XGBoost是梯度提升在分类和回归问题上的高效实现。
它既快速又高效,在各种预测建模任务中表现出色,如果不是最好的话,并且是诸如Kaggle之类的数据科学竞赛获胜者的最爱。
XGBoost也可以用于时间序列预测,尽管它要求时间序列数据集首先被转换为监督学习问题。它还需要使用一种称为前向验证的专门技术来评估模型,因为使用k折交叉验证评估模型会导致乐观的偏差结果。
在本教程中,您将了解如何为时间序列预测开发XGBoost模型。
完成本教程后,您将了解:
- XGBoost是用于分类和回归的梯度提升集成算法的实现。
- 时间序列数据集可以使用滑动窗口表示转换为监督学习。
- 如何为时间序列预测拟合、评估和生成XGBoost模型。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 更新于2020年8月:修正了MAE计算中的错误,更新了模型配置以获得更好的预测(感谢Kaustav!)

如何使用 XGBoost 进行时间序列预测
照片由gothopotam拍摄,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- XGBoost集成
- 时间序列数据准备
- XGBoost用于时间序列预测
XGBoost集成
XGBoost是Extreme Gradient Boosting的缩写,是随机梯度提升机器学习算法的高效实现。
随机梯度提升算法,也称为梯度提升机或树提升,是一种强大的机器学习技术,在各种具有挑战性的机器学习问题上表现良好甚至最佳。
树模型提升已被证明在许多标准的分类基准测试中能取得最先进的结果。
— XGBoost: A Scalable Tree Boosting System, 2016。
它是一个决策树集成算法,新树可以纠正模型中已有的树的错误。会一直添加树,直到模型无法进一步改进为止。
XGBoost提供了随机梯度提升算法的高度优化实现,并提供了一套模型超参数,用于控制模型训练过程。
XGBoost成功的最重要的因素是其在所有场景下的可扩展性。该系统在单台机器上的运行速度比现有流行解决方案快十倍以上,并且在分布式或内存受限的环境中可以扩展到数十亿个示例。
— XGBoost: A Scalable Tree Boosting System, 2016。
XGBoost是为表格数据集上的分类和回归设计的,尽管它也可以用于时间序列预测。
有关梯度提升和XGBoost实现的更多信息,请参阅教程
首先,必须安装XGBoost库。
您可以使用pip安装它,如下所示
|
1 |
sudo pip install xgboost |
安装完成后,您可以通过运行以下代码来确认它已成功安装并正在使用最新版本
|
1 2 3 |
# xgboost import xgboost print("xgboost", xgboost.__version__) |
运行代码,您应该看到以下版本号或更高版本。
|
1 |
xgboost 1.0.1 |
尽管XGBoost库有自己的Python API,但我们可以通过XGBRegressor包装器类将XGBoost模型与scikit-learn API一起使用。
可以像任何其他scikit-learn类一样实例化模型实例并用于模型评估。例如
|
1 2 3 |
... # 定义模型 model = XGBRegressor() |
现在我们熟悉了XGBoost,让我们来看看如何准备时间序列数据集以进行监督学习。
时间序列数据准备
时间序列数据可以被表述为监督学习。
给定一个时间序列数据集的数字序列,我们可以重新构造数据,使其看起来像一个监督学习问题。我们可以通过使用先前的时间步作为输入变量,并将下一个时间步作为输出变量来实现这一点。
让我们用一个例子来具体说明这一点。假设我们有一个时间序列如下:
|
1 2 3 4 5 6 |
时间,测量值 1, 100 2, 110 3, 108 4, 115 5, 120 |
我们可以通过使用前一个时间步的值来预测下一个时间步的值来重构这个时间序列数据集为一个监督学习问题。
以这种方式重组时间序列数据集,数据将如下所示
|
1 2 3 4 5 6 7 |
X, y ?, 100 100, 110 110, 108 108, 115 115, 120 120, ? |
请注意,时间列被删除,并且某些数据行(如第一行和最后一行)无法用于训练模型。
这种表示称为滑动窗口,因为输入和预期输出的窗口会随时间向前滑动,为监督学习模型创建新的“样本”。
有关使用滑动窗口方法准备时间序列预测数据的更多信息,请参阅教程
我们可以使用Pandas中的shift()函数,根据所需的输入和输出序列长度,自动创建时间序列问题的新框架。
这将是一个有用的工具,因为它允许我们使用机器学习算法探索时间序列问题的不同框架,以查看哪个可能导致性能更好的模型。
下面的函数将把一个NumPy数组形式的时间序列(包含一列或多列)转换为一个指定输入和输出数量的监督学习问题。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 将时间序列数据集转换为监督学习数据集 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg.values |
我们可以使用此函数为XGBoost准备时间序列数据集。
有关此函数分步开发的更多信息,请参阅教程
一旦数据集准备就绪,我们必须小心如何使用它来拟合和评估模型。
例如,在未来数据上拟合模型并让它预测过去是无效的。模型必须在过去训练,并预测未来。
这意味着不能使用在评估期间随机化数据集的方法,如k折交叉验证。相反,我们必须使用一种称为前向验证的技术。
在前向验证中,数据集首先通过选择一个分割点来分割成训练集和测试集,例如,所有数据(除了最后12天)用于训练,最后12天用于测试。
如果我们对进行一步预测感兴趣,例如一个月,那么我们可以通过在训练数据集上训练模型,然后预测测试数据集中的第一个步骤来评估模型。然后,我们可以将测试集中的实际观测值添加到训练数据集中,重新拟合模型,然后让模型预测测试数据集中的第二个步骤。
对整个测试数据集重复此过程将为整个测试数据集提供一步预测,从中可以计算出误差度量来评估模型的技能。
有关前向验证的更多信息,请参阅教程
下面的函数执行前向验证。
它接收时间序列数据集的整个监督学习版本和要用作测试集的行数作为参数。
然后,它遍历测试集,调用xgboost_forecast()函数进行一步预测。计算误差度量,并将详细信息返回以供分析。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 将测试行分割成输入和输出列 testX, testy = test[i, :-1], test[i, -1] # 在历史数据上拟合模型并进行预测 yhat = xgboost_forecast(history, testX) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 总结进度 print('>expected=%.1f, predicted=%.1f' % (testy, yhat)) # 估计预测误差 error = mean_absolute_error(test[:, -1], predictions) return error, test[:, 1], predictions |
调用train_test_split()函数将数据集分割成训练集和测试集。
我们可以在下面定义这个函数。
|
1 2 3 |
# 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test, :], data[-n_test:, :] |
我们可以使用XGBRegressor类来生成一步预测。
下面xgboost_forecast()函数实现了这一点,它接收训练数据集和测试输入行作为输入,拟合模型,并生成一步预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 拟合一个xgboost模型并进行一步预测 def xgboost_forecast(train, testX): # 将列表转换为数组 train = asarray(train) # 分割成输入和输出列 trainX, trainy = train[:, :-1], train[:, -1] # 拟合模型 model = XGBRegressor(objective='reg:squarederror', n_estimators=1000) model.fit(trainX, trainy) # 进行一步预测 yhat = model.predict([testX]) return yhat[0] |
现在我们知道如何准备时间序列数据进行预测以及如何评估XGBoost模型,接下来我们将研究如何在实际数据集上使用XGBoost。
XGBoost用于时间序列预测
在本节中,我们将探讨如何使用XGBoost进行时间序列预测。
我们将使用一个标准的单变量时间序列数据集,目的是使用该模型进行一步预测。
您可以使用本节中的代码作为您自己项目的起点,并轻松地将其改编为多变量输入、多变量预测和多步预测。
我们将使用每日女性生育数据集,即三年来的月度生育数量。
您可以从这里下载数据集,将其放在当前工作目录中,文件名设置为“daily-total-female-births.csv”。
数据集的前几行如下所示
|
1 2 3 4 5 6 7 |
"日期","出生人数" "1959-01-01",35 "1959-01-02",32 "1959-01-03",30 "1959-01-04",31 "1959-01-05",44 ... |
首先,让我们加载并绘制数据集。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 |
# 加载并绘制时间序列数据集 from pandas import read_csv from matplotlib import pyplot # 加载数据集 series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # 绘制数据集 pyplot.plot(values) pyplot.show() |
运行示例将创建数据集的折线图。
我们看不到明显的趋势或季节性。
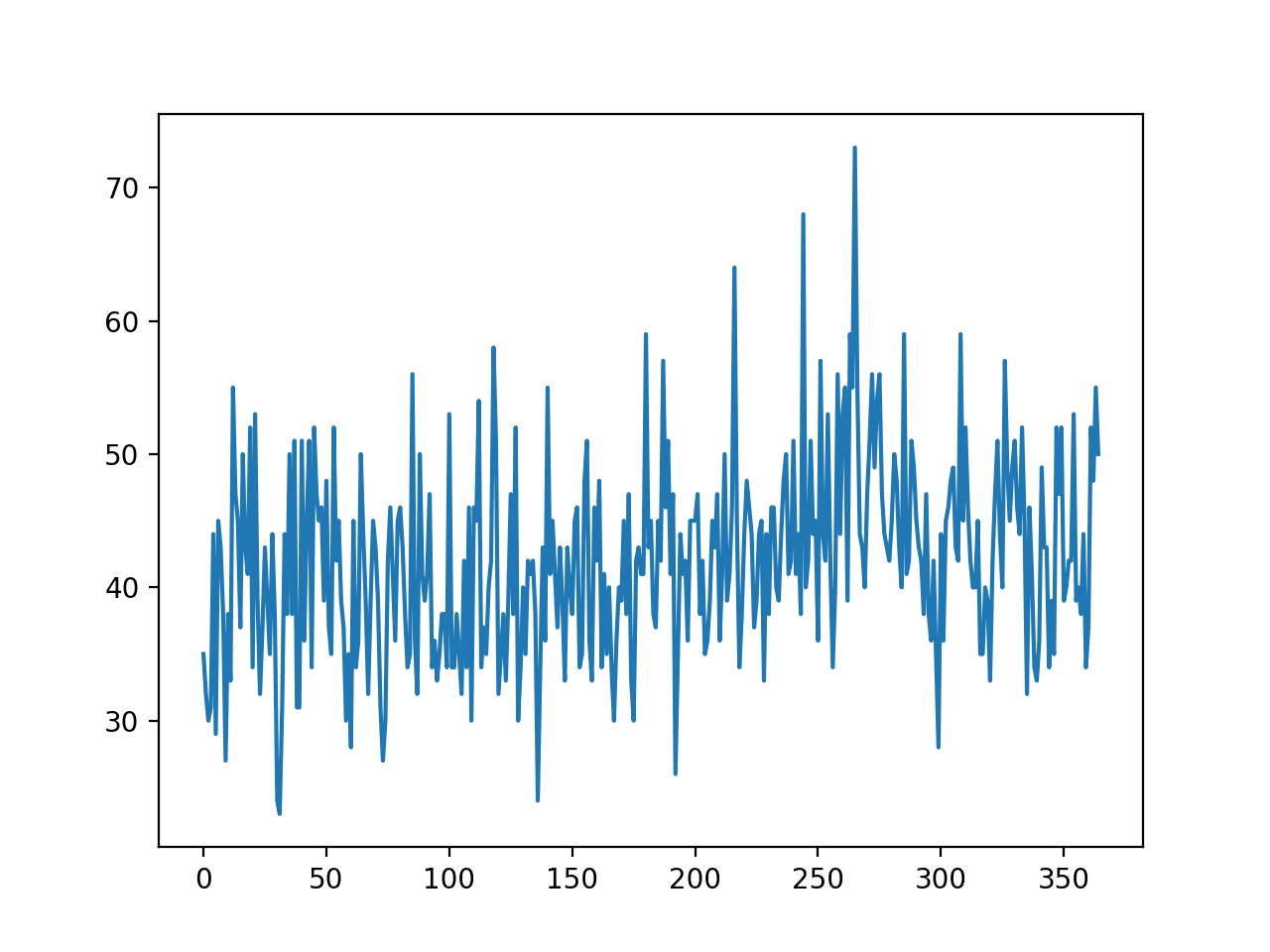
月度生育时间序列数据集的折线图
朴素模型在预测过去12天时的MAE约为6.7次生育。这提供了一个性能基准,高于此的模型可以被认为是有技能的。
接下来,我们将评估XGBoost模型在预测过去12天数据时的一步预测。
我们将只使用前6个时间步作为模型的输入,并使用默认的模型超参数,除了我们将损失函数改为“reg:squarederror”(以避免警告消息),并使用1000棵树进行集成(以避免欠学习)。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
# 使用xgboost预测月度生育数 from numpy import asarray from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from sklearn.metrics import mean_absolute_error from xgboost import XGBRegressor from matplotlib import pyplot # 将时间序列数据集转换为监督学习数据集 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg.values # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test, :], data[-n_test:, :] # 拟合一个xgboost模型并进行一步预测 def xgboost_forecast(train, testX): # 将列表转换为数组 train = asarray(train) # 分割成输入和输出列 trainX, trainy = train[:, :-1], train[:, -1] # 拟合模型 model = XGBRegressor(objective='reg:squarederror', n_estimators=1000) model.fit(trainX, trainy) # 进行一步预测 yhat = model.predict(asarray([testX])) return yhat[0] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 将测试行分割成输入和输出列 testX, testy = test[i, :-1], test[i, -1] # 在历史数据上拟合模型并进行预测 yhat = xgboost_forecast(history, testX) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 总结进度 print('>expected=%.1f, predicted=%.1f' % (testy, yhat)) # 估计预测误差 error = mean_absolute_error(test[:, -1], predictions) return error, test[:, -1], predictions # 加载数据集 series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # 将时间序列数据转换为监督学习 data = series_to_supervised(values, n_in=6) # 评估 mae, y, yhat = walk_forward_validation(data, 12) print('MAE: %.3f' % mae) # 绘制预期值与预测值 pyplot.plot(y, label='预期值') pyplot.plot(yhat, label='预测值') pyplot.legend() pyplot.show() |
运行示例将报告测试集每个步骤的预期值和预测值,然后是所有预测值的MAE。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
我们可以看到,该模型比朴素模型表现更好,MAE约为5.9次生育,而朴素模型为6.7次生育。
你能做得更好吗?
您可以尝试不同的XGBoost超参数和输入时间步长,看看是否能获得更好的性能。请在下面的评论中分享您的结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
>预期=42.0, 预测=44.5 >预期=53.0, 预测=42.5 >预期=39.0, 预测=40.3 >预期=40.0, 预测=32.5 >预期=38.0, 预测=41.1 >预期=44.0, 预测=45.3 >预期=34.0, 预测=40.2 >预期=37.0, 预测=35.0 >预期=52.0, 预测=32.5 >预期=48.0, 预测=41.4 >预期=55.0, 预测=46.6 >预期=50.0, 预测=47.2 MAE: 5.957 |
将创建折线图,比较数据集中最后12天数据的预期值和预测值。
这提供了模型在测试集上表现如何的几何解释。
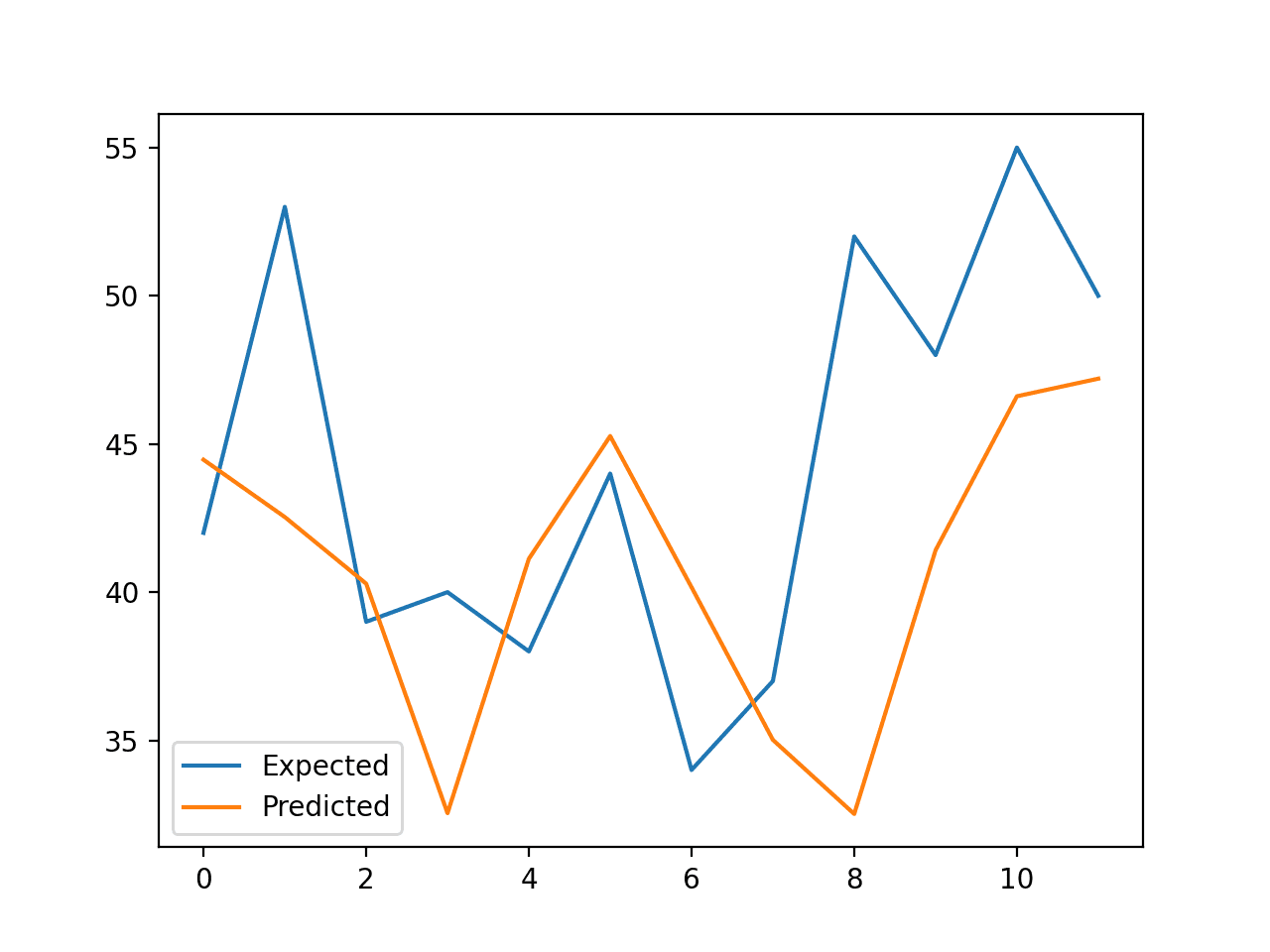
使用XGBoost预测的生育预期值与实际值折线图
一旦选择了最终的XGBoost模型配置,就可以最终确定模型并用于对新数据进行预测。
这称为**样本外预测**,例如,预测训练数据集之外的数据。这与在模型评估期间进行预测相同:因为当模型用于对新数据进行预测时,我们总是希望使用相同的过程来评估模型。
下面的示例演示了在所有可用数据上拟合最终的XGBoost模型,并进行训练数据集结束之后的一步预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 使用xgboost最终确定模型并进行月度生育数预测 from numpy import asarray from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from xgboost import XGBRegressor # 将时间序列数据集转换为监督学习数据集 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg.values # 加载数据集 series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # 将时间序列数据转换为监督学习 train = series_to_supervised(values, n_in=6) # 分割成输入和输出列 trainX, trainy = train[:, :-1], train[:, -1] # 拟合模型 model = XGBRegressor(objective='reg:squarederror', n_estimators=1000) model.fit(trainX, trainy) # 构建新预测的输入 row = values[-6:].flatten() # 进行一步预测 yhat = model.predict(asarray([row])) print('输入: %s, 预测: %.3f' % (row, yhat[0])) |
运行示例将在所有可用数据上拟合XGBoost模型。
使用过去6天已知数据准备一个新的输入行,并预测数据集结束之后的下一个月。
|
1 |
输入: [34 37 52 48 55 50], 预测: 42.708 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
相关教程
总结
在本教程中,您学习了如何开发XGBoost模型进行时间序列预测。
具体来说,你学到了:
- XGBoost是用于分类和回归的梯度提升集成算法的实现。
- 时间序列数据集可以使用滑动窗口表示转换为监督学习。
- 如何为时间序列预测拟合、评估和生成XGBoost模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。






结果看起来并不令人信服
说得有理。
请将模型视为一个您可以在自己的项目上应用的模板。
解释得非常好,很清晰
继续加油
谢谢!
我可以使用 xgboost 进行多变量时间序列数据吗?
当然可以。
本文没有充分论证将 XGBoost 用于时间序列或时间相关数据。
在没有任何基于时间的加权的情况下,该算法无法知道如何整合时间——它只查看孤立的点,例如 A 产生 400,B 产生 510,而 A 和 B 之间没有时间顺序关系。您显示的预期与预测图清楚地表明,该模型未能建立时间与预测之间的恰当关系。
我曾尝试在金融预测中使用 XGBoost,并使用了两年的历史数据,结果并不理想。有时,您可以通过集成技术获得更高的准确性,但没有什么能真正超越真正的时序模型。在这种情况下,我会使用 pmdarima 包,其中的 auto.arima 函数非常出色。
我明白您可以将其作为示例模板,但我认为,除非您将其与时序模型进行比较,或者对非时序模型应用某种时间加权,否则它并非真正具有指导意义,这样才能清楚地了解可用的选项。
最坏的情况是,这篇文章具有误导性。最好的情况是,它存在缺陷,需要更多的测试和示例。
我很感激您分享这些内容,因为它提出了一些关于如何更灵活地处理时间序列问题的好问题,我期待一篇关于这个主题的更详尽的文章。
感谢分享,很抱歉它不适用于您的特定数据集。
我不同意它具有误导性。
我同意 Rahul 的观点,即这似乎没有考虑到时间序列模型旨在解决的问题,例如季节性、数据是否平稳等。
当然,只有当您认为它比其他方法有优势时,才在您自己的数据上尝试。
如果你有足够的创造力,可以通过工程设计一些新特征来考虑季节性。
同意!
这是一个将 Xgboost 应用于时间序列数据的框架。就像我们在数据科学中所做的很多事情一样,它是实验性的,它可能适用于您的特定问题,也可能不适用于。
你说它不能整合时间,因为它不能应用加权,但并没有硬性规定必须如此。如果你认为你在数据科学(或任何科学)中犯了一个关键错误,那就是将你的假设强加于应该提供良好结果的事物上,而不是去实验并让结果告诉你什么有效。
没有任何机器学习模型会固有地了解时间,它不是人类,它只知道数据点。我们关心的是我们选择的机器学习算法能否足够准确地将这些输入数据点映射到输出数据点。
我曾将 XGBoost 应用于金融建模问题,通过正确的数据集、正确的功能工程、优化、大量实验,以及最重要的是不让我的假设阻碍了我对什么有效、什么无效的判断,我成功了,但这绝非易事。不要因为你无法做到就否定它。
尊敬的Jason博士,
我有一个关于单变量数据的问题,例如“太阳黑子”数据。没有 X 值或特征。正如你的博客 https://machinelearning.org.cn/time-series-datasets-for-machine-learning/ 中所示,它被称为“单变量”。是的,单变量数据集包含日期信息,如 dd-mm-yyyy 信息,或者可以通过 x = [i for i in range(len(mydataset))] 数组得出。
能否在单变量时间序列上执行模型评估,例如训练-测试分割、模型、RepeatedClassifiedKFold 和 cross_val_score,其中时间是 X 的一个特征,y 是单变量数据序列,例如太阳黑子数据?
谢谢你,
悉尼的Anthony
它是单变量的。日期/时间被丢弃。
交叉验证通常对时间序列数据无效,请参见此链接。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
尊敬的Jason博士,
感谢您引用这个网站:https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/。
尽管没有交叉验证,但仍然执行了训练/测试分割,并且太阳黑子数据被用作“实验”的示例数据集。
谢谢,非常感谢。
悉尼的Anthony
显然,如果您有 1960 年以来的出生率,我们就可以真正测试出模型的优劣。
另外,由于时间被排除在外,您无法处理有时间序列缺失的数据,就像自然现象(如变星研究)中经常发生的那样。
谢谢您的留言。
嗨 Jason!你认为我们可以有这个的多变量变体吗?
好建议!
是的,请做一个多 X - 一 Y 变体!!!
这对代码来说应该是一个微不足道的改变。你试过吗?
使用 XGBoost 时,是否需要去除趋势和季节性?
这取决于。尝试带或不带,然后比较结果。
嗨 Jason,可以将代码修改为在数据集末尾进行多步预测吗?如果可以,有什么建议吗?🙂
例如,我可以比
yhat = model.predict(asarray([row]))走得更远吗?我还在运行自己的数据集,一个月的建筑电力使用量(kW),每 15 分钟一个数据点……我的预期与预测图的结果相当好。我只是好奇能否预测更多数据,而不仅仅是 1 分钟 15 个数据点……谢谢
好问题。
是的,您可以使用以下包装器类之一。
https://machinelearning.org.cn/multi-output-regression-models-with-python/
Jason 感谢您提供额外的信息……对于时间序列应用(如我提到的电力数据集),您会建议采用链式多输出回归策略吗?或者您发送的链接中提到的直接多输出回归?
也许可以都测试一下,找出效果好的。
我不确定这是最好的方法,但我有一个循环,它将预测附加到数据集中,然后重新训练 XGB。
values = df.close.values
preds = []
for i in range(10)
# 将时间序列数据转换为监督学习
train = series_to_supervised(values, n_in=6)
# 分割成输入和输出列
trainX, trainy = train[:, :-1], train[:, -1]
# 拟合模型
model = XGBRegressor(objective=’reg:squarederror’, n_estimators=1000)
model.fit(trainX, trainy)
# 构建新预测的输入
row = values[-6:].flatten()
# 进行一步预测
yhat = model.predict(asarray([row]))
print(‘Input: %s, Predicted: %.3f’ % (row, yhat[0]))
values = np.append(values, yhat)
preds.append(yhat)
preds 数组包含接下来的 10 个预测步骤。
谢谢哥们!你拯救了我的项目。
嗨 Ben,如果你能分享你的代码,那就太好了,我也在尝试将代码应用到电力数据上。
谢谢
Jason,还有一个问题。如果我创建一些图表进行预期与预测分析,我是否可以将此模型保存为 pickle 文件以在预测代码中使用?或者模型在 `# forecast monthly births with xgboost` 和 `# forecast monthly births with xgboost` 脚本之间的参数是否相同?
我相信你可以将 xgboost 模型 pickle 化。也许可以测试一下以确认。
想知道为什么你在 walk_forward_validation() 函数中返回 test[:,1],以及为什么用它来计算误差?难道不应该是 test[:,-1] 吗?我们预测的是最后一列,因此应该与最后一列进行比较。
你说得对,看起来像是一个笔误。
已修复。谢谢!
那么你返回的东西也应该纠正,对吧?
没错!
我不知道我在想什么。需要更多的咖啡……
谢谢你指出这些愚蠢的错误。
嗨 Jason。感谢您的材料。
我认为计算误差时有一个错误。
mean_absolute_error(test[:, -1], predictions)
如果您注意到“test[:, -1]”,您会发现该数组与正确值不匹配。
我说得对吗?
抱歉。我弄混了。没关系!
不客气。
我相信代码是正确的。
模型通常会预测前一个值为下一个值,这称为持续性预测。绘制时,看起来就像预测比观测值滞后一步。
嗨 Jason。感谢您的材料。阅读了您关于 xgboost 的解释后,我想尝试使用这种方法进行时间序列预测。您在文章中提到,此方法可以扩展到多变量输入。我想使用几个参数来预测另一个相关参数的周期性趋势。我应该如何调整现有方法?
不客气。
我认为准备数据的函数是相同的,可以直接使用。试试看。
你好,Jason。
感谢提供有用的教程。我订阅了您的超级捆绑包,它们对我自学非常有帮助。
不知道您是否有使用 XGBoost 进行多变量、多时间步预测的解决方案。我找不到它在我的书中,xgboost_with_python。谢谢!
谢谢!
好问题。我的 xgboost 书中没有时间序列的例子。
您可以直接调整上面的示例以适用于多变量时间序列数据。多步预测可以通过 xgboost 是否直接支持多输出(我认为它支持)来实现,或者如果您使用这里的多输出回归包装器类。
https://machinelearning.org.cn/multi-output-regression-models-with-python/
非常感谢您提供如此宝贵的资源!
为什么您使用 XGBoost 而不是例如随机森林?XGBoost 在这类任务中效果更好吗?如果是,为什么?
没有特别的原因,只是很多人问我如何将 xgboost 用于时间序列。
嗨 Jason,感谢您的教程。我想问的是,在实际情况中,每次我为新数据进行预测时,都需要将其转换为具有所有历史数据的监督学习数据集。是这样吗?依我之见,只有这样才能获得新数据的滞后信息。如果属实,如果有大量历史数据,如何提高性能?每次我进行预测时,我都需要再次移动所有历史数据。特别是如果我有多个变量,那将是耗时的。寻找一个针对这种情况的解决方案。谢谢。
是的。
测试不同的滞后量、不同的数据转换、不同的模型配置,以发现最适合您数据集的方法。
嗨,Jason,
只是为了验证/澄清,当图表生成时,“预期”==“实际”数据,对吗?我们将预测值与实际/预期数据进行比较……
我只是想确认预期是否表示实际真实数据。
这是预期与预测,预期是数据集中的数据。
嗨,Jason,
我可以使用您演示的
walk_forward_validation来预测一个未来值,并结合 MultiOutputRegressor 吗?最终我希望使用类似以下的方法来预测多个未来值:
MultiOutputRegressor(XGBRegressor(objective='reg:squarederror', n_estimators=1000))我是否需要修改我的
walk_forward_validation以反映我的MultiOutputRegressor过程,这是我的最终目标?我的
XGBRegressor(objective='reg:squarederror', n_estimators=1000)与我在walk_forward_validation中使用的相同,并且与 sci kit learn 包装器MultiOutputRegressor一样,它预测 24 个未来值。我想知道这是否重要,或者因为我使用的是MultiOutputRegressor,所以walk_forward_validation会变得没有意义?希望这有意义!非常感谢您的帖子,使用此过程的结果比 ARIMA 或 LSTM 方法好得多……
也许可以。你可能需要尝试一下。
Jason,
将神经网络与
MultiOutputRegressor一起使用有什么不对吗?我一直在尝试 sci kit learn 的
MLPRegressor。model = MLPRegressor(max_iter=2000, shuffle=False)multi_output_regr = MultiOutputRegressor(model)由于我注意到所有用于时间序列预测的神经网络都侧重于模式识别(如 LSTM),因此我想到了这个问题。
我看不出有什么不行。也许可以尝试一下,看看效果如何。
Jason,在具有大量代表星期几和一天中时间的虚拟变量,以及外部空气温度传感器读数(电力消耗数据集)的时间序列数据集上训练 MLP NN(不打乱数据)会不会很奇怪?保存模型为 pickle 文件……
如果我只有一年的数据,我能否以区块链格式(包含计算的虚拟变量)反向转换训练数据集来测试模型?
抱歉,有两个问题!
很难说,也许可以尝试一下。
嗨 Ben,
multioutput regressor 对你用 walk forward validation 奏效了吗?如果奏效了,你能否分享一下你修改后的效果?
谢谢
一如既往的精彩教程。我注意到您没有使用 xgboost 的早停功能——它会将训练性能与测试集进行比较,如果性能趋于平缓,则会停止训练更多的树。
这是因为您无法为每次前向遍历更改 n_estimators 吗?基本上您需要手动设置(或进行 GridSearchCV)以在所有前向遍历步骤中找到最佳的 n_estimators?
谢谢。
对于时间序列数据,早停很难实现,例如,您无法合理地定义验证集。
在前向验证测试框架中搜索不同的树数量可能更简单。
嗨,Jason,
感谢这篇很棒的教程。
它对我很有帮助。
我只是想知道如何使用 XGBoost 来预测未来 30 天的新值?
有许多方法可以使用 xgboost 模型进行多步预测,以下是一些想法。
https://machinelearning.org.cn/multi-step-time-series-forecasting/
嗨,Jason,
我读到 XGB 不能外推趋势,如果观察到趋势,将一个拟合良好的 ARIMA 作为特征是否有帮助?
来源:https://www.kaggle.com/c/web-traffic-time-series-forecasting/discussion/38352
感谢分享。
为您的数据集使用最有效的方法。
为什么??
你说
使用最后一个月的已知数据准备一个新行的输入,并预测数据集末尾之后的下一个月。
输入: [34 37 52 48 55 50], 预测: 42.708
但我看到
使用最后一个日的数据准备输入的新行(模型已用全年的数据进行了训练),并预测下一个日期,超出...。
数据框有 365 行,每行是一天,所以你将 [(34 37 52 48 55,滞后特征),(50=我想预测的值)] 发送给模型,并且只预测到 159-12-31 (50) 的下一天,这是最后 6 天。
360 1959-12-27 37
361 1959-12-28 52
362 1959-12-29 48
363 1959-12-30 55
364 1959-12-31 50
因此,你预测了第二天,即42.708
我错了吗,杰森?
抱歉,不确定我是否理解你的意思。
你可以随心所欲地表述你的预测。
只是澄清一下,这可能会在评论中引起一些困惑:杰森提到了“过去12个月”,但这实际上是数据中的最后12天。截至目前,该数据集包含1959年的365天,而杰森使用的是最后12天,据我所观察,他并没有实际处理月份。
谢谢!已修复。
嘿,杰森,非常感谢您提供的这个非常有用的指南。它在用我自己的数据集预测过去12天时效果很好,但当我尝试预测一个包含780条记录的数据集中的过去195天时,我收到了以下错误消息:“IndexError:数组索引过多:数组是一维的,但被索引了两次。” 我认为这只能工作到99天,对吗?
预测天数没有限制,也许可以检查一下你的数据准备和模型。
感谢回复!我刚接触机器学习,实在搞不清楚如何基于前585个数据点预测最后195个值?我将walk_forward_validation中的n_test更改为195,将series_to_supervised中的n_in更改为585。它似乎运行正常,但不确定它是否真的使用了585个值来预测这些。你能确认一下吗?
也许你可以检查一下准备好的数据,以确认数据准备步骤是否如你所愿。
你好杰森,请问在使用xgboost进行预测时,数据必须是平稳的吗?非平稳时间序列可以起作用吗?
不必,但最好这么做。
你好杰森先生,
希望您一切都好。
我正在进行一个大学项目,我需要根据其他特征(物联网可穿戴设备数据 – FitRec)来查找用户ID(分类用户)。我计划对此数据(我认为是多元时间序列数据)使用XGBClassifier,但我在用Python输入数据方面遇到了挑战——想知道您是否可以建议XGBoost是否适用于此问题?如果适用,如何将数据输入模型?
另外,我们如何将时间序列和非时间序列数据一起添加到模型中以获得输出?
期待您的回复。谢谢,先生
此致
Payal Joshi
我建议测试一系列不同的算法,以发现最适合您特定数据集的方法。
真不敢相信我被如此诱导,认为这会有效。但它没有。
示例运行得非常好。
很遗憾您在运行示例时遇到了问题,也许您可以总结一下您遇到的问题或看到的错误?
或许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我能进行10次样本外预测吗?如果能,如何进行?
调用 model.predict() 并传入任何你想要的输入数据。
为什么当我使用10步预测、进行10次来预测一个100点数据集时,通过将预测值附加到testX中,MAE会变小,而当我预测10个点,将5个实际值附加到train中进行10次时,MAE会变大?这说不通。
我不知道。也许仔细检查一下你的代码和结果。
感谢您提供的精彩教程,杰森!您提到应该使用前向验证技术来尊重数据的时序性质。在提升算法中,每个估计器都在一个自举样本上进行训练。使用块自举采样而不是传统的自举采样来尊重数据的时序性质,这是否合理?
只要模型在过去的数据上拟合,在未来数据上评估,就不会发生数据泄露。
杰森,这个教程非常有启发性,谢谢。我正在想,Python是否有没有像您计算MAE那样用于计算MAPE的包。
看这里
https://scikit-learn.cn/stable/modules/generated/sklearn.metrics.mean_absolute_percentage_error.html
嗨,Jason,
使用XGBoost模型可以预测未来时期吗?如果可以,怎么做?
我们使用测试数据来预测结果,但对于未来时期,我没有任何数据。
当然。调用 model.predict()
你好杰森,感谢您提供的精彩文章,我尝试调用model.predict()进行未来值预测时遇到了错误。
–> 38 yhat11=model.predict()
39
40 print(yhat11)
TypeError: predict() missing 1 required positional argument: ‘X’
模型知道如何根据输入生成输出。但是你必须提供输入。它期望你写 yhat11 = model.predict(X),其中 X 是某个输入。
嗨 Jason
感谢您发布如此有信息量的教程。
我能够正确运行您的代码进行一步预测,但当我尝试多步预测时,在“fit”模型调用期间会生成以下错误:
validate_meta_shape
assert len(data.shape) == 1 or (
AssertionError
我认为您应该一步一步地进行,并将预测值反馈到下一步的输入中。这样会更容易。
谢谢你的回复。
这是一个关于多步预测的出色提示。然而,在我的情况下,如果我更感兴趣的是对一个输入查询预测多个步骤,那将是很好的。
此致
对于决策树来说这相当困难,但您可以尝试设置具有多步输出的训练数据。在这种情况下,您需要更多的数据进行训练,因为您的维度更高。
如何使用xg boost预测未来值,就像我们在arima中预测未来7天或未来一个月一样?如何传递下周的日期并预测值?请提供一些示例。
你好 Manju…以下内容是解决您问题的绝佳起点。
https://towardsdatascience.com/xgboost-for-time-series-youre-gonna-need-a-bigger-boat-9d329efa6814
嗨,Jason,
感谢发帖。
有些人提出了同样的问题,但我想将您的代码扩展到多元序列。
有10个时间序列,想预测所有序列的下一个样本。
在我看来,问题在于 series_to_supervised 函数。我应该如何修改它?
我的第二个想法是:为了方便算法,我想将外源变量插入到数据集中,比如年份、月份,作为特征,这有助于它识别季节性。
对于这样的问题,我称它们为外源变量,因为我不要求XGBoost也预测年份和月份,只是让它们作为附加信息。
那么第二个问题是
在训练中是否可以将“外源”变量指定给xgboost函数参数?
例如 xgboostRegressor(exog=df).fit(x,y),其中 df 是包含年份、月份两个变量的数据框
非常感谢
Luigi
嗨,Jason,
这是对XGBoost和时间序列方法的一个非常精彩的说明。我有一个关于潜在数据泄露“来自未来”的问题,如果将数据框而不是数据序列提供给函数 series_to_supervised()。
我相信在当前的实现中,如果有一个以上特征,当将数据框分割成时间窗口时,包含我们要预测的标签的最后一个时间窗口将与我们用于训练的一些特征共享相同的时间步。所以本质上我们将使用一些具有与我们要预测的标签相同时间步的特征,这使得它不一致。是这样吗,还是我遗漏了什么?我认为如果使用包含多个特征的数据框,应该删除与标签具有相同时间步的特征的时间窗口。
例如,在您展示的示例中,如果我们有两个特征,并保持6个时间窗口,那么不是有6个时间窗口的特征在之前的时间步长加上1个用于未来时间步的标签,那么我们将有6*2个特征在之前的时间步长加上1个用于未来时间步的标签,再加上1个用于未来时间步的额外特征。所以这个额外的未来特征应该被丢弃,否则我们将训练并已经知道一些不可用的数据。
希望我说明白了。再次感谢。
谢谢
你好 Gabriele…请将问题简化为一个,以便我能更好地帮助您。
很棒的教程。按照我的观察,testX, testy = test[i, :-1], test[i, -1] 不应该在for循环之外的前向验证函数中吗?正如我所观察到的,test[i] 被附加到历史记录中,但我没有看到对测试集的任何修改。谢谢!
你好…请说明您引用的代码列表以及是否已执行。也就是说…是哪个代码列表以及遇到了什么问题或错误(如果有的话)?
~我有一个相关的观察…数据集包含365行每日数据,在添加了6天的滞后数据并删除NaN后减少到359行… train_test_split() 将简单地将此数据分割为训练集(前347行 [0:346])和测试集(最后347行 [12:358])… History 被初始化为Train… 在循环内部,我们将从Test中逐行附加到History数据集中 => 这意味着History最初有行0:346,然后在第一次迭代时,原始数据集的第12行将被附加到其中,然后是第13行、第14行,以此类推,直到循环结束… 不确定这实现了什么?除非我遗漏了什么。
前面的评论不用在意了。测试数据集并不是我想象的那样。它只是最后12行。你正在一步一步地对它们进行预测,并在一个不断扩展的数据窗口上重新拟合模型。
嗨,杰森,一如既往的出色文章。
“日期”,”出生人数”
“1959-01-01”,35
“1959-01-02”,32
“1959-01-03”,30
“1959-01-04”,31
“1959-01-05”,44
“日期”,”性别”
“1959-01-01”,M
“1959-01-02”,M
“1959-01-03”,F
“1959-01-04”,F
“1959-01-05”,M
如果我想做时间序列预测,只需将“出生人数”替换为“性别”,其中性别是分类数据。这篇文章还适用吗?或者您有什么其他建议吗?请。
你好 jason,
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True)
n_vars = 1 if type(data) is list else data.shape[1]
n_vars 在代码中没有产生任何影响,也没有被第二次使用。请确认。
我的问题也是一样,其他特征怎么样了?为什么它们定义 n_vars = 1?
你好,我有一个问题,我不明白,请帮我澄清一下。谢谢。
关于模型在函数中的
def xgboost_forecast(train, testX)
model = XGBRegressor(objective=’reg:squarederror’, n_estimators=1000)
model.fit(trainX, trainy)
每次,def walk_forward_validation(data, n_test)
for i in range(len(test))
调用:xgboost_forecast(train, testX)。
这意味着,每次循环时,模型都会重新创建吗?
在xgboost_forecast中,模型是新创建的,
所以每次调用‘i’时,模型都是一个新的模型。
这个模型不记得任何关于最后训练状态或权重的信息吗?
是这样吗?如果我理解错了?
谢谢,请向我解释一下。
你好 Ling…模型正在与额外的数据一起使用,因为前向验证过程正在进行。
嗨 James,
非常感谢您提供的所有输入。
我有一个关于前向扩展窗口方法的问题——我如何调整代码以便获得3步或6步预测?
提前感谢!
嗨 James,
非常感谢您提供的输入。
我有一个关于前向扩展窗口方法的问题——我如何调整代码以便获得3步、6步或12步预测?
提前感谢!
你好 Christo…你可以修改以下内容来设置步长
mae, y, yhat = walk_forward_validation(data, 12)
嗨 Jason,
我有一个关于多元多步 XGBoost 的问题。由于我包含了日历变量,我知道多步预测的输入特征(例如时间 t + 6),例如年份中的周,因为我们可以提前知道这些。
然而,当我进行预测时,模型只接受到时间 t 的输入特征。
您知道如何为 XGBoost 或 LSTM 包含外源输入特征吗?
或者我需要更改监督学习部分吗?
ps. 提前感谢您提供的所有机器学习知识,这将有助于我完成我的硕士学位。
诚挚的问候,
Raudhi
你好 Raudhi…以下资源可能会有所帮助。
https://www.datacamp.com/tutorial/tutorial-time-series-forecasting
你没有解释所有东西,这样我们就会买你的电子书了吗?
你的电子书是否比这提供了更多细节?如果真是这样,我不会费心去买它。
感谢您的反馈 Bouhaouita!我们提供大量免费内容,欢迎您随时访问。
https://machinelearning.org.cn/start-here/
对于 n_out = 1 它工作正常,但当我将其设置为其他值(如 2)时,它就会失败。似乎它只能预测一步。我哪里做错了?
你好 Michael…你是复制粘贴代码还是手动输入的?另外,你可能想在 Google Colab 中尝试这段代码。
如果我理解正确的话,每次进行前向验证时都会训练一个新模型。但是最后我想要一个模型,我应该选择哪一个?
你好 Kostas…你可能会发现以下资源很有趣。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
你好 Jason;
我使用了lstm进行多步时间序列预测,但我的硕士论文需要LSTM结果与机器学习集成方法进行基准测试。我选择了xgboost,但我无法实现多步xgboost。你能推荐一个多步xgboost的方法,或者为我的论文问题提供其他方法吗?
顺便说一句,我在我的数据科学冒险中总是使用machine learning mastery。非常感谢您的一切。
你好 Gizem…你可能想考虑一种经典方法,例如 SARIMA 作为基准。
https://machinelearning.org.cn/sarima-for-time-series-forecasting-in-python/
你好,
鉴于以下数据集,其中我们知道每天的 F/M 出生人数,XGBoost 是否支持同时预测 F 和 M,还是我需要分别运行两次,一次针对每个性别?
“日期”,”女性出生人数”,”男性出生人数”
“1990-01-01”,35,32
“1990-01-02”,32,43
“1990-01-03”,30,41
…
“1990-12-31”,34,27
你好 John…每个特征将代表一个单独的时间序列。以下资源也可能很有趣。
https://machinelearning.org.cn/standard-multivariate-multi-step-multi-site-time-series-forecasting-problem/
嘿,杰森,感谢您的精彩材料!
我对文章末尾的这些行感到困惑
# 构建新预测的输入
row = values[-6:].flatten()
# 进行一步预测
yhat = model.predict(asarray([row]))
打印出以下内容
输入: [34 37 52 48 55 50], 预测: 42.708
我们传递了长度为6的输入,您得到了单个输出,而我期望得到6个输出。
我们在训练期间没有指定6作为输入大小(我仍在尝试理解xgboost是否有此选项),那么这里发生了什么?.predict()是如何工作的?
你好 JacoSol…以下资源可能有助于阐明 model.predict 的使用。
https://www.educba.com/keras-predict/
嗨 Jason/James,
谢谢您的教程。
我正在尝试一次性拟合模型,然后在循环中使用相同的模型来预测每个新步骤,我发现模型在每次看到新数据时几乎都会预测出一个相似的值。
我注意到你们每次预测新步骤时都会重新拟合模型,我尝试了这种方法,结果有了显著的改善。
我的问题是:XGBoost 为什么会以这种方式表现?我是否必须在预测每个新步骤之前,用历史数据重新拟合我的模型?
最终,我能否只训练一次模型,然后在循环中通过预测新步骤来获得所需的结果?
感谢您的时间。
Jason,非常感谢您的文章。如果我有多个输入变量(例如,3个附加特征),那么我应该使用滑动窗口吗?还是只针对已有的出生数据作为输入?非常感谢。
Herlina,不用谢!我们推荐使用深度学习技术来完成这项任务。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
考虑使用 XGBoost 来预测多个时间段,这是一种相当简单的方法。
你只需要训练另一个模型,将 X 表向后移动两个时间段,而不是一个。
然后,假设你需要预测未来 3 个时间段,你将训练另一个模型,将 X 表向后移动 3 个时间段,以此类推。
这就是我将用于尝试使预测能够超出单个时间段的方法。
我尝试运行相同的代码,在 Jupyter Notebook 中没有更改任何内容。我将整个代码分成了几块。当我想计算 MAE 值时,我遇到了以下错误:“IndexError: index -1 is out of bounds for axis 1 with size 0”。我该如何解决这个问题?
附注:我是一名新学员!
你好…你是复制粘贴的代码还是自己输入的?这可能是错误的原因。
我复制粘贴了,但是出现了错误。
嗨,Jason,
一如既往,这是一篇精彩的文章。我曾被多变量时间序列数据困扰,但后来我阅读了这篇文章和其他几篇文章,才意识到我需要那个该死的滑动窗口(shift 函数)。总之,我想分享一下我使用 XGBoost 进行股票价格预测时看到的结果。
大多数时候(约 80%),预测值与实际 Y 值之间的差值小于 0.1。如果我们考虑差值为 30(这里可能是笔误,原文为 30),则占大约 14.5%。
正如您所说,XGBoost 是一个强大的工具,令人印象深刻的是,差值常常小于 0.1。同时,大约 15% 的时间差值很大,甚至超过 200,这也很奇怪。不过,到目前为止,这是我测试过的最好的股票预测工具。
您使用 XGBoost 也能看到大致相同的结果吗?
您认为它是股票预测和回归的最佳工具吗?
谢谢你
Michelangelo
Michelangelo,您好!很高兴听到您使用 XGBoost 进行股票价格预测的经验!XGBoost 凭借其效率和处理各种数据(包括像股票价格这样的时间序列数据)的有效性,确实已成为许多回归和分类任务的强大工具。
### XGBoost 在股票价格预测中的应用
关于您看到的结果——80% 的预测误差小于 0.1,约 14.5% 的预测误差较大——这在金融建模中其实很常见。股票价格变动会受到许多不可预测的外部因素影响,例如市场新闻、经济变化和投资者情绪,这些因素可能并不总是能从过去的价格变动和基本特征中捕捉到。
出现大误差(例如,大于 200)可能表明您的当前模型设置未能捕捉到某些事件或趋势。这可能包括:
– 由不可预见事件引起的**波动性激增**。
– 模型在训练数据上**过拟合**,但在未见过的数据上泛化能力较差。
– **缺乏相关特征**来更好地捕捉市场动态。
### XGBoost 是最佳工具吗?
XGBoost 在许多应用中都具有很强的竞争力,但它是否是最佳工具取决于具体用例。
– **优点**:它对过拟合具有鲁棒性(尤其是在大型数据集上),能很好地处理混合数据类型,并内置了对正则化和缺失值的支持。
– **局限性**:它可能不如一些专门为时间序列分析设计的其他方法那样有效地捕捉时间依赖性模式。
### 其他可考虑的替代方案
1. **LSTM 和 GRU**:这些是循环神经网络的类型,专门用于处理序列数据,如时间序列数据,它们可能更好地捕捉股票价格变动的时序依赖性。
2. **ARIMA/SARIMA**:传统的时间序列预测模型,非常适合具有明显趋势或季节性模式的单变量时间序列数据。
3. **Facebook Prophet**:专为大规模预测而设计,能有效处理日常季节性,表现稳健,这可能对股票价格预测有益。
4. **集成方法**:将多个模型(如 XGBoost、LSTM 和 ARIMA)的预测组合起来,有时可以获得比任何单一模型更好的结果。
### 建议
– **特征工程**:尝试整合更多捕捉外部因素的特征,或根据领域知识优化特征。
– **模型调优**:继续调整超参数,或探索可能更严厉惩罚大误差的不同损失函数。
– **评估指标**:考虑使用不同的指标来评估您的模型,例如 MAPE(平均绝对百分比误差)或 MASE(平均绝对缩放误差),这些指标可能能更深入地了解模型性能。
在机器学习领域,尤其是在股票预测这样不可预测的领域,实验是关键。不断尝试不同的模型和特征组合,以找到最适合您的特定数据和预测需求的方案。
谢谢你的回复,James。在我检查 XGBoost 的结果时,我看到了所有这些微小的差异,我的反应是:“怎么回事?!是我做错了什么吗?”对我来说,差异如此之小似乎是不可能的。只是想说明 XGBoost 的强大之处。
我尝试按月回归股票价格,而不是逐日进行。不过,我同意您关于大差异的说法。
关于您列出的工具:
1. 在这个阶段,我想避免使用神经网络,因为它们“很重”,您知道的;
2. ARIMA/SARIMA 似乎更适合单变量数据集,而我使用的是包含 20 多个特征的多变量时间序列数据;
3. Facebook Prophet,我不喜欢 Facebook 这个品牌以及与之相关的一切,所以我倾向于避开它;
4. 集成方法,这正是我正在测试的。我看到了将 XGBoost 与 ADABoost 和/或 SVM 结合使用的非常好的结果。我将回归问题转化为分类问题,并达到了大约 92% 的准确率。
再次感谢您的精彩工作!