特征选择是识别和选择与目标变量最相关的输入变量子集的过程。
也许最简单的特征选择情况是,对于回归预测建模,存在数值输入变量和数值目标。这是因为可以计算每个输入变量与目标之间关系的强度,称为相关性,并相互比较。
在本教程中,您将学习如何使用数值输入数据进行回归预测建模的特征选择。
完成本教程后,您将了解:
- 如何使用相关性和互信息统计量评估数值输入数据的重要性。
- 如何在拟合和评估回归模型时对数值输入数据执行特征选择。
- 如何使用网格搜索调整建模管道中选择的特征数量。
通过我的新书《机器学习数据准备》启动您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何对回归数据执行特征选择
摄影:Dennis Jarvis,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 回归数据集
- 数值特征选择
- 相关性特征选择
- 互信息特征选择
- 使用选定特征进行建模
- 使用所有特征构建的模型
- 使用相关性特征构建的模型
- 使用互信息特征构建的模型
- 调整选定特征的数量
回归数据集
我们将使用合成回归数据集作为本教程的基础。
回想一下,回归问题是一个我们想要预测数值的问题。在这种情况下,我们需要一个也具有数值输入变量的数据集。
scikit-learn 库中的 make_regression() 函数可用于定义数据集。它提供了对样本数量、输入特征数量以及重要的相关和冗余输入特征数量的控制。这很关键,因为我们特别需要一个我们知道具有一些冗余输入特征的数据集。
在这种情况下,我们将定义一个包含1000个样本的数据集,每个样本具有100个输入特征,其中10个是信息性的,其余90个是冗余的。
|
1 2 3 |
... # 生成回归数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) |
希望特征选择技术能够识别出一些或所有与目标相关的特征,或者至少识别并移除一些冗余的输入特征。
定义完成后,我们可以将数据分成训练集和测试集,以便拟合和评估学习模型。
我们将使用 scikit-learn 中的 train_test_split() 函数,使用67%的数据进行训练,33%的数据进行测试。
|
1 2 3 |
... # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) |
将这些元素结合起来,下面列出了定义、拆分和汇总原始回归数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 |
# 加载并汇总数据集 from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split # 生成回归数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 总结 print('Train', X_train.shape, y_train.shape) print('Test', X_test.shape, y_test.shape) |
运行示例报告了训练集和测试集的输入和输出元素的尺寸。
我们可以看到我们有670个训练样本和330个测试样本。
|
1 2 |
训练集 (670, 100) (670,) 测试集 (330, 100) (330,) |
现在我们已经加载并准备好数据集,我们可以探索特征选择。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数值特征选择
有两种流行的特征选择技术可以用于数值输入数据和数值目标变量。
它们是
- 相关性统计。
- 互信息统计。
让我们依次仔细看看每一个。
相关性特征选择
相关性是衡量两个变量如何共同变化的指标。也许最常见的相关性度量是 皮尔逊相关系数,它假设每个变量都服从高斯分布并报告它们的线性关系。
对于数值预测变量,量化每个变量与结果之间关系的经典方法是使用样本相关统计量。
— 第464页,《应用预测建模》,2013年。
有关线性或参数相关性的更多信息,请参阅教程
线性相关分数通常介于-1和1之间,其中0表示没有关系。对于特征选择,我们通常对正分数感兴趣,正值越大,关系越大,越有可能选择该特征进行建模。因此,线性相关性可以转换为只有正值的相关统计量。
scikit-learn 机器学习库在 f_regression() 函数中提供了相关统计量的实现。此函数可用于特征选择策略,例如通过 SelectKBest 类选择前 k 个最相关的特征(最大值)。
例如,我们可以定义 *SelectKBest* 类使用 *f_regression()* 函数并选择所有特征,然后转换训练集和测试集。
|
1 2 3 4 5 6 7 8 9 10 |
... # 配置以选择所有特征 fs = SelectKBest(score_func=f_regression, k='all') # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs |
然后我们可以打印每个变量的分数(分数越大越好),并将每个变量的分数绘制成条形图,以了解我们应该选择多少个特征。
|
1 2 3 4 5 6 7 |
... # 特征得分是多少 for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # 绘制分数 pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show() |
结合上一节的数据准备,下面列出了完整的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 数值数据相关性特征选择的示例 from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import f_regression from matplotlib import pyplot # 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择所有特征 fs = SelectKBest(score_func=f_regression, k='all') # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 加载数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test) # 特征得分是多少 for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # 绘制分数 pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show() |
运行该示例首先打印为每个输入特征和目标变量计算的分数。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
我们不会列出所有100个输入变量的分数,因为它会占用太多空间。尽管如此,我们可以看到有些变量的分数比其他变量大,例如小于1与5,而其他变量的分数则大得多,例如特征9的分数是101。
|
1 2 3 4 5 6 7 8 9 10 11 |
特征 0: 0.009419 特征 1: 1.018881 特征 2: 1.205187 特征 3: 0.000138 特征 4: 0.167511 特征 5: 5.985083 特征 6: 0.062405 特征 7: 1.455257 特征 8: 0.420384 特征 9: 101.392225 ... |
创建了一个显示每个输入特征的特征重要性分数的条形图。
该图清楚地显示了8到10个特征比其他特征重要得多。
我们可以将 *SelectKBest* 中的 *k* 设置为10来选择这些最重要的特征。
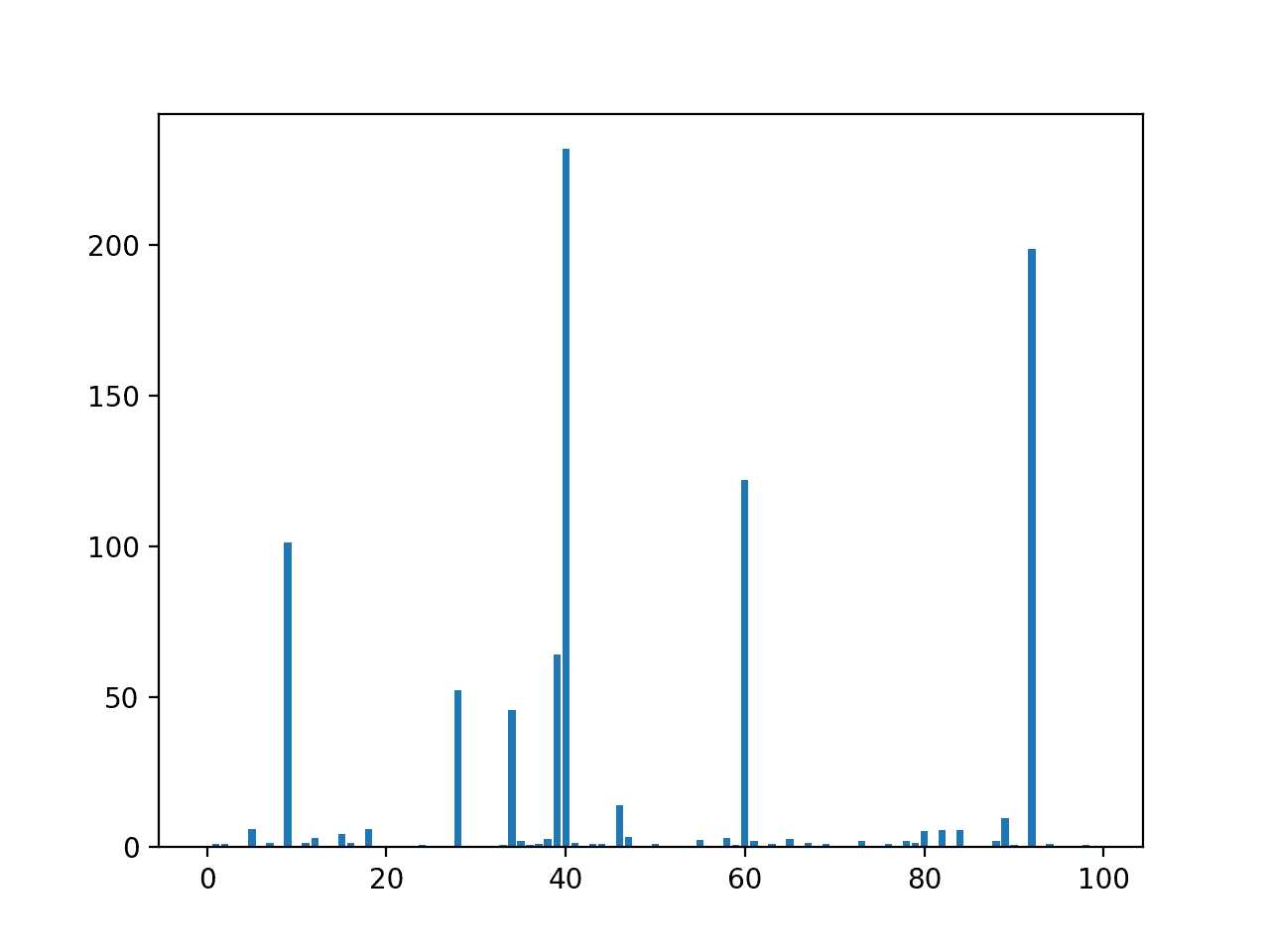
输入特征(x)与相关性特征重要性(y)的条形图
互信息特征选择
信息论领域的互信息是信息增益(通常用于决策树的构建)在特征选择中的应用。
互信息在两个变量之间计算,并衡量给定另一个变量已知值时,一个变量不确定性的减少量。
您可以在以下教程中了解更多关于互信息的信息。
当考虑两个离散(分类或序数)变量的分布时,例如分类输入和分类输出数据,互信息是直接的。然而,它可以适用于数值输入和输出数据。
有关如何实现此目的的技术细节,请参阅2014年题为“离散和连续数据集之间的互信息”的论文。
scikit-learn 机器学习库通过 mutual_info_regression() 函数,为具有数值输入和输出变量的特征选择提供了互信息的实现。
像 *f_regression()* 一样,它可以在 *SelectKBest* 特征选择策略(以及其他策略)中使用。
|
1 2 3 4 5 6 7 8 9 10 |
... # 配置以选择所有特征 fs = SelectKBest(score_func=mutual_info_regression, k='all') # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs |
我们可以像上一节一样,使用互信息对数据集进行特征选择,并打印和绘制分数(越大越好)。
下面列出了使用互信息进行数值特征选择的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 数值输入数据互信息特征选择示例 from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_regression from matplotlib import pyplot # 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择所有特征 fs = SelectKBest(score_func=mutual_info_regression, k='all') # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 加载数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test) # 特征得分是多少 for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # 绘制分数 pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show() |
运行该示例首先打印为每个输入特征和目标变量计算的分数。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
同样,我们不会列出所有100个输入变量的分数。我们可以看到许多特征的分数为0.0,而这种技术已经识别出更多可能与目标相关的特征。
|
1 2 3 4 5 6 7 8 9 10 11 |
特征 0: 0.045484 特征 1: 0.000000 特征 2: 0.000000 特征 3: 0.000000 特征 4: 0.024816 特征 5: 0.000000 特征 6: 0.022659 特征 7: 0.000000 特征 8: 0.000000 特征 9: 0.074320 ... |
创建了一个显示每个输入特征的特征重要性分数的条形图。
与相关性特征选择方法相比,我们可以清楚地看到更多的特征被评定为相关。这可能是由于我们在数据集构建中添加的统计噪声。
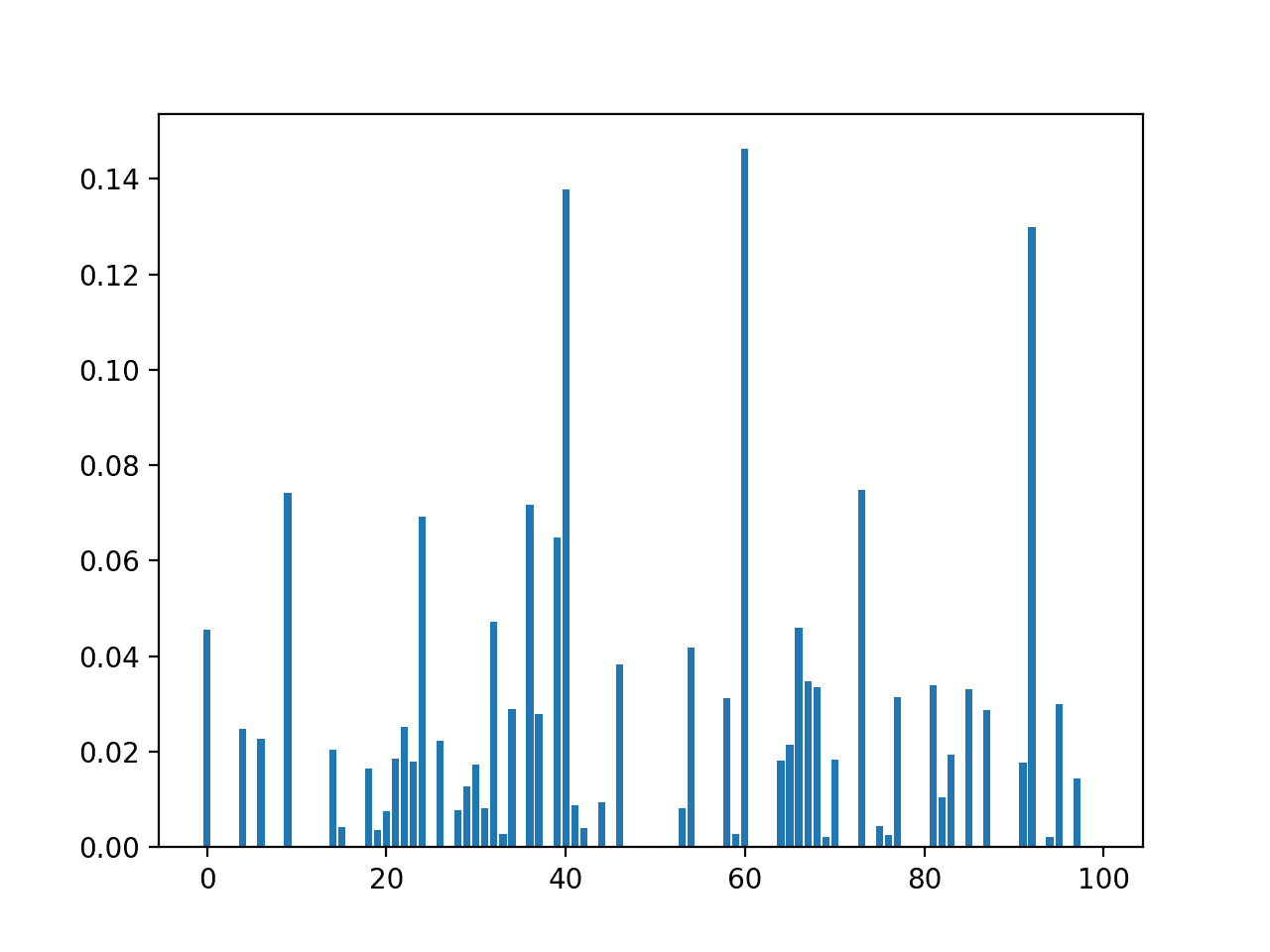
输入特征(x)与互信息特征重要性(y)的条形图
现在我们知道如何对回归预测建模问题中的数值输入数据执行特征选择,我们可以尝试使用选定的特征开发模型并比较结果。
使用选定特征进行建模
有许多不同的技术可以用于特征评分和基于分数选择特征;您如何知道应该使用哪一种?
一种稳健的方法是使用不同的特征选择方法(和特征数量)评估模型,并选择能够产生最佳性能模型的方法。
在本节中,我们将评估一个线性回归模型,其中包含所有特征,并将其与使用相关性统计量和互信息选择的特征构建的模型进行比较。
线性回归是测试特征选择方法的好模型,因为如果从模型中移除不相关的特征,它的性能可能会更好。
使用所有特征构建的模型
第一步,我们将使用所有可用特征评估一个 LinearRegression 模型。
该模型在训练数据集上进行拟合,并在测试数据集上进行评估。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用所有输入特征评估模型 from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split 来自 sklearn.linear_model 导入 LinearRegression from sklearn.metrics import mean_absolute_error # 加载数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 拟合模型 模型 = LinearRegression() model.fit(X_train, y_train) # 评估模型 yhat = model.predict(X_test) # 评估预测 mae = mean_absolute_error(y_test, yhat) print('MAE: %.3f' % mae) |
运行示例将打印模型在训练数据集上的平均绝对误差 (MAE)。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到模型实现了大约0.086的误差。
我们更希望使用特征子集来获得同样好或更好的误差。
|
1 |
平均绝对误差 (MAE): 0.086 |
使用相关性特征构建的模型
我们可以使用相关性方法对特征进行评分,并选择10个最相关的特征。
下面的 *select_features()* 函数已更新以实现此目的。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择特征子集 fs = SelectKBest(score_func=f_regression, k=10) # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs |
下面列出了使用此特征选择方法拟合和评估线性回归模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 使用相关性选择的10个特征评估模型 from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import f_regression 来自 sklearn.linear_model 导入 LinearRegression from sklearn.metrics import mean_absolute_error # 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择特征子集 fs = SelectKBest(score_func=f_regression, k=10) # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 加载数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test) # 拟合模型 模型 = LinearRegression() model.fit(X_train_fs, y_train) # 评估模型 yhat = model.predict(X_test_fs) # 评估预测 mae = mean_absolute_error(y_test, yhat) print('MAE: %.3f' % mae) |
运行该示例报告了模型在仅使用相关统计量选择的100个输入特征中的10个特征上的性能。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
在这种情况下,我们看到模型获得了大约2.7的误差分数,这远大于使用所有特征的基线模型所实现的0.086的MAE。
这表明,尽管该方法对选择哪些特征有很强的想法,但仅使用这些特征构建模型并不能产生更熟练的模型。这可能是因为与目标重要的特征被遗漏了,这意味着该方法被欺骗了关于哪些是重要的。
|
1 |
MAE: 2.740 |
让我们换个思路,尝试使用该方法移除一些冗余特征,而不是所有冗余特征。
我们可以通过将所选特征的数量设置为一个更大的值,在本例中为88,希望它能找到并丢弃90个冗余特征中的12个。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 使用相关性选择的88个特征评估模型 from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import f_regression 来自 sklearn.linear_model 导入 LinearRegression from sklearn.metrics import mean_absolute_error # 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择特征子集 fs = SelectKBest(score_func=f_regression, k=88) # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 加载数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test) # 拟合模型 模型 = LinearRegression() model.fit(X_train_fs, y_train) # 评估模型 yhat = model.predict(X_test_fs) # 评估预测 mae = mean_absolute_error(y_test, yhat) print('MAE: %.3f' % mae) |
运行该示例报告了模型在使用相关统计量选择的100个输入特征中的88个特征上的性能。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到移除一些冗余特征使得性能略有提升,误差约为0.085,而基线模型的误差约为0.086。
|
1 |
MAE: 0.085 |
使用互信息特征构建的模型
我们可以重复实验,使用互信息统计量选择前88个特征。
下面列出了更新后的 *select_features()* 函数以实现此目的。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择特征子集 fs = SelectKBest(score_func=mutual_info_regression, k=88) # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs |
下面列出了使用互信息进行特征选择以拟合线性回归模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 使用互信息选择的88个特征评估模型 from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_regression 来自 sklearn.linear_model 导入 LinearRegression from sklearn.metrics import mean_absolute_error # 特征选择 def select_features(X_train, y_train, X_test): # 配置以选择特征子集 fs = SelectKBest(score_func=mutual_info_regression, k=88) # 从训练数据中学习关系 fs.fit(X_train, y_train) # 转换训练输入数据 X_train_fs = fs.transform(X_train) # 转换测试输入数据 X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 加载数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test) # 拟合模型 模型 = LinearRegression() model.fit(X_train_fs, y_train) # 评估模型 yhat = model.predict(X_test_fs) # 评估预测 mae = mean_absolute_error(y_test, yhat) print('MAE: %.3f' % mae) |
运行示例后,模型将拟合互信息选择的前88个特征。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
在这种情况下,与相关统计量相比,我们可以看到误差进一步减小,本例中MAE约为0.084,而上一节中为0.085。
|
1 |
MAE: 0.084 |
调整选定特征的数量
在前面的例子中,我们选择了88个特征,但我们怎么知道这是一个好或最好的特征数量呢?
与其猜测,不如系统地测试一系列不同数量的选定特征,并发现哪个能产生最佳性能的模型。这被称为网格搜索,其中 SelectKBest 类的 *k* 参数可以进行调优。
在回归任务中,使用重复分层k折交叉验证来评估模型配置是一种好习惯。我们将通过RepeatedKFold 类使用10折交叉验证的3次重复。
|
1 2 3 |
... # 定义评估方法 cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) |
我们可以定义一个 管道(Pipeline),它在训练集上正确地准备特征选择转换,并将其应用于交叉验证的每个折叠的训练集和测试集。
在这种情况下,我们将使用互信息统计方法来选择特征。
|
1 2 3 4 5 |
... # 定义要评估的管道 模型 = LinearRegression() fs = SelectKBest(score_func=mutual_info_regression) pipeline = Pipeline(steps=[('sel',fs), ('lr', model)]) |
然后我们可以定义要评估的网格值,范围为80到100。
请注意,网格是一个参数到值的搜索字典映射,鉴于我们正在使用 *Pipeline*,我们可以通过我们给它的名称“*sel*”访问 *SelectKBest* 对象,然后通过两个下划线分隔的参数名称“*k*”,即“*sel__k*”。
|
1 2 3 4 |
... # 定义网格 grid = dict() grid['sel__k'] = [i for i in range(X.shape[1]-20, X.shape[1]+1)] |
然后我们可以定义并运行搜索。
在这种情况下,我们将使用负平均绝对误差(neg_mean_absolute_error)来评估模型。它是负的,因为scikit-learn要求分数最大化,所以MAE被转换为负值,这意味着分数从-无穷大到0(最好)。
|
1 2 3 4 5 |
... # 定义网格搜索 search = GridSearchCV(pipeline, grid, scoring='neg_mean_absolure_error', n_jobs=-1, cv=cv) # 执行搜索 results = search.fit(X, y) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 比较使用互信息选择的不同数量的特征 from sklearn.datasets import make_regression from sklearn.model_selection import RepeatedKFold 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_regression 来自 sklearn.linear_model 导入 LinearRegression from sklearn.pipeline import Pipeline from sklearn.model_selection import GridSearchCV # 定义数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 定义评估方法 cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义要评估的管道 模型 = LinearRegression() fs = SelectKBest(score_func=mutual_info_regression) pipeline = Pipeline(steps=[('sel',fs), ('lr', model)]) # 定义网格 grid = dict() grid['sel__k'] = [i for i in range(X.shape[1]-20, X.shape[1]+1)] # 定义网格搜索 search = GridSearchCV(pipeline, grid, scoring='neg_mean_squared_error', n_jobs=-1, cv=cv) # 执行搜索 results = search.fit(X, y) # 总结最佳结果 print('Best MAE: %.3f' % results.best_score_) print('Best Config: %s' % results.best_params_) # 总结所有结果 means = results.cv_results_['mean_test_score'] params = results.cv_results_['params'] for mean, param in zip(means, params): print(">%.3f with: %r" % (mean, param)) |
运行示例网格搜索使用互信息统计量选择的不同数量的特征,其中每个建模管道都使用重复交叉验证进行评估。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到最佳选定特征数量为81,其MAE约为0.082(忽略符号)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
最佳 MAE: -0.082 最佳配置:{'sel__k': 81} >-1.100,使用:{'sel__k': 80} >-0.082,使用:{'sel__k': 81} >-0.082,使用:{'sel__k': 82} >-0.082,使用:{'sel__k': 83} >-0.082,使用:{'sel__k': 84} >-0.082,使用:{'sel__k': 85} >-0.082,使用:{'sel__k': 86} >-0.082,使用:{'sel__k': 87} >-0.082,使用:{'sel__k': 88} >-0.083,使用:{'sel__k': 89} >-0.083,使用:{'sel__k': 90} >-0.083,使用:{'sel__k': 91} >-0.083,使用:{'sel__k': 92} >-0.083,使用:{'sel__k': 93} >-0.083,使用:{'sel__k': 94} >-0.083,使用:{'sel__k': 95} >-0.083,使用:{'sel__k': 96} >-0.083,使用:{'sel__k': 97} >-0.083,使用:{'sel__k': 98} >-0.083,使用:{'sel__k': 99} >-0.083,使用:{'sel__k': 100} |
我们可能想了解选定特征数量与MAE之间的关系。在这种关系中,我们可能会期望更多的特征会导致更好的性能,直到某个点。
这种关系可以通过手动评估SelectKBest的每个k配置,从81到100,收集MAE分数样本,并并排绘制结果的箱线图来探索。这些箱线图的分布和均值预计将显示选定特征数量与管道MAE之间的任何有趣关系。
请注意,我们将 *k* 值的范围从81开始而不是80,因为 *k=80* 的MAE分数分布远大于所有其他考虑的 *k* 值,它会淹没结果图。
下面列出了实现此目的的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 比较使用互信息选择的不同数量的特征 from numpy import mean from numpy import std from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedKFold 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_regression 来自 sklearn.linear_model 导入 LinearRegression from sklearn.pipeline import Pipeline from matplotlib import pyplot # 定义数据集 X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1) # 定义要评估的特征数量 num_features = [i for i in range(X.shape[1]-19, X.shape[1]+1)] # 枚举每个特征数量 results = list() for k in num_features: # 创建管道 model = LinearRegression() fs = SelectKBest(score_func=mutual_info_regression, k=k) pipeline = Pipeline(steps=[('sel',fs), ('lr', model)]) # 评估模型 cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(pipeline, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1) results.append(scores) # 汇总结果 print('>%d %.3f (%.3f)' % (k, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=num_features, showmeans=True) pyplot.show() |
运行该示例首先报告每个选定特征数量的平均和标准差MAE。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
在这种情况下,报告MAE的平均值和标准差并不是非常有趣,除了80年代的k值似乎优于90年代的k值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>81 -0.082 (0.006) >82 -0.082 (0.006) >83 -0.082 (0.006) >84 -0.082 (0.006) >85 -0.082 (0.006) >86 -0.082 (0.006) >87 -0.082 (0.006) >88 -0.082 (0.006) >89 -0.083 (0.006) >90 -0.083 (0.006) >91 -0.083 (0.006) >92 -0.083 (0.006) >93 -0.083 (0.006) >94 -0.083 (0.006) >95 -0.083 (0.006) >96 -0.083 (0.006) >97 -0.083 (0.006) >98 -0.083 (0.006) >99 -0.083 (0.006) >100 -0.083 (0.006) |
并排创建了箱线图,显示了 *k* 与MAE的趋势,其中绿色三角形代表均值,橙色线代表分布的中位数。
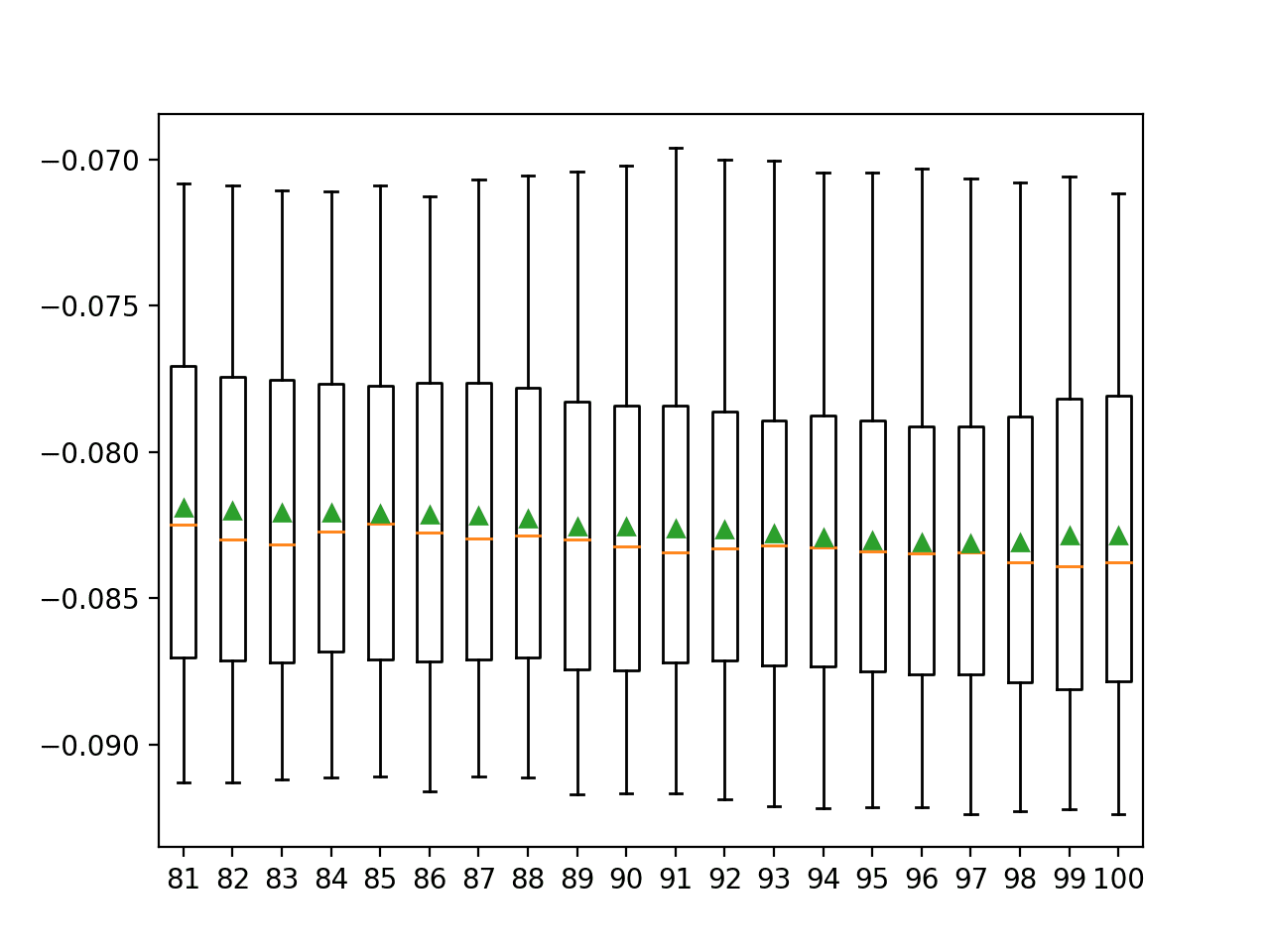
使用互信息选择的每个特征数量的MAE箱线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 应用预测建模, 2013.
API
- 特征选择,Scikit-Learn 用户指南.
- sklearn.datasets.make_regression API.
- sklearn.feature_selection.f_regression API.
- sklearn.feature_selection.mutual_info_regression API.
文章
总结
在本教程中,您了解了如何为回归预测建模使用数值输入数据进行特征选择。
具体来说,你学到了:
- 如何使用相关性和互信息统计量评估数值输入数据的重要性。
- 如何在拟合和评估回归模型时对数值输入数据执行特征选择。
- 如何使用网格搜索调整建模管道中选择的特征数量。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






 for Feature Selection in Python")
您能解释一下管道语句中的lr模型吗
是的,它是一个线性回归模型。
如果你想尝试随机森林等其他模型,可以替换'lr'吗?
当然可以!
你好 Jason,
我有一个关于Keras隐藏层(dense)的问题。
有没有什么最佳实践可以知道一个网络最好添加/定义多少个隐藏层,以及如何为每个隐藏层(例如 .Dense(number, activation='relu') 中的数字)定义一个有效的值。
谢谢,
Marco
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
你好,Jason
有没有关于分类问题的特征选择教程?
谢谢
约翰尼
是的,也许从这里开始
https://machinelearning.org.cn/rfe-feature-selection-in-python/
还有这里
https://machinelearning.org.cn/feature-selection-with-numerical-input-data/
特征选择和特征提取有什么区别。PCA与互信息技术不同。
PCA 是一种降维技术,可以称为特征提取。它将数据投影到较低维空间并改变所有值。
特征选择不改变数据值,只移除一些列(特征)。
先生,您能解释一下如何训练和测试一组图像吗?这样我们就可以识别已知图像了。
是的,您可以从这里开始图像分类
https://machinelearning.org.cn/start-here/#dlfcv
有没有关于使用机器学习进行回归的特征选择方法的教程?
也许这会有帮助。
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
有没有关于使用机器学习选择非线性特征选择方法回归的教程?
也许从RFE开始
https://machinelearning.org.cn/rfe-feature-selection-in-python/
嗨,Jason,
给您一个评论。在管道化 SelectKBest 中的特征数量进行调优时,训练集、验证集和测试集不应该分开吗?想象一下,我还想在不同的过滤方法之间进行选择。那么对于每种特征选择方法(无论是 Regression_f 还是 Mutual),我首先通过
results = search.fit(X_train, y_train)
然后我将使用测试集和性能度量(MAE)来查看哪种方法以及最佳调优参数在测试集上表现更好。MAE(Test)。
您已在所有数据上耗尽了CV
results = search.fit(X, y)
并且没有在测试集上比较特征选择方法的余地。我是对的还是错了?
特征选择在训练集上进行拟合,并应用于训练集、测试集和验证集,以确保我们避免数据泄露。
网格搜索中使用的管道确保了这一点,但假设在所有情况下都使用管道。
你好,先生,
我正在对高维数据(特征数量超过10000)进行回归分析,您能推荐任何特征选择方法吗? (互信息回归适用于高维数据吗?),我知道特征和输出值之间的关系是非线性的,我想知道互信息回归能否捕捉非线性依赖关系?
谢谢你
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/what-feature-selection-method-should-i-use
嗨,Jason,
如何将特征映射到数据集中的实际列标题?
如果你有一个列标题名称的列表或数组,这很常见,那么你可以在该数组中使用选定的特征索引。
如果您不熟悉数组索引,我建议从这里开始
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
嗨,Jason,
感谢您的帖子。在所有回归问题的特征选择方法中,我如何知道选择哪种方法?因为每种方法的输出的选定特征略有不同。谢谢!
好问题,我在这里回答
https://machinelearning.org.cn/faq/single-faq/what-feature-selection-method-should-i-use
谢谢!
不客气。
你好!非常感谢您的帖子!
精彩的文章!
我想知道,在发现80个特征是最佳数量之后,您如何知道哪些是那80个选定的特征?
谢谢!
不客气。
您可以使用算法选择它们并打印它们的索引,甚至可以将它们映射到列名。
请参阅此处“选择了哪些特征”部分
https://machinelearning.org.cn/rfe-feature-selection-in-python/
嗨,Jason,
很棒的教程!
关于拉里萨的问题。
获得实际给出最佳性能模型的特征以及它的系数(多元线性回归模型)最简单的方法是什么?
提前感谢。
系数大小(对于标准化或归一化输入)可以给出一些关于特征重要性的概念。
抱歉我的问题,但我没有理解这行代码
grid[‘sel__k’] = [i for i in range(X.shape[1]-20, X.shape[1]+1)]
-20指的是什么?
-20 从 X.shape[1] 的值中减去20。
在这种情况下,形状是100,减去20得到80,因此范围是80到100。我们加1是因为范围在最后一个值之前停止。
希望这能有所帮助。
对不起我的问题,我是机器学习的初学者
为什么我们要精确地减去20??
因为我想展示模型性能在80到100个特征上的影响。这是任意的。
我明白了。谢谢。
不客气。
你好,此代码用于选择最佳特征数量,以获得最佳MAE值(例如前20个特征或前50个特征)。
但不是给出MAE值的最佳特征(例如特征1、6、20、40、50)。
那么如何才能获得给出最佳MAE值的最重要特征呢?
谢谢你。
这取决于您如何定义“最佳特征”。对我来说,它是能提供最佳模型性能的子集。
– 也许尝试所有子集。
– 也许尝试特征重要性。
– 也许尝试替代的特征选择方法。
感谢您非常有用的帖子,Jason!这里令人惊讶的是,在仅使用10个信息性特征进行选择和拟合后,性能出现了如此大的下降。我天真地期望至少能获得一个相似性能的模型,考虑到数据是围绕这10个相关特征设计的。
我想知道所有冗余特征到底添加了什么,能产生如此更好的模型性能。
这告诉我,使用相关性来判断重要性的方法是高度可疑的,可能根本不应该使用。
并非可疑,只是信息性特征难以识别。
你好,谢谢你的教程。为什么 f_regression 的 SelectKBest 分数不在 [-1,1] 范围内?
因为它在这个例子中使用了 f_regression,其得分是一个 F 统计量:https://en.wikipedia.org/wiki/F-test
很好,只是有一个疑问,在第一个输出中,我们得到特征分数,例如特征0:0.455等等。特征0是否与X数据帧中给出的输入中的同一列(或变量)相同?例如,如果数据帧的头部是petal.len,petal.color,flower.color等。那意味着特征0是petal.len。
我说的对吗?
没错,萨尔曼!
如何像您关于分类问题的 XGBClassifier 教程一样,使用 XGBRegressor 执行特征重要性和选择?
你好 Bilash…你可能会发现以下内容很有趣
https://machinelearning.org.cn/feature-importance-and-feature-selection-with-xgboost-in-python/
嗨,@James!
首先,非常感谢您的始终专注的文章,它们对我们非常有用!
我想就生存时间分析领域的特征选择技术寻求一些建议,我有数百个特征,需要减少它们。
非常感谢!