特征选择 是识别和选择最与目标变量相关的输入特征子集的过程。
在处理实值数据时,特征选择通常很简单,例如使用皮尔逊相关系数,但在处理分类数据时可能会很困难。
当输入数据是分类数据,目标变量也是分类数据(例如分类预测建模)时,最常用的两种特征选择方法是卡方统计量和互信息统计量。
在本教程中,您将了解如何执行分类输入数据的特征选择。
完成本教程后,您将了解:
- 具有分类输入和二元分类目标变量的乳腺癌预测建模问题。
- 如何使用卡方和互信息统计量评估分类特征的重要性。
- 在拟合和评估分类模型时,如何为分类数据执行特征选择。
开始您的项目,阅读我的新书《机器学习数据准备》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。

如何对分类数据执行特征选择
照片由 Phil Dolby 拍摄,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 乳腺癌分类数据集
- 分类特征选择
- 卡方特征选择
- 互信息特征选择
- 使用选定特征进行建模
- 使用所有特征构建的模型
- 使用卡方特征构建的模型
- 使用互信息特征构建的模型
乳腺癌分类数据集
作为本教程的基础,我们将使用自20世纪80年代以来被广泛研究的所谓“乳腺癌”数据集。
该数据集将乳腺癌患者数据分类为复发或未复发。共有286个样本和9个输入变量。这是一个二元分类问题。
朴素模型在此数据集上的准确率可达70%。一个好的分数大约是76% +/- 3%。我们将以这个范围为目标,但请注意,本教程中的模型并未优化;它们旨在演示编码方案。
您可以下载数据集,并将文件保存为当前工作目录中的“breast-cancer.csv”。
查看数据,我们可以看到所有九个输入变量都是分类变量。
具体来说,所有变量都是带引号的字符串;有些是顺序的,有些则不是。
|
1 2 3 4 5 6 |
'40-49','premeno','15-19','0-2','yes','3','right','left_up','no','recurrence-events' '50-59','ge40','15-19','0-2','no','1','right','central','no','no-recurrence-events' '50-59','ge40','35-39','0-2','no','2','left','left_low','no','recurrence-events' '40-49','premeno','35-39','0-2','yes','3','right','left_low','yes','no-recurrence-events' '40-49','premeno','30-34','3-5','yes','2','left','right_up','no','recurrence-events' ... |
我们可以使用 Pandas 库将此数据集加载到内存中。
|
1 2 3 4 5 |
... # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索 numpy 数组 dataset = data.values |
加载后,我们可以将列分为输入(X)和输出以供建模。
|
1 2 3 4 |
... # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] |
最后,我们可以将输入数据中的所有字段强制转换为字符串,以防Pandas自动将其映射为数字(它确实会尝试)。
|
1 2 3 |
... # 将所有字段格式化为字符串 X = X.astype(str) |
我们可以将所有这些内容整合到一个有用的函数中,以便以后重复使用。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) return X, y |
加载后,我们可以将数据分割成训练集和测试集,以便拟合和评估学习模型。
我们将使用 scikit-learn 的 train_test_split() 函数,使用 67% 的数据进行训练,33% 的数据进行测试。
|
1 2 3 4 5 |
... # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) |
将所有这些元素结合起来,加载、分割和汇总原始分类数据集的完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 加载并汇总数据集 from pandas import read_csv from sklearn.model_selection import train_test_split # 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) 返回 X, y # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 总结 print('Train', X_train.shape, y_train.shape) print('Test', X_test.shape, y_test.shape) |
运行示例报告了训练集和测试集的输入和输出元素的尺寸。
我们可以看到,我们有 191 个样本用于训练,95 个样本用于测试。
|
1 2 |
训练 (191, 9) (191, 1) 测试 (95, 9) (95, 1) |
现在我们熟悉了数据集,接下来看看如何将其编码以进行建模。
我们可以使用 scikit-learn 的 OrdinalEncoder() 来将每个变量编码为整数。这是一个灵活的类,如果已知任何类别的顺序,它允许指定类别顺序作为参数。
注意:我将把更新下面的示例的任务留给您,尝试为那些具有自然顺序的变量指定顺序,看看它是否会对模型性能产生影响。
编码变量的最佳实践是,在训练数据集上拟合编码,然后将其应用于训练集和测试集。
下面的名为 prepare_inputs() 的函数接受训练集和测试集的输入数据,并使用序数编码进行编码。
|
1 2 3 4 5 6 7 |
# 准备输入数据 def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc |
我们还需要准备目标变量。
这是一个二元分类问题,因此我们需要将两个类标签映射为 0 和 1。这是一种序数编码,scikit-learn 提供了专门为此目的设计的 LabelEncoder 类。我们也可以使用 OrdinalEncoder 并获得相同的结果,尽管 LabelEncoder 是为编码单个变量而设计的。
prepare_targets() 函数对训练集和测试集的输出数据进行整数编码。
|
1 2 3 4 5 6 7 |
# 准备目标 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc |
我们可以调用这些函数来准备我们的数据。
|
1 2 3 4 5 |
... # 准备输入数据 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # 准备输出数据 y_train_enc, y_test_enc = prepare_targets(y_train, y_test) |
将所有内容整合在一起,加载和编码乳腺癌分类数据集的输入和输出变量的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 加载和准备乳腺癌数据集的示例 from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder # 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) 返回 X, y # 准备输入数据 def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # 准备目标 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 准备输入数据 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # 准备输出数据 y_train_enc, y_test_enc = prepare_targets(y_train, y_test) |
现在我们已经加载并准备好了乳腺癌数据集,我们可以开始探索特征选择。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
分类特征选择
对于分类输入数据和分类(类别)目标变量,有两种流行的特征选择技术可以用来进行特征选择。
它们是
- 卡方统计量。
- 互信息统计量。
让我们依次仔细看看每一个。
卡方特征选择
皮尔逊卡方统计假设检验是衡量分类变量之间独立性的一种方法。
您可以在教程中了解更多关于这种统计检验的信息
此检验的结果可用于特征选择,其中与目标变量无关的特征可以从数据集中删除。
当预测变量有三个或更多级别时,可以使用 X2(卡方)检验等统计量来衡量预测变量和结果之间的关联程度……
— 第 242 页,《特征工程与选择》,2019。
scikit-learn 机器学习库在 chi2() 函数中提供了卡方检验的实现。此函数可用于特征选择策略,例如通过 SelectKBest 类选择 k 个最相关特征。
例如,我们可以定义 SelectKBest 类来使用 chi2() 函数并选择所有特征,然后转换训练集和测试集。
|
1 2 3 4 5 |
... fs = SelectKBest(score_func=chi2, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) |
然后,我们可以打印每个变量的分数(分数越高越好),并将每个变量的分数绘制成条形图,以了解应该选择多少特征。
|
1 2 3 4 5 6 7 |
... # 特征得分是多少 for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # 绘制分数 pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show() |
将上文中的乳腺癌数据集的数据准备与此结合,完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# 分类数据卡方特征选择示例 from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import chi2 from matplotlib import pyplot # 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) 返回 X, y # 准备输入数据 def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # 准备目标 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 特征选择 def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=chi2, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 准备输入数据 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # 准备输出数据 y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train_enc, y_train_enc, X_test_enc) # 特征得分是多少 for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # 绘制分数 pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show() |
运行该示例首先打印为每个输入特征和目标变量计算的分数。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到分数很小,仅从数字上很难判断哪些特征更相关。
也许特征 3、4、5 和 8 最相关。
|
1 2 3 4 5 6 7 8 9 |
特征 0: 0.472553 特征 1: 0.029193 特征 2: 2.137658 特征 3: 29.381059 特征 4: 8.222601 特征 5: 8.100183 特征 6: 1.273822 特征 7: 0.950682 特征 8: 3.699989 |
创建了一个显示每个输入特征的特征重要性分数的条形图。
这清楚地表明,根据卡方检验,特征 3 可能是最相关的,并且九个输入特征中的四个是最相关的。
我们可以在配置 SelectKBest 时将 k 设置为 4 来选择这四个最重要的特征。
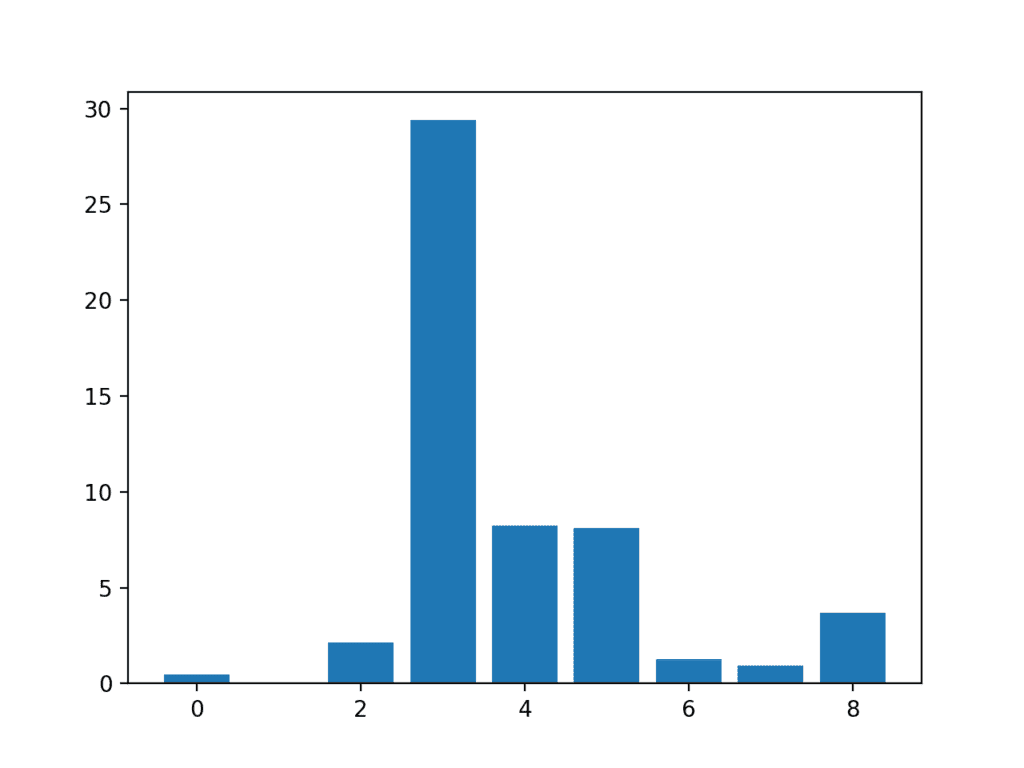
输入特征 (x) 与卡方特征重要性 (y) 的条形图
互信息特征选择
信息论领域的互信息是信息增益(通常用于决策树的构建)在特征选择中的应用。
互信息在两个变量之间计算,并衡量给定另一个变量已知值时,一个变量不确定性的减少量。
您可以在以下教程中了解更多关于互信息的信息。
scikit-learn 机器学习库通过 mutual_info_classif() 函数提供了互信息的实现,用于特征选择。
与 chi2() 一样,它可以用于 SelectKBest 特征选择策略(和其他策略)。
|
1 2 3 4 5 6 7 |
# 特征选择 def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs |
我们可以使用互信息对乳腺癌数据集执行特征选择,并打印和绘制分数(分数越高越好),就像我们在上一节中所做的那样。
用于分类数据互信息特征选择的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# 分类数据互信息特征选择示例 from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_classif from matplotlib import pyplot # 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) 返回 X, y # 准备输入数据 def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # 准备目标 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 特征选择 def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k='all') fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs, fs # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 准备输入数据 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # 准备输出数据 y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # 特征选择 X_train_fs, X_test_fs, fs = select_features(X_train_enc, y_train_enc, X_test_enc) # 特征得分是多少 for i in range(len(fs.scores_)): print('Feature %d: %f' % (i, fs.scores_[i])) # 绘制分数 pyplot.bar([i for i in range(len(fs.scores_))], fs.scores_) pyplot.show() |
运行该示例首先打印为每个输入特征和目标变量计算的分数。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到一些特征的分数非常低,这表明它们可能可以被删除。
也许特征 3、6、2 和 5 最相关。
|
1 2 3 4 5 6 7 8 9 |
特征 0: 0.003588 特征 1: 0.000000 特征 2: 0.025934 特征 3: 0.071461 特征 4: 0.000000 特征 5: 0.038973 特征 6: 0.064759 特征 7: 0.003068 特征 8: 0.000000 |
创建了一个显示每个输入特征的特征重要性分数的条形图。
重要的是,推广了不同的特征组合。
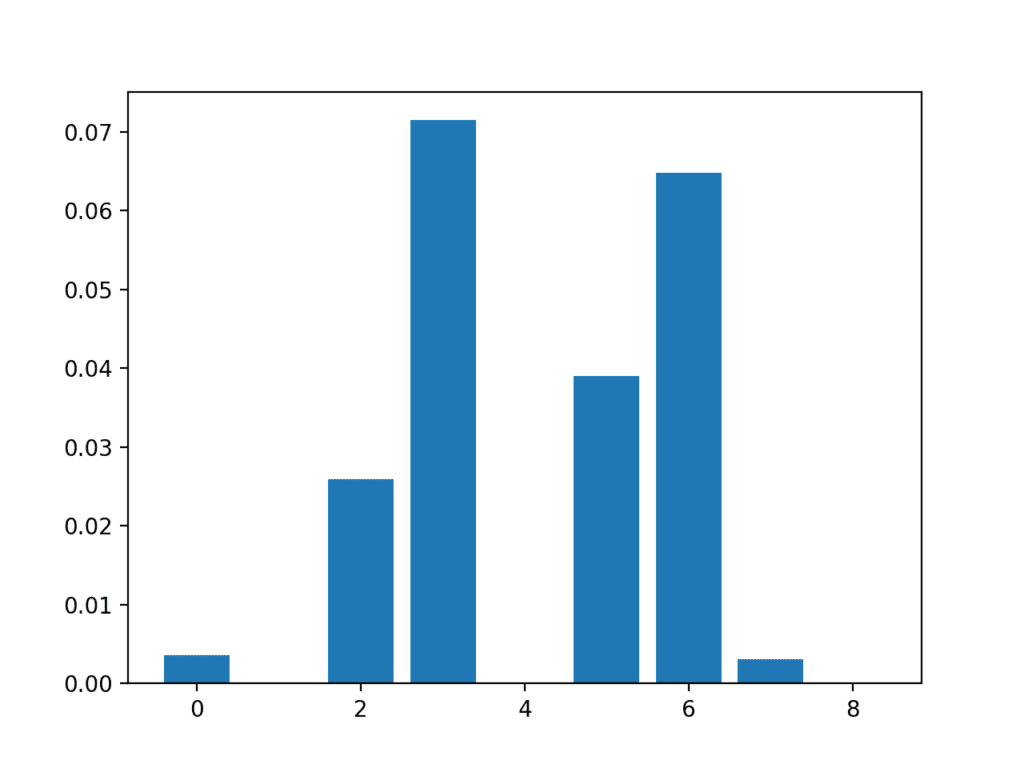
输入特征 (x) 与互信息特征重要性 (y) 的条形图
现在我们知道如何为分类预测建模问题执行分类数据的特征选择,我们可以尝试使用选定的特征来开发模型并比较结果。
使用选定特征进行建模
有许多不同的技术可以用于特征评分和基于分数选择特征;您如何知道应该使用哪一种?
一种稳健的方法是使用不同的特征选择方法(和特征数量)评估模型,并选择能够产生最佳性能模型的方法。
在本节中,我们将评估一个逻辑回归模型,该模型使用所有特征,并与使用卡方选择的特征和使用互信息选择的特征构建的模型进行比较。
逻辑回归是测试特征选择方法的良好模型,因为如果从模型中删除了不相关的特征,它可以表现得更好。
使用所有特征构建的模型
首先,我们将评估一个 LogisticRegression 模型,该模型使用所有可用特征。
该模型在训练数据集上进行拟合,并在测试数据集上进行评估。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# 使用所有输入特征评估模型 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) 返回 X, y # 准备输入数据 def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # 准备目标 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 准备输入数据 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # 准备输出数据 y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # 拟合模型 model = LogisticRegression(solver='lbfgs') model.fit(X_train_enc, y_train_enc) # 评估模型 yhat = model.predict(X_test_enc) # 评估预测 accuracy = accuracy_score(y_test_enc, yhat) print('Accuracy: %.2f' % (accuracy*100)) |
运行示例将打印模型在训练数据集上的准确率。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型实现了大约 75% 的分类准确率。
我们希望使用能达到与此相同或更好分类准确率的特征子集。
|
1 |
准确率: 75.79 |
使用卡方特征构建的模型
我们可以使用卡方检验来为特征评分,并选择四个最相关的特征。
下面的 select_features() 函数已更新以实现此目的。
|
1 2 3 4 5 6 7 |
# 特征选择 def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=chi2, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs |
使用此特征选择方法拟合和评估逻辑回归模型的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# 使用卡方输入特征拟合模型的评估 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import chi2 from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) 返回 X, y # 准备输入数据 def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # 准备目标 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 特征选择 def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=chi2, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 准备输入数据 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # 准备输出数据 y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # 特征选择 X_train_fs, X_test_fs = select_features(X_train_enc, y_train_enc, X_test_enc) # 拟合模型 model = LogisticRegression(solver='lbfgs') model.fit(X_train_fs, y_train_enc) # 评估模型 yhat = model.predict(X_test_fs) # 评估预测 accuracy = accuracy_score(y_test_enc, yhat) print('Accuracy: %.2f' % (accuracy*100)) |
运行示例报告了模型在仅使用卡方统计量选择的九个输入特征中的四个上的性能。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们发现模型取得了约 74% 的准确率,性能略有下降。
有可能一些被移除的特征实际上是通过它们自身或与选定特征结合来增加价值的。
在这个阶段,我们可能更倾向于使用所有输入特征。
|
1 |
准确率: 74.74 |
使用互信息特征构建的模型
我们可以重复实验,并使用互信息统计量选择最重要的四个特征。
下面列出了更新后的 *select_features()* 函数以实现此目的。
|
1 2 3 4 5 6 7 |
# 特征选择 def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs |
使用互信息为逻辑回归模型拟合的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# 使用互信息输入特征拟合模型的评估 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OrdinalEncoder 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_classif from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 加载数据集 def load_dataset(filename): # 将数据集加载为 pandas DataFrame data = read_csv(filename, header=None) # 检索numpy数组 dataset = data.values # 分割为输入 (X) 和输出 (y) 变量 X = dataset[:, :-1] y = dataset[:,-1] # 将所有字段格式化为字符串 X = X.astype(str) 返回 X, y # 准备输入数据 def prepare_inputs(X_train, X_test): oe = OrdinalEncoder() oe.fit(X_train) X_train_enc = oe.transform(X_train) X_test_enc = oe.transform(X_test) return X_train_enc, X_test_enc # 准备目标 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 特征选择 def select_features(X_train, y_train, X_test): fs = SelectKBest(score_func=mutual_info_classif, k=4) fs.fit(X_train, y_train) X_train_fs = fs.transform(X_train) X_test_fs = fs.transform(X_test) return X_train_fs, X_test_fs # 加载数据集 X, y = load_dataset('breast-cancer.csv') # 拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # 准备输入数据 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # 准备输出数据 y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # 特征选择 X_train_fs, X_test_fs = select_features(X_train_enc, y_train_enc, X_test_enc) # 拟合模型 model = LogisticRegression(solver='lbfgs') model.fit(X_train_fs, y_train_enc) # 评估模型 yhat = model.predict(X_test_fs) # 评估预测 accuracy = accuracy_score(y_test_enc, yhat) print('Accuracy: %.2f' % (accuracy*100)) |
运行示例将模型拟合到使用互信息选择的前四个最佳特征。
注意:您的结果可能因算法或评估程序的随机性,或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到分类准确率略有提升至 76%。
为确保效果真实有效,最好多次重复每项实验并比较平均性能。还可以考虑使用 k 折交叉验证来代替简单的训练/测试分割。
|
1 |
准确率:76.84 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
书籍
- 特征工程与选择, 2019.
API
- sklearn.model_selection.train_test_split API.
- sklearn.preprocessing.OrdinalEncoder API.
- sklearn.preprocessing.LabelEncoder API.
- sklearn.feature_selection.chi2 API
- sklearn.feature_selection.SelectKBest API
- sklearn.feature_selection.mutual_info_classif API.
- sklearn.linear_model.LogisticRegression API.
文章
总结
在本教程中,您了解了如何对分类输入数据执行特征选择。
具体来说,你学到了:
- 具有分类输入和二元分类目标变量的乳腺癌预测建模问题。
- 如何使用卡方和互信息统计量评估分类特征的重要性。
- 在拟合和评估分类模型时,如何为分类数据执行特征选择。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。





 for Feature Selection in Python")

嗨,Jason,
我已经对数据列进行了特征选择(在清理数据之后)。我使用的方法是用于特征选择的 Extra Tree Classifier(来自 sklearn.ensemble)。
我拟合了模型并获得了数据中最相关的 n 个特征。但是,每次运行它时,出现的最重要的特征都不同。我不确定这是为什么,难道该方法不应该总是输出相同的 n 个顶级特征吗?
感谢您的建议!
也许模型选择的方差太大了。
也许可以尝试另一种方差较小的模型或模型配置?
也许可以尝试“平均”评估策略,而不是单次运行?
也许可以将平均方法与 RFE 或卡方等其他不太随机的方法进行比较?
你好 Alan,
事实上,问题比你描述的更广泛,因为除了 sklearn 中 ExtraTrees 或 RandomForest 的默认基尼重要性之外,还存在不同的变量重要性方法。
我想到的是置换重要性和 dropcol 重要性。而这些方法中的每一种都可以提供不同的变量排名。
根据我的经验,我应用了多次置换重要性评估(例如 5 次),然后在比较变量之前取平均值。
此致!
非常有帮助!谢谢!
谢谢,很高兴听到这个!
为什么这两种方法给出的特征重要性值完全不同?
也许特征编号不匹配?
没有“重要性”的真实答案,只有不同的“想法”或方法。
尝试一套方法,拟合模型,看看哪个特征子集能产生最有技能的模型
https://machinelearning.org.cn/faq/single-faq/what-feature-selection-method-should-i-use
Jason
我是您博客文章的忠实读者。我想提请您注意我开发的一个名为 Auto_ViML 的新库,该库使用许多出色的 Kaggle 技术自动执行特征选择和模型调优。我想让您在 breast-cancer.csv 文件上试用它,并报告结果(如果您可以的话)。
这是描述它的 Medium 文章
https://towardsdatascience.com/why-automl-is-an-essential-new-tool-for-data-scientists-2d9ab4e25e46?gi=7814502b6fb8
请尝试一下,然后告诉我。谢谢。
谢谢您的留言。
感谢您发表这篇有插图代码演示的精彩博文。
我对卡方特征选择有问题
变量的重要性(得分)和卡方得分是同一回事,还是方向相反的不同事物?
我感到困惑的原因是我下面的理解(误解?)。卡方检验的零假设是两个输入具有相似的分布(即相关或依赖)。因此,更高的卡方得分意味着依赖性更低。为了进行特征选择,我们希望使用与目标变量相关的变量进行预测。或者在您的文本中,“可以从数据集中移除与目标变量独立的特征”。
我的理解是,卡方得分较高的变量应该被移除,因为它们与目标变量无关。因此,我认为变量的重要性与原始卡方得分成反比。
好问题。
不,卡方的零假设(h0)是它们是独立的。得分越高意味着依赖性越强。
有关卡方如何工作的详细信息,请参阅此文
https://machinelearning.org.cn/chi-squared-test-for-machine-learning/
还有这个。
https://machinelearning.org.cn/statistical-hypothesis-tests-in-python-cheat-sheet/
你好 Jason,
我有一个问题。
正则化方法可以提高准确率并减少过拟合,还是仅仅为了提高准确率?
谢谢
正则化降低了复杂性,这通常会减少过拟合和泛化误差。
你好 Jason,
还有一个问题是使用 sklearn 的 Precision, Recall, F1 指标以及 ROC/AUC 来评估 Keras 模型。
您使用上述指标来评估 Keras 模型是否正确?
Keras 是否提供任何其他函数来评估模型?
谢谢
这里有一个例子
https://machinelearning.org.cn/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
你好 Jason,
感谢分享这篇有趣的博文!
不客气!
嗨 Jason,我有一个问题。
我曾在某处读到,我们应该对那些具有两个以上类别的分类特征使用哑变量(使用独热编码)。但是在此逻辑回归模型中,您没有这样做,这让我对何时应使用哑变量以及何时不需要感到困惑。
请帮忙。
因为测试问题有两个类别。
但是有很多特征有超过 2 个类别。(例如,breast-quad 有 5 个类别:left-up, left-low, right-up, right-low, central)。
那么我的问题是,我们是否应该对这样的列使用哑变量,或者不使用。
它们是输入变量。
类别是输出变量。有一个类别,它有两个值。
我认为他的问题是为什么可以使用 OrdinalEncoder 对这 5 个类别进行编码而不是 OHE,因为它们的关系是相等的,但 OE 没有显示这种属性。
嗨 James……感谢您的反馈!
很棒的教程!如果您有多标签,您需要对每个目标进行“一对多”二值化,对吧?然后按分数附加所有内容并排序。谢谢
我正在使用相同的代码,在尝试使用 ordinalencoder 对我的输入进行编码时,它在此错误处卡住了:“输入包含 NaN、无穷大或对于 dtype(‘float64’) 来说过大的值。” 您能建议如何解决这个问题吗??
我这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
在进行特征选择之前进行特征缩放是否可取?并且是否可以在独热编码之后进行特征选择(例如使用 get_dummies 函数)?我有多个具有许多类别的列,当我进行独热编码时,会产生大约 13 个额外的列,那么我应该在标签编码之后进行特征选择,还是可以在独热编码之后进行?您会推荐什么?
很好的问题!
我想这取决于正在使用的特征选择方法。
对独热编码列进行特征选择可能不是一个好主意。
Jason,感谢您的回答。在这种情况下,我们应该如何处理这些独热编码的列?使用系数的特征重要性是否仍然有效?
如上面的教程所示,请尝试对序数编码的变量进行特征选择。
最佳实践是对名义特征进行序数编码以进行特征选择。
我理解得对吗?
嗨 Sonicsun23……以下资源可能很有趣,并有助于阐明最佳实践
https://machinelearning.org.cn/one-hot-encoding-for-categorical-data/
https://machinelearning.org.cn/framework-for-data-preparation-for-machine-learning/
你能建议如何对独热编码的列进行特征选择吗
嗨 Edwin……对独热编码列进行特征选择可能有点棘手,但确保模型不会被无关或冗余的特征淹没至关重要。以下是一些对独热编码列执行特征选择的常用方法
### 1. **移除低方差特征**
– 一种简单的方法是移除在数据集中方差很小或为零的特征。这意味着,如果一个特定的独热编码列对于大多数数据点具有相同的值(主要是 0),它可能对模型贡献不大。
– 在 Python 中,您可以使用 `sklearn.feature_selection` 中的 `VarianceThreshold` 来移除低方差特征
pythonfrom sklearn.feature_selection import VarianceThreshold
# 假设 X 是您的特征矩阵
selector = VarianceThreshold(threshold=0.01) # 您可以根据需要调整阈值
X_reduced = selector.fit_transform(X)
### 2. **基于相关性的特征选择**
– 独热编码后,您可能会得到高度相关的特征。您可以计算相关矩阵并移除两个高度相关的特征中的一个(例如,大于 0.8 或 0.9)。
– 这是在 Python 中执行此操作的方法
pythonimport pandas as pd
# 假设 df 是您带有独热编码特征的 DataFrame
corr_matrix = df.corr().abs()
# 选择相关矩阵的上三角部分
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool_))
# 查找相关性大于阈值的特征
to_drop = [column for column in upper.columns if any(upper[column] > 0.8)]
# 删除相关特征
df_reduced = df.drop(to_drop, axis=1)
### 3. **卡方检验用于分类特征**
– 卡方检验可以通过测量特征与目标变量之间的依赖性来帮助您选择最相关的独热编码特征。
– 这是实现它的方法
pythonfrom sklearn.feature_selection import SelectKBest, chi2
# 假设 X 是您的独热编码特征矩阵,y 是目标变量
selector = SelectKBest(chi2, k=10) # 选择前 10 个特征
X_new = selector.fit_transform(X, y)
# 获取选定的特征
selected_features = selector.get_support(indices=True)
### 4. **基于树的方法**
– 像随机森林或梯度提升这样的基于树的模型可以提供特征重要性分数,这些分数可用于选择最重要的特征,即使它们是独热编码的。
– 使用随机森林的示例
pythonfrom sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
model = RandomForestClassifier(n_estimators=100)
model.fit(X, y)
# 根据重要性选择特征
selector = SelectFromModel(model, prefit=True)
X_reduced = selector.transform(X)
### 5. **递归特征消除 (RFE)**
– RFE 通过递归地考虑越来越小的特征集来工作。它通过递归地考虑越来越小的特征集来选择特征。
– 示例
pythonfrom sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
X_rfe = rfe.fit_transform(X, y)
### 6. **主成分分析 (PCA)**
– 尽管 PCA 不是专门针对独热编码特征的,但它可以通过将特征转换为一组线性不相关的分量来减少维度。
– 示例
pythonfrom sklearn.decomposition import PCA
pca = PCA(n_components=10)
X_pca = pca.fit_transform(X)
### 7. **互信息**
– 互信息可用于衡量变量之间的依赖性。互信息越高表示依赖性越高,这有助于选择重要特征。
– 示例
pythonfrom sklearn.feature_selection import mutual_info_classif, SelectKBest
mi = mutual_info_classif(X, y)
selector = SelectKBest(mutual_info_classif, k=10)
X_new = selector.fit_transform(X, y)
### 8. **L1 正则化 (Lasso)**
– L1 正则化还可以通过将某些系数收缩为零来帮助进行特征选择,从而有效地进行特征选择。
– 示例
pythonfrom sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import SelectFromModel
model = LogisticRegression(C=1.0, penalty='l1', solver='liblinear')
model.fit(X, y)
selector = SelectFromModel(model, prefit=True)
X_new = selector.transform(X)
这些方法应该能帮助您从独热编码的列中选择最相关的特征。方法的选择取决于数据集的具体特征以及您要解决的问题。
Jason,您提供的博客一如既往地出色。
但是,我想知道您是否可以帮助我。我加载并准备了自己的数据集,使用了您的示例代码,而不是使用乳腺癌数据。我的数据有 5 个分类变量和一个输出变量,该变量是二元的
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OrdinalEncoder
def load_dataset(filename)
# 将数据集加载为 pandas DataFrame
data = read_csv(filename, header=None)
# 检索 numpy 数组
dataset = data.values
# 分割为输入 (X) 和输出 (y) 变量
X = dataset[:, :-1]
y = dataset[:,-1]
# 将所有字段格式化为字符串
X = X.astype(str)
return X, y
# 准备输入数据
def prepare_inputs(X_train, X_test)
oe = OrdinalEncoder()
oe.fit(X_train)
X_train_enc = oe.transform(X_train)
X_test_enc = oe.transform(X_test)
return X_train_enc, X_test_enc
# 准备目标
def prepare_target(y_train, y_test)
le = LabelEncoder()
le.fit(y_train)
y_train_enc = le.transform(y_train)
y_test_enc = le.transform(y_test)
return y_train_enc, y_test_enc
# 分割数据
# 加载数据集
X, y = load_dataset(‘…..cat_tester.csv’)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
# 准备输入数据
X_train_enc, X_test_enc = prepare_inputs(X_train, X_test)
# 准备输出数据
y_train_enc, y_test_enc = prepare_target(y_train, y_test)
我的问题是它返回的错误,这似乎等同于测试数据的标签数量,但我很难找出问题所在
ValueError 回溯 (最近一次调用)
in ()
37 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
38 # 准备输入数据
—> 39 X_train_enc, X_test_enc = prepare_inputs(X_train, X_test)
40 # 准备输出数据
41 y_train_enc, y_test_enc = prepare_target(y_train, y_test)
在 prepare_inputs(X_train, X_test)
21 oe.fit(X_train)
22 X_train_enc = oe.transform(X_train)
—> 23 X_test_enc = oe.transform(X_test)
24 return X_train_enc, X_test_enc
25
~/anaconda3/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py in transform(self, X)
955
956 “””
–> 957 X_int, _ = self._transform(X)
958 return X_int.astype(self.dtype, copy=False)
959
~/anaconda3/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py in _transform(self, X, handle_unknown)
120 msg = (“Found unknown categories {0} in column {1}”
121 ” during transform”.format(diff, i))
–> 122 raise ValueError(msg)
123 else
124 # Set the problematic rows to an acceptable value and
ValueError: Found unknown categories [‘Above The Rest (IRE)’, ‘Adventureman’, ‘Alba Del Sole (IRE)’, ‘Alfa McGuire (IRE)’, ‘Autretot (FR)’, ‘Axe Axelrod (USA)’, ‘Bartholomeu Dias’, ‘Bedouins Story’, ‘Bird For Life’, ‘Brian The Snail (IRE)’, ‘Canford Heights (IRE)’, ‘Chaplin Bay (IRE)’, ‘Cosmelli (ITY)’, ‘Deebaj (IRE)’, ‘Deeds Not Words (IRE)’, ‘Delilah Park’, ‘Elixsoft (IRE)’, ‘Epona’, ‘Fairy Stories’, ‘Falathaat (USA)’, ‘First Flight (IRE)’, ‘Fool For You (IRE)’, ‘Fronsac’, ‘Full Strength’, ‘Glance’, ‘Gometra Ginty (IRE)’, ‘Houlton’, ‘Hour Of The Dawn (IRE)’, ‘Hurcle (IRE)’, ‘Im Dapper Too’, ‘Irish Charm (FR)’, ‘Jellmood’, ‘Kodiac Lass (IRE)’, ‘Laugh A Minute’, ‘Local History’, ‘London Eye (USA)’, ‘Looking For Carl’, ‘Lucky Lodge’, ‘Military Law’, ‘Moonraker’, ‘Mrs Bouquet’, ‘Mutabaahy (IRE)’, ‘Newmarket Warrior (IRE)’, ‘Nyaleti (IRE)’, ‘Oh Its Saucepot’, ‘Orsino (IRE)’, ‘Paparazzi’, ‘Que Amoro (IRE)’, ‘Raydiance’, ‘Red Galileo’, ‘Regal Banner’, ‘Roman De Brut (IRE)’, ‘Seniority’, ‘Sense of Belonging (FR)’, ‘Shark (FR)’, ‘Sonnet Rose (IRE)’, ‘Speedo Boy (FR)’, ‘Stratum’, ‘Tarboosh’, ‘The Fiddler’, ‘Theglasgowwarrior’, ‘Time Change’, ‘Trevithick’, ‘Trickydickysimpson’, ‘Vale Of Kent (IRE)’, ‘Windsor Cross (IRE)’, ‘Woven’, ‘Youre My Rock’] in column 0 during transform
你能提供任何建议吗。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
您的分类变量基数很高(也就是说,有太多不同的条目)。其中一些在训练集中未被看到,因此您的模型在测试集中看到它时无法识别它。决定该变量是否真正必要。您需要简化它。希望这有帮助。
当我尝试使用 OrdinalEncoder 从我的数据集中转换 X_test 时,我收到一个错误。这很奇怪,因为它在没有问题的情况下转换了我的 X_train 数据
14 X_train_enc = oe.transform(X_train)
—> 15 X_test_enc = oe.transform(X_test)
ValueError: Found unknown categories [‘1733′, ’56’] in column 0 during transform
如果测试集中的值在训练集中未出现,则可能会发生这种情况。
您可以修改训练集以包含所有可能情况的示例。
或创建所有已知情况到整数的自定义映射。
嗨!我也遇到了同样的问题。您能弄清楚吗?
嗨 Jason
我看了您的文章,它们是很好的信息来源,对初学者非常有帮助。非常感谢您分享知识。
愿上帝保佑你。
谢谢!
如何多次在训练数据上训练最终模型。然后多次获取最终模型在测试集上的性能。
predictions = None
testing_accuracies = []
for k in range(1, 10)
result = cross_val_score(parent_model, X_resampled, y_resampled, cv=k,
scoring=’accuracy’)
print(k, result.mean())
predictions = cross_val_predict(parent_model, X_test, y_test, cv=k)
print(predictions)
test_accuracy = metrics.accuracy_score(y_test, predictions)
testing_accuracies.append(test_accuracy)
print(“Test Accuracy – for iteration :”, test_accuracy)
# 获取平均测试分数
sum = 0
for i in range(len(testing_accuracies))
score = testing_accuracies[i]
sum += score
avg_test_score = sum / len(testing_accuracies)
print(“Mean Region: Test score “, avg_test_score)
我尝试了这段代码,但它似乎没有给出我想要的结果。我想要的是:
1. 多次在训练数据集上训练最终模型,因为它是一个小型数据集。
2. 然后将该模型用于测试数据。
3. 然后重复进行预测并获取最终模型的平均测试准确率。
为此,我是否可以使用 2 个循环?或者有没有办法使用交叉验证来执行此操作?
谢谢
San
抱歉,我没明白。
我们使用重采样程序来评估模型。只有一个最终模型,或者是一个最终模型的集合。
也许看看这个
https://machinelearning.org.cn/train-final-machine-learning-model/
您提到 OrdinalEncoder 允许您指定变量的顺序,这是因为实际上我们只能在分类变量可以有任何有意义的排序并且考虑到变量指的是什么和手头的研究时使用此函数,对吗?但实际上您让算法自己选择它,我猜是随机的。这样做是否正确?您对如何处理无法排序的分类变量有何建议?谢谢,并请原谅我的英语不好。
可能不行,正如我在教程中所述。
如果该变量是序数的,最好使用序数编码器来表示它。
关于使用 chi-2 和 multi info 方法的特征选择部分,如果我有一个特征的独热编码或多热编码怎么办?也就是说,我们有一个三维的 train_X。
很好的问题。
选择是在编码之前进行的。
你好,
感谢您的博客。
我在几篇文章中读到 LabelEncoder 有一个排序问题(1<2<3<4..)
但是,如果我仅对目标标签使用 LabelEncoder 进行编码,是否存在此排序问题?(假设我有 5 个标签)
很好的问题!
通常不会,因为标准算法的良好实现知道这种表示。
给定算法的朴素实现可能会出现此问题。
嗨,Jason,这是一篇很棒的文章!
我只是想问一下,对所有特征进行序数编码,包括那些不是序数的特征(如“breast-quad”)是否合适?就像我们在应用任何机器学习模型之前对非序数特征进行独热编码一样,这里我们应该做什么?
可能不合适,但还是试试吧。有时打破规则也能取得好结果。
你好,
我的目标有 3 个类别。我应该将它们变成 3 个二元变量,然后分别对每个二元变量执行 Chi-squared 和 Mutual Information 方法吗?我在某个地方读到卡方适合分类变量和二元目标(不是标签)。
不,最好对标签进行序数编码,然后尝试统计检验。
嗨。我已按照“卡方特征选择”的所有步骤处理了我的数据集,并且运行良好,没有问题。
我的问题是,在打印结果时,我能否获取原始特征名称?例如“特征 *名称*: 值?”
如果没有,还有其他方法可以找出值对应于哪个特征吗?
感谢你的出色工作。
干得好!
是的,列出所选特征的部分会显示特征编号或列索引。如果您有一个字符串形式的列名列表,您可以使用这些索引直接打印名称。
如果这是个新手问题,请原谅我,但我一直在想,对于包含分类和数值变量混合的数据集,
我们能否将数据分成
– ds1(包含数值和目标变量)
– ds2(包含分类和目标变量)
然后将 fclassif 应用于 ds1,将 chisquare 应用于 ds2?
感谢您的这篇文章!
是的,您可以使用不关心数据类型的 rfe。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
或者使用 columntransformer 按类型拆分并单独选择。
https://machinelearning.org.cn/columntransformer-for-numerical-and-categorical-data/
为什么互信息特征选择需要很长时间来计算?极其缓慢?
它将每个观测值视为来自某个分布的事件。如果您拥有的事件(唯一值)较少,它会更快。
我有一个关于分类问题的特征选择问题,其中输入特征是名义上的分类变量,输出是分类变量。
对于卡方特征选择,强制使用 OrdinalEncoder() 将名义上的分类变量转换为有序变量是否有影响?SelectKbest 内部会构建一个列联表,计算卡方统计量,然后对变量进行排序。用户可以选择前 K 个。我的问题仅与特征选择有关。我知道强行将名义变量转换为有序变量,根据所使用的机器学习模型,可能会导致模型效果不佳。
为了让我的问题更具体,请考虑一个具有两个特征和二元目标变量(“购买”和“未购买”)的示例问题。两个特征是产品的颜色和形状。目标变量告诉客户是否购买了该产品。颜色有三个级别(红色、绿色、蓝色),形状有三个级别(圆形、三角形、方形)。显然,这两个特征都是名义上的。如果使用 OrdinalEncoder,则(例如,红色=0、绿色=1、蓝色=2)和(圆形=0、三角形=1、方形=2)。分别运行卡方检验以查找(颜色、目标)和(形状、目标)之间的依赖性。即使顺序是人为的,我也看不出检验有问题。请给出您的评论。
其次,为什么不使用(每个级别、目标)之间的卡方检验?上述检验要么接受要么拒绝每个变量。假设卡方检验表明(颜色、目标)是相关的,而
(形状、目标)是不相关的。这会导致丢弃形状变量作为预测变量。这种设置无法告知哪个变量的哪个级别导致了相关性/不相关性。因此,一般来说,为什么不将每个变量转换为独热编码向量,然后进行成对卡方检验(特定变量的特定级别,目标)。然后,也许几个级别会被拒绝,我们最终得到一个缩减的数据集,例如(示例中),
(红色、绿色、三角形、目标)。
预测变量的列数从 6 减少到 3。请给出您的宝贵意见。谢谢。
是的,强制分类变量为有序变量可能会产生影响。
也许可以尝试上面列出的几种方法,看看哪种方法能为您的数据集提供最佳性能的模型。
我不明白为什么得分高就意味着它很重要。我们怎么知道这些得分是否大于临界值,从而存在关系(不独立)?
这是我们需要稍后检查的东西吗?
这或许有助于更普遍地理解假设检验中的临界值
https://machinelearning.org.cn/critical-values-for-statistical-hypothesis-testing/
非常感谢您的精彩教程,Brownlee 博士。
如果我们的目标是进行降维,MCA 在这种情况下是否是更有效的解决方案?另外,使用 MCA 与特征选择的优缺点是什么?
非常感谢您的回复。
MCA 是什么?
抱歉没有使用全名,多元对应分析 (MCA):https://github.com/MaxHalford/prince。从目的上讲,它与 PCA 相似。
另外,正如您在之前的文章中提到的,只有当类别之间存在关系时,才应该使用序数编码器;当变量是名义上的时,关联度量(http://shakedzy.xyz/dython/)是否可以替代序数编码器+selectKbest?
非常感谢您的回复和有益的指导。
抱歉,我对这两个项目都不熟悉。
无论如何,谢谢。您分享的内容已经很有帮助了。
很高兴听到这个消息。
嗨,Jason,
谢谢分享,对我来说效果很好。
我有一个小问题:在卡方计算中,我们通常会计算自由度并选择一个显著性水平(例如 5%)来查找临界值,然后将我们的卡方得分与临界值进行比较,如果我们的得分大于临界值,我们就拒绝原假设,并得出两个变量是相关的结论。
在此 SelectKBest 方法中,我们如何知道临界值是多少?在没有与“截止值”或“标准”进行比较的情况下,我们如何选择 K?我很困惑,因为,例如,假设特征 3、4、5、8 是与其他特征相比得分最高的 4 个特征,但如果其中一些的卡方得分小于临界值呢?选择它们作为预测变量是否仍然合理?
我现在正在使用 selectKBest 方法处理我的一个数据集,我有 20 个特征(全部是布尔特征),有 19 个特征的得分 >= 20(满分 100),但我应该选择得分最高的 3 个,还是 19 个特征,因为它们都确实具有很高的得分并显示出与输出值 y 的相关性?
再次感谢!
很高兴听到这个消息。
您可以将截止值视为超参数并对其进行调整(推荐),或者手动为每个变量执行统计检验(很麻烦)。
抱歉,那里有个错别字——
“有 19 个特征的得分 >= 20 且 p 值 <0.01”
嗨,很棒的教程,我学到了很多!所以,我手头有一个具有以下两个特征的数据集:
1. 它包含名义上的值,但具有大量不同的值(例如,人名)
2. 它同时包含数值和名义上的值
我的兴趣仍然是调查这些特征对于二元分类问题的重要性。我有一些想法可以做到这一点:
递归特征消除 (RFE) 结合 Randomforest 或 LogisticRegression..
这听起来合理吗?对于如何处理那些具有大量不同值的名义值,我仍然有些困惑。
非常感谢您的任何建议或想法!
谢谢!
是的,这听起来是个不错的开始。我会使用 RFE 并包装一个稳健的模型或我打算使用的模型。
名字可能没有预测性。如果您认为它们有,可以对它们进行序数编码,或者进行哈希处理、嵌入处理,甚至词袋模型并进行测试。
你好 Jason,
首先,感谢您提供这些精彩的教程。您的文章确实是最好的,我经常在其中找到解决方案。
其次,我一直在研究我的问题(相关性),但没有找到真正有用的东西。
我有一个分类问题,有多个输入特征,我想将它们输入到我的神经网络中。我想知道输入特征与分类输出之间的相关性。一旦我知道是否存在相关性,我就会手动进行特征选择并添加/删除该特征。
我的输入特征是:
1. “数值实值”数字(形状:N,1)
2. “分类向量 [文本数据]”(形状:N,>1)
3. “数值向量”(形状:N,>1)
(其中“N”是训练样本的数量)
对于第 2 点,我没有将文本/分类数据分隔成多个输入特征(形状:N,1),而是将它们组合在一起(形状:N,>1)。因此,我需要找到一个分类向量与分类输出之间的单一相关性。
对于第 3 点,我也想找到我的多维数组(形状:N,>1)与输出之间的单一相关性。
通过单一相关系数,我的意思是,我并不关心向量中的每个参数与输出的相关性,而是我正在寻找整个向量与输出之间的相关性。
谢谢。如果需要任何澄清,请告诉我。
谢谢!
我不太确定。相关性旨在操作两个变量之间,例如一个输入和一个输出变量。
谢谢你的回复,杰森。
我认为执行“敏感性分析”对我的情况更有意义。
太棒了!
嗨 Jason,我有一个问题。
您对分类特征使用了序数编码。但是如果分类特征是名义上的呢?我们应该使用哪种编码?
同样,至少对于特征选择是这样。
嗨,Jason,
我最喜欢您作品的示例是,除了主要主题之外,我还学到了更多东西。
部署模型后,如何对新数据执行与训练样本相同的转换(在本例中为序数编码)(oe.transform(X_train)),以确保编码保持不变?
提前感谢。
谢谢。
您必须将您的转换对象与模型一起保存,以便将相同的转换应用于新数据。
https://machinelearning.org.cn/how-to-save-and-load-models-and-data-preparation-in-scikit-learn-for-later-use/
谢谢。
非常感谢您,先生,提供这些精彩且易于理解的教程。您今天的很多知识都归功于您。愿上帝保佑您。
不客气!
嗨,Jason,
卡方特征选择是否可以应用于具有数值输入和分类输出的数据集?
提前感谢
可以,但不太合适。
在此处查看替代方法
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
嗨,Jason,
感谢以上内容,确实非常有用。但缺少一个重要项目是获得模型认为是“保留”和“丢弃”的变量列表。如果您真的想理解模型及其预测方式,这一点非常重要。
在其中一个问题中,您写道:
“是的,列出所选特征的部分会显示特征编号或列索引。如果您有一个字符串形式的列名列表,您可以使用这些索引直接打印名称。”
对于我们这些新手来说,您能向我们展示一下怎么做吗?是否有指向您网站其他部分的链接提供了这些信息?
一切顺利。
不客气。
您可以单独使用特征选择方法,并使用对象本身的属性来报告所选特征和丢弃的特征。
博客和书籍中有许多示例,或许可以从这里开始
https://machinelearning.org.cn/rfe-feature-selection-in-python/
您也可以在页面顶部的框中搜索“feature selection”。
您好 Jason,感谢您分享的所有资料。
我想问一下如何处理调用 `mutual_info_classif` 特征选择方法时的 `random_state` 参数。
我发现这个参数,如果不初始化(例如使用通常的 42),实际上会在每次执行时导致选择完全不同的特征作为最重要的特征。
我是否错过了什么?
再次感谢您。
不客气。
您可以将 random_state(种子)设置为您喜欢的任何值,请参阅此链接
https://machinelearning.org.cn/introduction-to-random-number-generators-for-machine-learning/
Jason……这是一篇精彩的文章……一个很好的解决了我的问题的方法。但是它有 R 语言的代码版本吗?
谢谢!
抱歉,我没有 R 语言的示例。
你好,
感谢您提供的有用文章。您是否碰巧有另一篇文章讨论无监督特征选择(我的意思是,由于我没有目标变量),我该如何找出数据集中哪些特征重要/不重要/冗余/等等?谢谢!
特征为什么重要?这就是为什么我们通常将其用于监督学习,因为我们可以进行衡量。
如果您真的想朝那个方向发展,也许您可以考虑特征之间的相关性,看看它们是否相关性较低?因为高度相关意味着两个特征基本上携带相同的信息。
谢谢 Adrian。您所说的很有道理,但是,衡量特征之间的相关性只会涵盖它们之间的线性相关性。然而,我还需要非线性相关性。
基本上,我有一组特征(没有类标签),我想去掉那些基本上是重复的特征,保留那些组合在一起的特征(特征下的值为 0 和 1)。所以我在考虑互信息,但不知道如何进行,因为没有目标变量(/类标签)。我很感谢任何帮助!
相关性是我能想到的最接近的猜测。否则,您可能需要考虑使用特征*提取*而不是特征*选择*,例如,您可以使用 PCA 对您的特征进行变换,而不是直接使用特征。
谢谢,但是 PCA 不能告诉我哪些特征是关键的,哪些是重复的。
这个项目的重点是了解重要特征。谢谢您的想法!
正确的。PCA 是将所有特征混合在一起并提取新的东西。如果您仔细想想,如果一个特征是关键的,另一个是冗余的,您也可以反过来想,另一个是关键的,而第一个是冗余的。这就是为什么没有唯一的方法来完成这个选择。
那样的话,您选择哪一个都无关紧要,因为它们是重复/冗余的。目的是找到一个重要特征子集。没关系……我会弄清楚的。
如果数据集同时包含数值和分类特征怎么办?
数值特征应该比较容易,因为您不需要进行独热编码,例如。
嗨 Ashwin……将分类特征转换为数值特征是常见的做法。请参考以下有关 LabelEncoder 的文档。
https://scikit-learn.cn/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
此致,
您好 Adrian,感谢这篇精彩而全面的论文!
我有一个问题,关于我正在处理的一个项目:
数据库由许多二元列组成,例如:IsBitDefenderEnabled (0/1),IsSxsPassiveModeEnabled (0/1),依此类推,但它们不是目标标签(目标标签也是二元的)。
我该如何对这类特征进行特征选择?我是否应该将值视为向量并使用距离度量(如余弦相似度)来研究它们与目标标签的相似性?
我期待您的回复!
祝好,
Jacopo
嗨 Jacopo……感谢提问。
抱歉,我无法帮助你完成你的项目。
我很乐意帮忙,但我没有能力参与你的项目到你需要的程度或能做好工作的程度。
我相信你能理解我的立场,因为我每天都会收到许多项目帮助请求。
尽管如此,我很乐意回答你关于机器学习的任何具体问题。
嗨,Jason!
感谢您的帖子,解释得非常好。在阅读过程中,一个问题浮现出来:当您提到数据集时,您说一个好的分类准确率约为 76%。我想知道您是怎么得出这个数字的?
嗨 Natalia……一般来说,任何高于朴素模型的性能得分的得分都被认为是“好的”得分。
你好,Jason!
你能帮帮我吗。我不明白,我们用癌症数据想预测什么?
嗨 Alina……一种可能性是简单地分类癌症的存在与否。
嗨 James / Jason –
我浏览了论文“离散和连续数据集之间的互信息”。使用 KNN 方法来计算互信息,以实现“mutual_info_classification”和“mutual_info_regression”。我有一些快速的问题。请尽快回复。
1)由于 KNN 方法涉及距离度量,您认为数据中的异常值会影响互信息计算吗?因此,最佳实践是在实现互信息特征选择之前对异常值进行上限/下限处理?有趣的是,互信息的“分箱实现”不应受异常值的影响。
2)我认为变量 x 和 y 的分布偏度不会影响互信息计算。对吗?因此,我们在实现互信息特征选择之前不需要使分布更接近高斯分布?
嗨 Varun,
1. 您的理解是正确的!您是否有任何 KNN 实现可以证实这一点?我很感兴趣。
2. 以下内容可能有助于阐明
https://towardsdatascience.com/skewed-data-a-problem-to-your-statistical-model-9a6b5bb74e37
感谢您的回复 James。所以,我浏览了刚才提到的那篇论文。但是,我认为分箱过程与信用风险建模通常进行的类似。如果您搜索——证据权重和信息值 (IV)——您会发现 IV 和互信息是相似的概念。我可能需要检查它们是否计算相同的内容。使用分箱方法处理 IV 的便捷之处在于,我们不必担心数据中的任何异常值和偏度。我认为当使用分箱方法计算互信息时,我们不必担心异常值和偏度。这与使用具有 >= 2 个变量拆分的决策树桩相同。
感谢您提供的链接。我们始终可以转换变量来调整偏度。