
你的第一个本地 LLM API Python 项目分步指南
图片来源:编辑 | Midjourney
您是否有兴趣在您自己的机器上,使用 Python 和一些不太复杂的工具框架来利用一个本地的大型语言模型 (LLM) API? 在这篇分步文章中,您将设置一个本地 API,您可以通过该 API 向您机器上下载的 LLM 发送提示并获得响应。这类似于 ChatGPT,但完全在本地运行。
通过遵循以下步骤,您将
- 在您的机器上设置Ollama:一个用户友好的框架,可以基于基本界面本地运行 LLaMA、Gemma 或 Mistral 等开放 LLM。
- 使用FastAPI构建一个健壮轻量级的 REST API,通过 HTTP 请求实现用户与模型的交互。
- 通过您的本地端点发送提示并获得 LLM 的近乎实时的响应,而无需依赖云提供商的外部服务。
预读材料
为了让您熟悉或重新温习本文使用的概念和工具,这里有一些推荐的阅读材料
- 开始使用 LLM 的 5 个必备免费工具
- 10 个大型语言模型关键概念解释
- Python LLM 入门指南 (含 Ollama)
分步流程
我们开始吧!本教程假设您的机器上已安装 Python 3.9 或更高版本,并且您对 Python 语言有基础到中级的理解。考虑到这一点,代码设计用于在 IDE(如 Visual Studio Code 或类似工具)中创建的 Python 项目中实现——请注意,这不是一个适合在线笔记本的教程,因为我们需要在本地下载和使用 LLM。
在本地安装 Ollama 并下载 LLM
根据您的操作系统,您可以从其 网站下载 Ollama 的一个版本。下载并启动后,打开终端并输入此命令
|
1 |
ollama run llama3 |
此命令将在本地拉取(下载)一个 Llama 3 LLM — 在编写本文时,默认下载的模型引用为 llama3:latest。请注意,第一次下载时,完全下载需要一段时间,这在很大程度上取决于您的互联网连接带宽。一旦完全拉取,终端将自动启动一个对话助手,您可以在其中开始交互。
但请注意,我们将采取不同的方法,展示构建本地 Python LLM API 的基本步骤。为此,让我们切换到我们的 IDE。
在 VS Code (或其他 IDE) 中创建 Python 项目
假设您使用的是 VS Code(如果您使用其他 IDE,可能需要采取略有不同的操作),请在文件目录中创建一个新的项目文件夹,名为“local-llm-api”或类似名称。
在该文件夹内,我们将创建两个文件,分别名为“main.py”和“requirements.txt”。目前,我们让 Python 文件留空,然后在“requirements.txt”文件中添加以下内容并保存更改
|
1 2 3 |
fastapi uvicorn requests |
在使用本地 LLM 时,建议设置虚拟环境,因为它能隔离依赖项,防止库版本之间的冲突,并保持整体开发环境的整洁。在 VS Code 中,您可以通过以下方式进行操作:
- 按 Command + Shift + P 打开命令面板。
- 输入或选择 Python:Create Environment,然后选择 Venv。
- 选择一个合适的 Python 版本(我选择了 Python 3.11)。
- 现在应该会提示您选择之前创建的“requirements.txt”文件来安装列出的依赖项,这非常重要,因为我们的 Python 程序将需要 FastAPI、Uvicorn 和 Requests。
如果最后一步不起作用,请尝试在 IDE 的终端中运行
|
1 |
pip install fastapi uvicorn requests |
主要的 Python 程序
让我们回到之前创建的空“main.py”文件,并添加以下代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
from fastapi import FastAPI from pydantic import BaseModel import requests import json import uvicorn import os # 添加用于环境变量的使用 app = FastAPI() class Prompt(BaseModel): prompt: str @app.post("/generate") def generate_text(prompt: Prompt): try: # 使用环境变量作为主机和模型,并提供备用值 ollama_host = os.getenv("OLLAMA_HOST", "https://:11434") ollama_model = os.getenv("OLLAMA_MODEL", "llama3:latest") response = requests.post( f"{ollama_host}/api/generate", # f-string 用于主机 json={"model": ollama_model, "prompt": prompt.prompt}, # 使用 ollama_model stream=True, timeout=120 # 给模型响应时间 ) response.raise_for_status() # 针对 HTTP 错误(4xx 或 5xx)引发异常 output = "" for line in response.iter_lines(): if line: data = line.decode("utf-8").strip() if data.startswith("data: "): data = data[len("data: "):] if data == "[DONE]": break try: chunk = json.loads(data) output += chunk.get("response") or chunk.get("text") or "" except json.JSONDecodeError: print(f"警告:无法解码行中的 JSON:{data}") # 添加用于调试 continue return {"response": output.strip() or "(模型响应为空)"} except requests.RequestException as e: return {"error": f"Ollama 请求失败:{str(e)}"} if __name__ == "__main__": # 对于开发,reload=True 可能有用。对于生产环境,请使用 reload=False。 uvicorn.run("main:app", host="127.0.0.1", port=8000, reload=False) |
暂时不要惊慌:我们马上会分解和解释这段代码的关键部分
app = FastAPI()创建由 REST 服务驱动的 Web API,一旦 Python 程序执行,它将开始侦听并服务(提示)请求,使用本地 LLM。class Prompt(BaseModel):和prompt: str创建 JSON 输入模式,通过该模式我们可以为 LLM 输入提示。@app.post("/generate")和def generate_text(prompt: Prompt):定义了利用 API 端点发送提示并获取模型响应的函数。- 以下代码至关重要:
123456response = requests.post("https://:11434/api/generate",json={"model": "llama3:latest", "prompt": prompt.prompt},stream=True,timeout=120)
它将提示发送到 Ollama 获取的指定本地 LLM。重要的是,您必须确保模型名称是您下载的模型之一(在本例中为"llama3:latest")。您可以通过在终端中键入命令ollama list来查看您机器上下载的本地模型名称。 - 最后,这段代码会读取流式响应并以可读的格式返回。
|
1 2 3 4 5 6 |
for line in response.iter_lines(): ... chunk = json.loads(data) output += chunk.get("response") or chunk.get("text") or "" return {"response": output.strip()} |
运行和测试 API
保存 Python 文件后,点击“运行”图标或在终端中运行 python main.py。您应该会在 IDE 的输出中看到类似以下内容:
|
1 |
INFO: Uvicorn 正在运行 在 http://127.0.0.1:8000 (按 CTRL+C 退出) |
这意味着一件事:REST 服务器已启动并正在运行,并且可以通过 http://127.0.0.1:8000/docs 访问该服务。在浏览器中打开此 URL,如果一切顺利,您将看到一个 FastAPI 文档界面,如下所示:
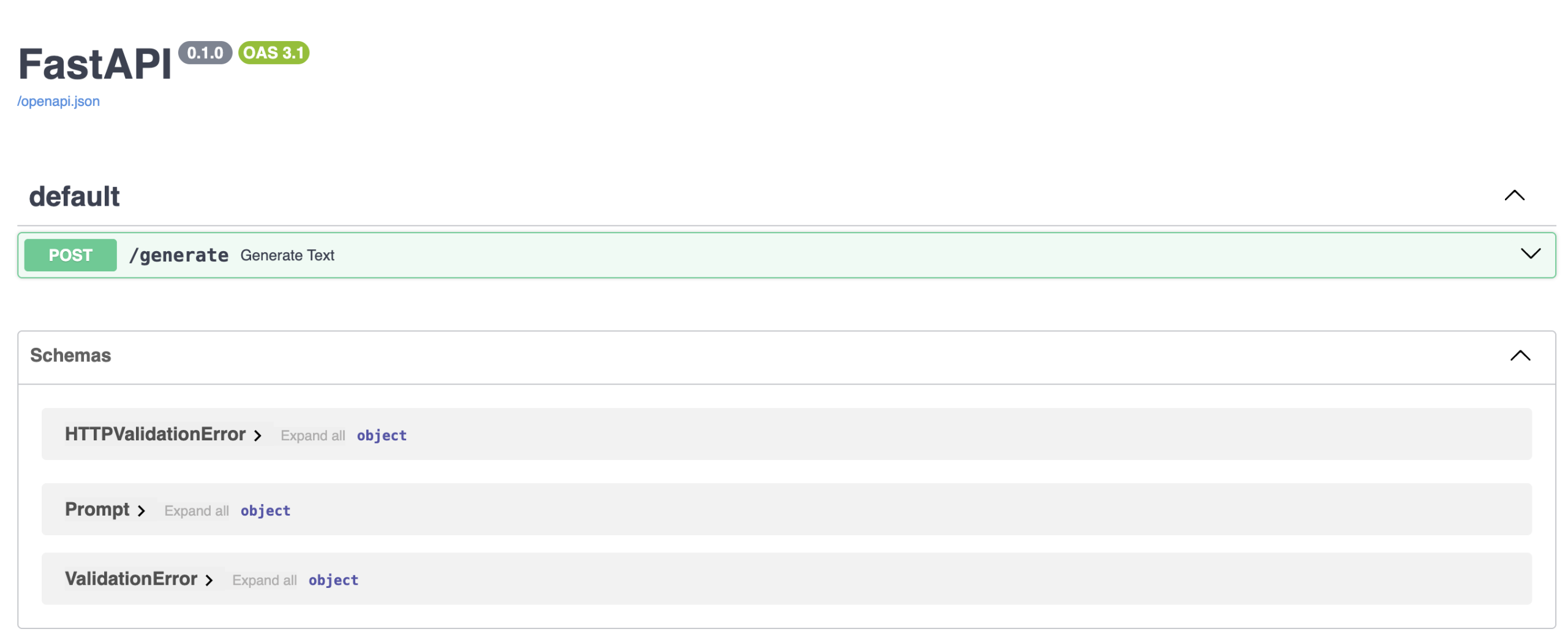
您离提示您的本地 LLM 仅一步之遥:太令人兴奋了!在显示的界面中,点击 POST/generate 框旁边的箭头将其展开,然后点击“Try it out”按钮。
输入您选择的提示,让 LLM 做一些事情。您必须在专用的类似 JSON 的参数值中进行,如下所示,替换默认提示:"string"。例如:

点击“Execute”按钮后,几秒钟内您可能可以通过向下滚动一点来获得响应
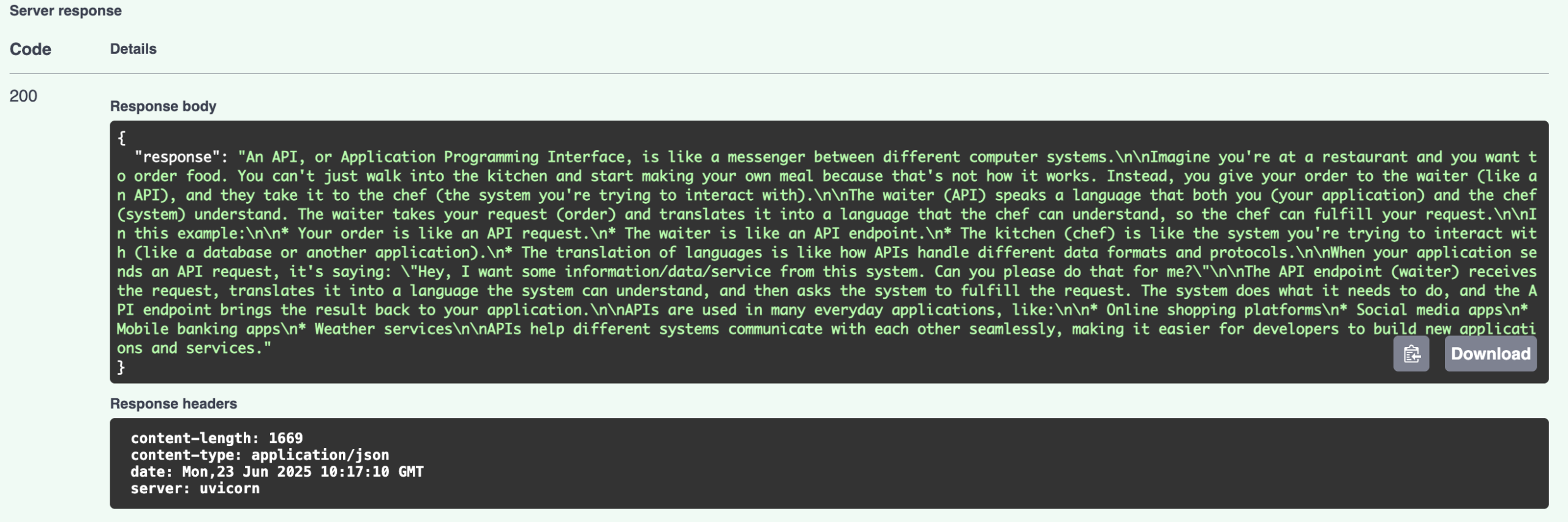
恭喜您,您已经搭建了自己的本地 LLM API!
对这个第一个演示进行高级改进的可能想法包括:构建一个消费 FastAPI API 的前端,例如使用 Streamlit。您可能还想探索使用针对营销、保险、物流等自定义或特定领域用例的微调模型。
结论
本文分步介绍了如何设置和运行您的第一个本地大型语言模型 API,使用 Ollama 下载的本地模型,以及 FastAPI 通过基于 REST 服务的接口进行快速模型推理。所有这些都可以通过在您自己的 IDE 中运行本地 Python 程序,舒适地在您的机器上完成。






最好使用事件发射器,因为它通常用于程序不同部分之间的异步通信。