误分类。
XGBoost的这个修改版本被称为“类别加权XGBoost”或“成本敏感型XGBoost”,可以在具有严重类别不平衡的二元分类问题上提供更好的性能。
在本教程中,您将学习用于不平衡分类的加权XGBoost。
完成本教程后,您将了解:
- 从高层次上理解梯度提升的工作原理,以及如何开发用于分类的XGBoost模型。
- 如何修改XGBoost训练算法,使其在训练期间根据正类别的重要性按比例加权错误梯度。
- 如何为XGBoost训练算法配置正类别权重,以及如何网格搜索不同的配置。
使用我的新书《使用Python进行不平衡分类》启动您的项目,包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何为不平衡分类配置 XGBoost
图片由flowcomm提供,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 不平衡分类数据集
- 用于分类的XGBoost模型
- 用于类别不平衡的加权XGBoost
- 调整类别加权超参数
不平衡分类数据集
在我们深入探讨用于不平衡分类的XGBoost之前,我们首先定义一个不平衡分类数据集。
我们可以使用scikit-learn的make_classification()函数来定义一个合成的不平衡二类别分类数据集。我们将生成10,000个样本,少数类别与多数类别的比例大约为1:100。
|
1 2 3 4 |
... # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=7) |
生成后,我们可以总结类别分布,以确认数据集的创建符合预期。
|
1 2 3 4 |
... # 总结类别分布 counter = Counter(y) print(counter) |
最后,我们可以创建一个样本的散点图,并根据类别标签对其进行着色,以帮助理解对该数据集中的样本进行分类的挑战。
|
1 2 3 4 5 6 7 |
... # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
综合起来,生成合成数据集并绘制样本的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成并绘制一个合成的不平衡分类数据集 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=7) # 总结类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先创建数据集并总结类别分布。
我们可以看到数据集的类别分布约为1:100,多数类有不到10,000个样本,少数类有100个样本。
|
1 |
Counter({0: 9900, 1: 100}) |
接下来,创建数据集的散点图,显示多数类(蓝色)的大量样本和少数类(橙色)的少量样本,并存在一些适度的类别重叠。
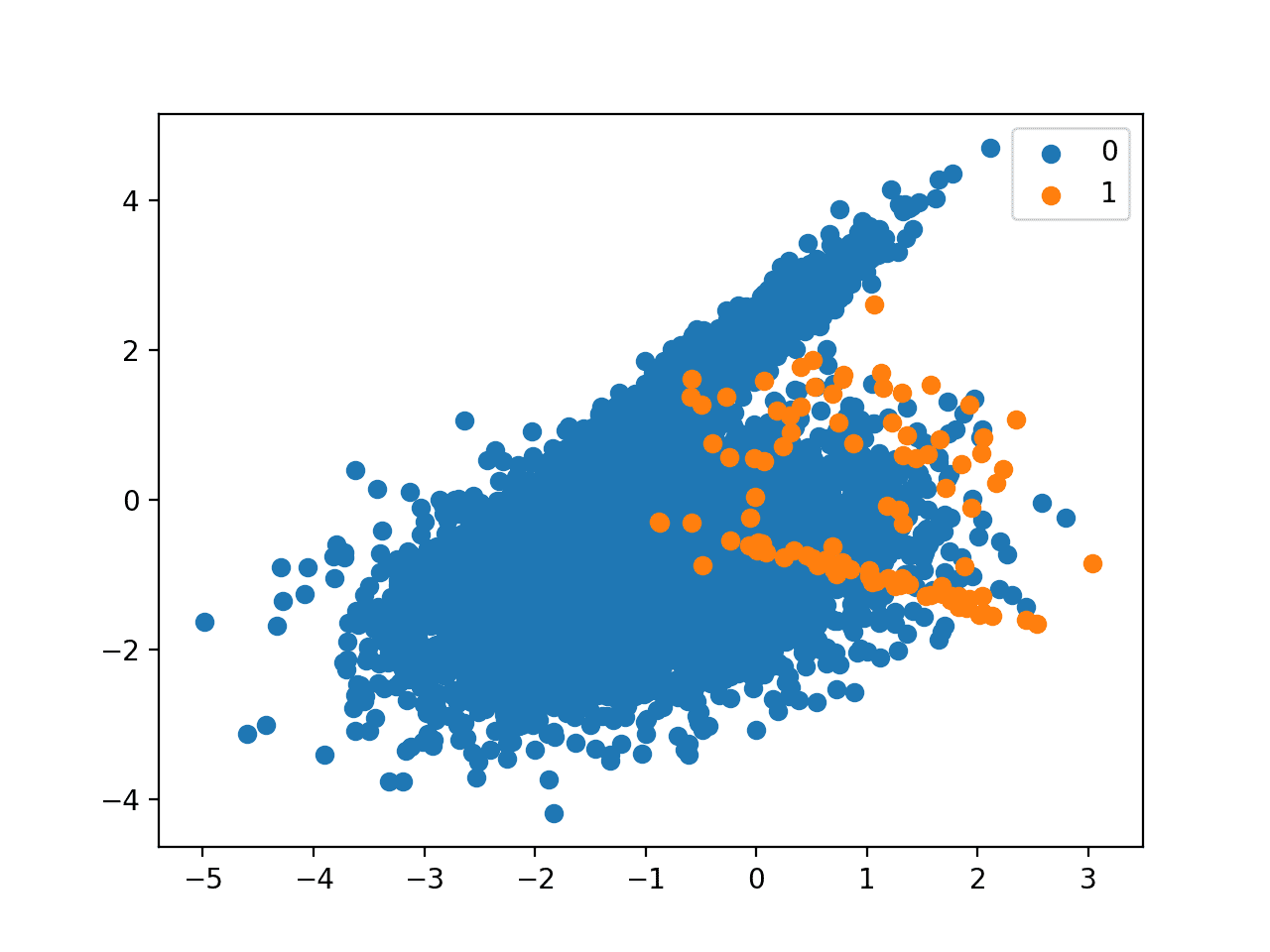
具有1比100类别不平衡的二元分类数据集散点图
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
用于分类的XGBoost模型
XGBoost是极限梯度提升的缩写,是随机梯度提升机器学习算法的高效实现。
随机梯度提升算法,也称为梯度提升机或树提升,是一种强大的机器学习技术,在各种具有挑战性的机器学习问题上表现良好甚至最佳。
决策树提升已被证明在许多标准分类基准上产生最先进的结果。
— XGBoost: A Scalable Tree Boosting System, 2016。
它是一种决策树集成算法,其中新树纠正模型中已有树的错误。树被添加,直到模型不能再进一步改进。
XGBoost提供了随机梯度提升算法的高效实现,并提供了一套模型超参数,旨在控制模型训练过程。
XGBoost成功的最重要因素是其在所有场景中的可扩展性。该系统在单机上的运行速度比现有流行解决方案快十倍以上,并在分布式或内存受限的环境中扩展到数十亿个示例。
— XGBoost: A Scalable Tree Boosting System, 2016。
XGBoost是一种有效的机器学习模型,即使在类别分布偏斜的数据集上也是如此。
在对用于不平衡分类的XGBoost算法进行任何修改或调整之前,测试默认的XGBoost模型并建立性能基线非常重要。
尽管XGBoost库有其自己的Python API,但我们可以通过XGBClassifier包装器类将XGBoost模型与scikit-learn API一起使用。可以实例化模型实例并像任何其他scikit-learn类一样用于模型评估。例如:
|
1 2 3 |
... # 定义模型 model = XGBClassifier() |
我们将使用重复交叉验证来评估模型,其中包含三次10折交叉验证的重复。
模型性能将使用在重复和所有折叠中平均的ROC曲线下面积(ROC AUC)报告。
|
1 2 3 4 5 6 7 |
... # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.5f' % mean(scores)) |
将这些结合起来,下面列出了在不平衡分类问题上定义和评估默认XGBoost模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 在不平衡分类数据集上拟合xgboost from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from xgboost import XGBClassifier # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=7) # 定义模型 model = XGBClassifier() # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.5f' % mean(scores)) |
运行示例会评估不平衡数据集上的默认XGBoost模型,并报告平均ROC AUC。
注意:您的结果可能会有所不同,具体取决于算法或评估过程的随机性,或数值精度的差异。考虑运行示例几次并比较平均结果。
我们可以看到该模型具有技能,ROC AUC高于0.5,在这种情况下达到0.95724的平均分数。
|
1 |
平均ROC AUC: 0.95724 |
这为对默认XGBoost算法执行的任何超参数调整提供了比较基线。
用于类别不平衡的加权XGBoost
尽管XGBoost算法在各种具有挑战性的问题上表现良好,但它提供了大量的超参数,其中许多需要调整才能在给定数据集上充分发挥算法的潜力。
该实现提供了一个超参数,旨在调整算法对不平衡分类问题的行为;这就是scale_pos_weight超参数。
默认情况下,scale_pos_weight超参数设置为1.0,其作用是在提升决策树时,相对于负样本,对正样本的平衡进行加权。对于不平衡的二元分类数据集,负类别指的是多数类别(类别0),正类别指的是少数类别(类别1)。
XGBoost 经过训练以最小化损失函数,而梯度提升中的“梯度”指的是该损失函数的陡峭程度,即错误量。小梯度意味着小错误,反过来,对模型的修正也小。训练期间的大错误梯度反过来会导致大修正。
- 小梯度:模型的小错误或小修正。
- 大梯度:模型的大错误或大修正。
梯度被用作拟合后续树的基础,这些树被添加以提升或纠正现有决策树集成所犯的错误。
scale_pos_weight值用于缩放正类别的梯度。
这会缩放模型在训练正类别时所犯的错误,并鼓励模型过度纠正这些错误。反过来,这可以帮助模型在对正类别进行预测时获得更好的性能。如果过度推动,可能会导致模型过度拟合正类别,从而损害负类别或两个类别的性能。
因此,scale_pos_weight可以用于训练用于不平衡分类的类别加权或成本敏感型XGBoost。
为scale_pos_weight超参数设置一个合理的默认值是类别分布的倒数。例如,对于少数类别与多数类别比例为1比100的数据集,scale_pos_weight可以设置为100。这将使模型在少数类别(正类别)上犯的分类错误具有100倍的影响,反过来,比在多数类别上犯的错误多100倍的修正。
例如:
|
1 2 3 |
... # 定义模型 model = XGBClassifier(scale_pos_weight=100) |
XGBoost文档建议了一种快速估算此值的方法,即使用训练数据集中的多数类别总数除以少数类别总数。
- scale_pos_weight = total_negative_examples / total_positive_examples
例如,我们可以为我们的合成分类数据集计算这个值。我们预计它大约是100,或者更精确地说是99,因为我们定义数据集时使用的权重。
|
1 2 3 4 5 6 |
... # 计算每个类别的样本数 counter = Counter(y) # 估算 scale_pos_weight 值 estimate = counter[0] / counter[1] print('Estimate: %.3f' % estimate) |
下面列出了估算XGBoost超参数scale_pos_weight值的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 估算 xgboost 超参数 scale_pos_weight 的值 from sklearn.datasets import make_classification from collections import Counter # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=7) # 计算每个类别的样本数 counter = Counter(y) # 估算 scale_pos_weight 值 estimate = counter[0] / counter[1] print('Estimate: %.3f' % estimate) |
运行示例创建数据集并估算scale_pos_weight超参数的值为99,正如我们所预期的。
|
1 |
估算值:99.000 |
我们将直接在XGBoost模型的配置中使用此值,并使用重复的k折交叉验证评估其在数据集上的性能。
我们期望ROC AUC会有所改善,尽管这不能保证,具体取决于数据集的难度和XGBoost模型的选择配置。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 在不平衡分类数据集上拟合平衡XGBoost from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from xgboost import XGBClassifier # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=7) # 定义模型 model = XGBClassifier(scale_pos_weight=99) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('Mean ROC AUC: %.5f' % mean(scores)) |
运行示例会准备合成的不平衡分类数据集,然后使用重复交叉验证评估XGBoost训练算法的类别加权版本。
注意:您的结果可能会有所不同,具体取决于算法或评估过程的随机性,或数值精度的差异。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到性能有适度提升,ROC AUC从上一节中scale_pos_weight=1时的约0.95724提高到scale_pos_weight=99时的0.95990。
|
1 |
平均ROC AUC: 0.95990 |
调整类别加权超参数
设置scale_pos_weight的启发式方法在许多情况下都是有效的。
然而,通过不同的类别加权可能可以获得更好的性能,这也将取决于用于评估模型的性能指标的选择。
在本节中,我们将对类别加权XGBoost的一系列不同类别加权进行网格搜索,并发现哪个能产生最佳的ROC AUC分数。
我们将尝试以下正类别加权:
- 1 (默认)
- 10
- 25
- 50
- 75
- 99 (推荐)
- 100
- 1000
这些可以定义为GridSearchCV类的网格搜索参数,如下所示:
|
1 2 3 4 |
... # 定义网格 weights = [1, 10, 25, 50, 75, 99, 100, 1000] param_grid = dict(scale_pos_weight=weights) |
我们可以使用重复交叉验证对这些参数执行网格搜索,并使用 ROC AUC 评估模型性能。
|
1 2 3 4 5 |
... # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格搜索 grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, cv=cv, scoring='roc_auc') |
执行后,我们可以总结最佳配置以及所有结果,如下所示:
|
1 2 3 4 5 6 7 8 9 |
... # 报告最佳配置 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # 报告所有配置 means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) |
综合来看,下面的示例在不平衡数据集上对XGBoost算法的八种不同正类别权重进行网格搜索。
我们可能会期望启发式类别加权是表现最好的配置。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 使用xgboost对不平衡分类进行网格搜索正类别权重 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import GridSearchCV from sklearn.model_selection import RepeatedStratifiedKFold from xgboost import XGBClassifier # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=7) # 定义模型 model = XGBClassifier() # 定义网格 weights = [1, 10, 25, 50, 75, 99, 100, 1000] param_grid = dict(scale_pos_weight=weights) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格搜索 grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, cv=cv, scoring='roc_auc') # 执行网格搜索 grid_result = grid.fit(X, y) # 报告最佳配置 print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # 报告所有配置 means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) |
运行示例会使用重复k折交叉验证评估每个正类别权重,并报告最佳配置和相关的平均ROC AUC分数。
注意:您的结果可能会有所不同,具体取决于算法或评估过程的随机性,或数值精度的差异。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到scale_pos_weight=99的正类别权重获得了最佳的平均ROC分数。这与通用启发式的配置相匹配。
有趣的是,几乎所有大于默认值1的值都具有更好的平均ROC AUC,甚至激进的1000值也是如此。同样有趣的是,值99比值100表现更好,如果我没有按照XGBoost文档中建议的那样计算启发式,我可能会使用100。
|
1 2 3 4 5 6 7 8 9 |
最佳:0.959901,使用 {'scale_pos_weight': 99} 0.957239 (0.031619) 与: {'scale_pos_weight': 1} 0.958219 (0.027315) 与: {'scale_pos_weight': 10} 0.958278 (0.027438) 与: {'scale_pos_weight': 25} 0.959199 (0.026171) 与: {'scale_pos_weight': 50} 0.959204 (0.025842) 与: {'scale_pos_weight': 75} 0.959901 (0.025499) 与: {'scale_pos_weight': 99} 0.959141 (0.025409) 与: {'scale_pos_weight': 100} 0.958761 (0.024757) 与: {'scale_pos_weight': 1000} |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- XGBoost:一个可扩展的树形增强系统, 2016.
书籍
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
API
- sklearn.datasets.make_classification API.
- xgboost.XGBClassifier API.
- XGBoost参数,API文档.
- 参数调整注意事项,API文档.
总结
在本教程中,您学习了用于不平衡分类的加权XGBoost。
具体来说,你学到了:
- 从高层次上理解梯度提升的工作原理,以及如何开发用于分类的XGBoost模型。
- 如何修改XGBoost训练算法,使其在训练期间根据正类别的重要性按比例加权错误梯度。
- 如何为XGBoost训练算法配置正类别权重,以及如何网格搜索不同的配置。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






网格搜索不应该使用一个保留的验证集吗?否则,您似乎在过度拟合您的超参数到您的数据。
网格搜索使用交叉验证来估计每个配置的性能。
理想情况下,我们应该使用不同的保留数据集进行调整。我通常不会为了保持示例的简单性而这样做。
https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
为什么在不平衡的情况下使用AuC ROC?tpr会很高吗?为什么不使用精确度、召回率、f1?
ROC 仍然会报告相对提升。是的,那些其他指标也很棒。
根据项目目标选择指标,请参阅此框架
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
嗨,Jason,
处理不平衡数据集时,使用其他性能指标,如精确度、召回率或F1,而不是ROC-AUC,会不会更好?
因为99%的案例属于类别0,并且其中大多数被正确分类,但少数类别(1)可能不正确。
谢谢,
这篇文章的重点是成本敏感型xgboost。
有关选择适当指标的更多信息,请参阅此内容
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
你能说一下如何在R中使用F1指标而不是auc吗?比如在xgboost函数中有一个选项可以指定eval_metric;你能说一下在eval_metric下哪个参数适合F1分数吗?
你好 Saikat…以下资源可能对您有用
https://stats.stackexchange.com/questions/138690/calculate-the-f1-score-of-precision-and-recall-in-r
你好 Jason,
我有一个关于GridSearchCV的问题。
GridSearchCV和RandomizedSearchCV有什么区别?
你有两者的例子吗?
谢谢
搜索指定配置网格与搜索随机配置组合的区别。
嘿,感谢这篇精彩的文章。
我们如何为多类别问题设置“scale_pos_weight”?
非常感谢
我不认为你可以。我想它只适用于二元分类。
感谢这篇精彩的教程!
我想知道如何处理多类别分类
虽然示例中的Counter可用于二元分类,但如何计算/估算我的数据集的scale_pos_weight?
不客气。
我不认为xgboost用于不平衡分类的方法支持多类别。
我为每个数据实例应用权重
# 由于XGBoost中没有class_weight选项
# 使用sample_weight通过为每个数据实例应用类权重来平衡多类大小
# 计算类权重
from sklearn.utils import class_weight
k_train = class_weight.compute_class_weight(‘balanced’, np.unique(y_train), y_train)
wt = dict(zip(np.unique(y_train), k_train))
# 将类权重映射到相应的目标类值,确保类标签的范围为(0, n_classes-1)
w_array = y_train.map(wt)
set(zip(y_train,w_array))
# 将wt系列转换为wt数组
w_array = w_array.values
# 将wt数组应用于.fit()
model.fit(X_train, y_train, eval_metric=’auc’, sample_weight=w_array)
尊敬的先生,
我想知道如何使用我的数据集代替
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=7)
将您的数据加载为numpy数组
https://machinelearning.org.cn/load-machine-learning-data-python/
哈喽 杰森,
感谢您的精彩文章。
我的数据集形状为 – 5621*8(二元分类)
– 标签/目标:成功 (4324, 77 %) 和不成功 (1297, 23 %)
我将数据分成3份(训练集、验证集、测试集)
– 对于训练集和验证集,我执行10折交叉验证。
– 测试集是独立的数据,我对其进行每个折叠的评估。
我将scale_pos_weight调整到5到80之间,最终我将值固定为75,因为我在测试集上获得了平均更高的准确率(79%)用于这10个折叠
但是,如果我检查我的平均auc_roc指标,它非常差,即所有10个折叠只有50%。
如果我没有调整scale_pos_weight,我的平均准确率会下降到50%,而我的平均auc_roc会增加到70%。
我该如何解释以上结果?
我的问题出在哪里?
等待您的回复-
也许该模型不适用于您的数据集和所选指标,也许可以尝试其他方法?
嗨,Jason,
所有这些文章和教程,以及每个存档(例如这里的不平衡数据存档),都包含在您的每本相关书籍中吗?例如,所有不平衡数据存档都包含在您的不平衡数据书中。
有些是书的早期章节版本,有些则不是。
你可以在这里查看本书的完整目录
https://machinelearning.org.cn/imbalanced-classification-with-python/
如果我只参考你的书而不看博客,我会错过什么吗?或者如果博客是书的子集?
最好的教程都在书里。我花了很长时间精心设计、编辑和测试我的编辑团队的书籍教程。
在某些情况下,博客可能是一个有用的补充。
我问这个的原因是我昨天才偶然发现你的网页,对我来说有点不知所措。所以,我疑惑上面的问题,以确保我只能依赖你提供的一个信息来源,即书。
我的上一个问题在哪里???所以,最初的问题是,你在这里发布的博客是你的书的子集吗?如果我只参考你的书而不看这里的博客,我会错过什么吗?
评论必须经过我的审核和批准,有时需要一段时间,因为我是批量处理的
https://machinelearning.org.cn/faq/single-faq/where-is-my-blog-comment
这些书是我知识/思想的最佳来源。
这可能是一个更容易的开始
https://machinelearning.org.cn/start-here/
如何为多类别问题使用
scale_pos_weight?我不认为它支持多类别问题。
你好!如果我在训练集上进行网格搜索,我应该在训练集(y_train)还是所有y上找到scale_pos_weight值的估计值?我是指这个:
# 计算每个类别的样本数
counter = Counter(y)
# 估算 scale_pos_weight 值
estimate = counter[0] / counter[1]
print(‘Estimate: %.3f’ % estimate)
是的,但这可能是数据泄露的情况。
理想情况下,我们应该仅根据训练集设置权重。
感谢这篇精彩的文章。我使用这种加权方法来训练我的模型。
虽然我因此获得了更好的结果,但我注意到预测概率发生了很大的偏移。
1. 您能帮我理解为什么预测概率会发生偏移吗?
2. 有没有什么方法可以在不使用这些加权方法的情况下计算预测概率?
也许模型需要针对您的问题进行进一步调整?
也许您可以尝试校准模型预测的概率?
您可以通过调用以下函数预测概率
你好,
感谢您的迅速回复。
我进行了调优,模型看起来不错。我像您提到的那样使用了predict_proba。
当我查看有权重模型和无权重模型的预测概率时,我发现前者(有权重模型)的值更高。
我尝试寻找解释,但只找到一些帖子说预测概率值确实会增加,我们需要重新校准它们。但我没有找到任何有用的文章能解释为什么预测概率会发生偏移。
我希望您能帮助我理解这种偏移。
谢谢
“为什么”重要吗?
我们追求一个有技巧的模型,即使模型不透明(许多模型都是),熟练的预测比模型解释更重要
https://machinelearning.org.cn/faq/single-faq/how-do-i-interpret-the-predictions-from-my-model
你好,
我们通常会使用分位数图来比较预测与实际情况,分位数图使用预测概率。我的团队问我为什么预测概率很高,我无法给出很好的解释。我找到了几篇您使用这些加权模型的文章,我尝试了所有这些模型,几乎所有模型都给出了很高的预测概率。这就是为什么我希望您能给出解释。
尽管模型很熟练,但我还是想更深入地了解这些偏移发生的原因。
通常,据我所知,XGBoost 模型会生成未校准的概率。预测的置信度可能是任意的。
我强烈建议在解释概率之前对其进行校准。
您能多解释一下吗?
谢谢你
没问题,哪一部分让你感到困惑?
就XGBoost产生未校准的概率以及如何校准它们而言?这是我第一次听说,所以我对校准概率不太了解。
谢谢你
本教程将向您展示如何操作
https://machinelearning.org.cn/calibrated-classification-model-in-scikit-learn/
嗨
我发现了你的另一篇文章,是关于校准概率的,
https://machinelearning.org.cn/calibrated-classification-model-in-scikit-learn/
我发现这篇文章对于理解概念非常有帮助,使用它之后我获得了更好的预测概率。
我只有一个基本问题,那就是什么时候需要校准概率?是基于模型类型(如增强模型与其他模型)还是基于其他因素?
我真的要感谢您这些精彩的文章以及您花费时间和精力回答每一个问题。
一般来说,试一试就知道了。
具体来说,任何不能原生预测概率的算法都应该进行校准。例如,任何决策树或决策树集成算法。
你好,
我正在使用此模型处理不平衡数据集,但我希望生成准确度、精确度、召回率和f1分数,以及特征重要性。请问您能提供与当前数据不平衡代码结合使用的代码吗?
谢谢你
我建议选择一个指标进行优化,而准确度通常是不平衡数据的糟糕指标。
这将帮助你选择一个指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
所以,在这种情况下,使用类别权重将AUC从0.9572提高到0.9599。这还不到三分之一的百分点。
首先,AUC的这种程度的增加对分类器来说并不是实质性的改进。对我来说,我会将其描述为性能没有变化。
其次,正如您所说,这是一种随机算法。我敢打赌,由于算法的随机性质导致的AUC变化将大于0.00278的增加。
也许我错过了什么?
同意。
也许这个场景不是展示这种方法的好例子。然而,这种方法被清晰地呈现出来,因此您可以复制粘贴并在您的项目中使用它(这是本文的目标)。
好的,酷。确认我理解正确总是好的!你遇到过使用类权重可以改进模型的问题吗?(我想“改进”是相对的,但你觉得呢?)
是的,我在博客上有一些案例研究,其中使用类别权重/模型的成本敏感版本会带来更好的性能。
例如,随机森林的成本敏感版本在这里取得了最佳结果
https://machinelearning.org.cn/imbalanced-multiclass-classification-with-the-glass-identification-dataset/
啊,好的,谢谢。
对于不平衡数据集,AUC-PR或平均精确度可能是更好的指标选择,您可能会看到比AUC更有趣的得分提升,而AUC已经接近100%。
同意!请看这个
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
据我理解。结果是训练模型的准确性,预测新数据不是代码的一部分。如何提高模型的性能以在测试集上获得准确的预测?
为了提高测试集的性能,您可以使用交叉验证技术来校准您的模型。
我安装的是xgboost版本1.5.0,但结果不同。最佳分数是当scale_pos_weight为1时。您安装的是哪个xgboost版本?
我不确定问题出在哪里
最佳:0.960522,使用 {'scale_pos_weight': 1}
0.960522 (0.024031) 与: {'scale_pos_weight': 1}
0.956106 (0.029382) 与: {'scale_pos_weight': 10}
0.955189 (0.029265) 与: {'scale_pos_weight': 25}
0.952980 (0.028971) 与: {'scale_pos_weight': 50}
0.951190 (0.031723) 与: {'scale_pos_weight': 75}
0.954692 (0.027654) 与: {'scale_pos_weight': 99}
0.953470 (0.028217) 与: {'scale_pos_weight': 100}
0.947552 (0.029872) 与: {'scale_pos_weight': 1000}
我可以确认你的结果是正确的。请注意,XGBoost在行为上有所改变(例如,默认使用logloss而不是error),但生成数据的scikit-learn也依赖于随机数生成器。因此,你不应该期望看到完全相同的结果。
嗨,Jason,
您的八个ROC AUC值(针对不同的scale_pos_weight)中的每一个都完全在其平均标准误差(括号中的标准偏差/sqrt(10))范围内,而它们的总平均值为0.959。
因此,您的结论应该是,改变scale_pos_weight的影响在统计上不显著(完全符合由于交叉验证中固有的随机抽样,或者就此而言,从底层总体中抽取整个数据集所导致的随机波动)。
事实上,您的结果仅仅证实了以下事实:当性能标准是ROC AUC时,类别加权(或简单的过采样或欠采样)对分类器性能没有任何系统性影响,因为ROC及其AUC本质上与类别分布或不平衡无关。