网格搜索通常不是我们可以使用深度学习方法执行的操作。
这是因为深度学习方法通常需要大量数据和大型模型,两者结合起来会导致模型需要数小时、数天甚至数周的训练时间。
在数据集较小的情况下,例如单变量时间序列,可能可以使用网格搜索来调整深度学习模型的超参数。
在本教程中,您将发现如何开发一个框架来对深度学习模型的超参数进行网格搜索。
完成本教程后,您将了解:
- 如何开发一个通用的网格搜索框架来调整模型超参数。
- 如何对航空旅客单变量时间序列预测问题上的多层感知机模型进行超参数网格搜索。
- 如何调整框架以对卷积神经网络和长短期记忆神经网络进行超参数网格搜索。
启动您的项目,阅读我的新书《时间序列预测的深度学习》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。
- 更新于2019年5月:修复了代码中一个小小的重复赋值问题(感谢 Jameson)。

如何为时间序列预测进行深度学习模型的网格搜索
照片作者:Hannes Flo,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 时间序列问题
- 网格搜索框架
- 网格搜索多层感知机
- 网格搜索卷积神经网络
- 网格搜索长短期记忆网络
时间序列问题
“月度航空旅客”数据集总结了1949年至1960年间某个航空公司每月国际旅客的总数(以千为单位)。
直接从这里下载数据集
将文件另存为“monthly-airline-passengers.csv”并放在当前工作目录中。
我们可以使用 *read_csv()* 函数将此数据集加载为 Pandas 序列。
|
1 2 |
# 加载 series = read_csv('monthly-airline-passengers.csv', header=0, index_col=0) |
加载后,我们可以总结数据集的形状,以确定观测值的数量。
|
1 2 |
# 总结形状 print(series.shape) |
然后,我们可以绘制系列图,以了解系列的结构。
|
1 2 3 |
# 绘图 pyplot.plot(series) pyplot.show() |
我们可以将所有这些结合起来;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 |
# 加载并绘制数据集 from pandas import read_csv from matplotlib import pyplot # 加载 series = read_csv('monthly-airline-passengers.csv', header=0, index_col=0) # 总结形状 print(series.shape) # 绘图 pyplot.plot(series) pyplot.show() |
运行示例首先会打印数据集的形状。
|
1 |
(144, 1) |
该数据集是月度的,有12年,即144个观测值。在我们的测试中,我们将使用最后一年,即12个观测值,作为测试集。
创建了折线图。该数据集具有明显的趋势和季节性成分。季节性成分的周期是12个月。
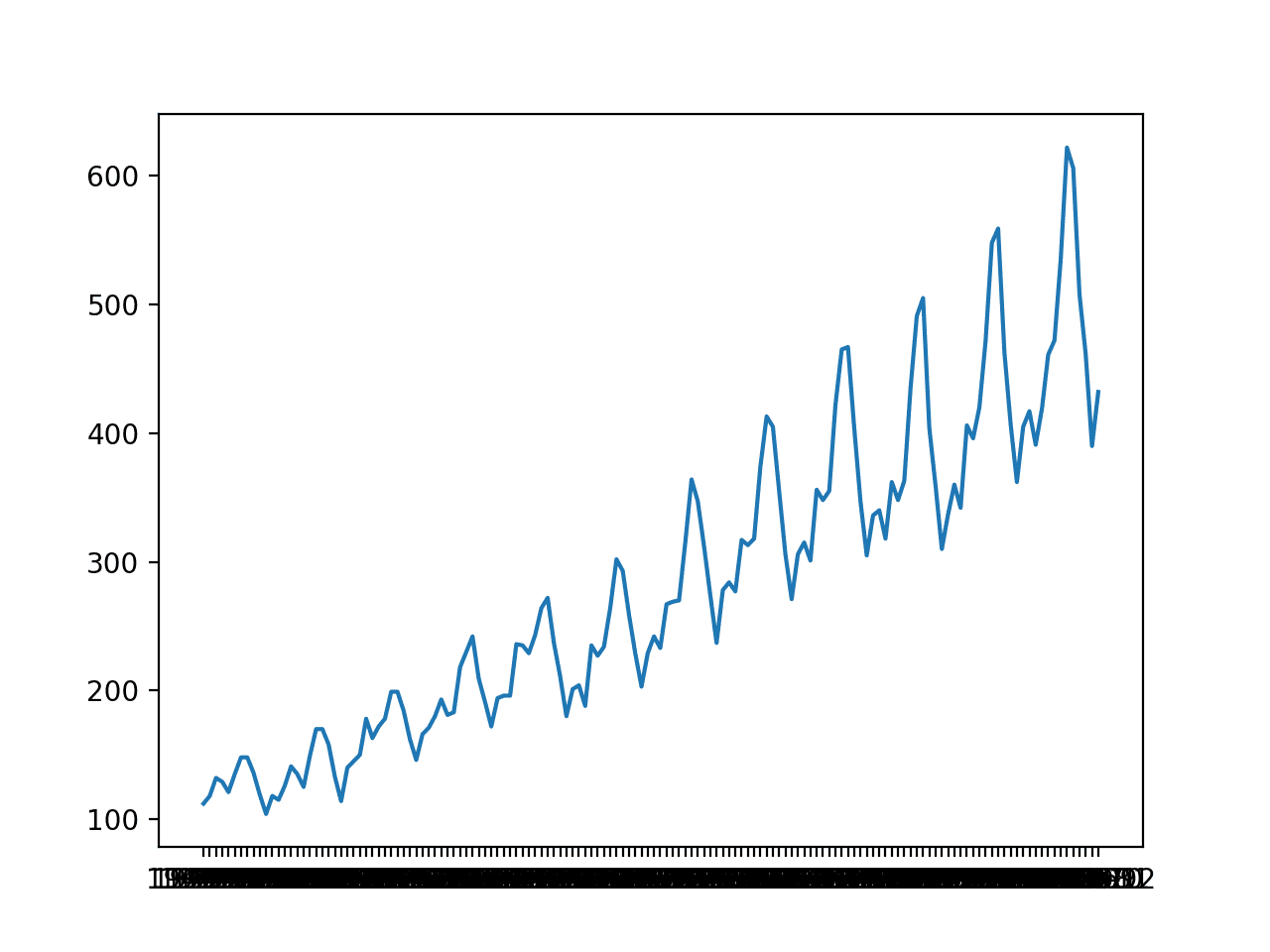
月度国际航空旅客折线图
在本教程中,我们将介绍用于网格搜索的工具,但我们不会针对此问题优化模型超参数。相反,我们将演示如何对深度学习模型超参数进行通用网格搜索,并找到比朴素模型更具技巧性的模型。
根据先前的实验,通过保持12个月前的值(相对索引 -12),朴素模型可以达到50.70的均方根误差(RMSE)(请记住单位是以千为单位的旅客)。
此朴素模型的性能提供了被认为是对此问题有技巧的模型的一个界限。任何在最后12个月的预测性能低于50.70的模型都被认为是有技巧的。
值得注意的是,经过调整的ETS模型可以达到17.09的RMSE,而经过调整的SARIMA模型可以达到13.89的RMSE。这些为对此问题经过良好调整的深度学习模型的期望提供了下限。
现在我们已经定义了问题和模型技巧的预期,我们可以着手定义网格搜索的测试环境。
网格搜索框架
在本节中,我们将开发一个网格搜索测试环境,该环境可用于评估不同神经网络模型(如MLP、CNN和LSTM)的超参数范围。
本节分为以下几个部分
- 训练-测试集分割
- 将序列视为监督学习
- 逐时验证
- 重复评估
- 总结性能
- 实例演示
训练-测试集分割
第一步是将加载的序列拆分为训练集和测试集。
我们将使用前11年(132个观测值)用于训练,最后12年用于测试集。
下面的train_test_split()函数将拆分序列,并将原始观测值和测试集中要使用的观测值数量作为参数。
|
1 2 3 |
# 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] |
将序列视为监督学习
接下来,我们需要能够将单变量序列的观测值构建成监督学习问题,以便我们可以训练神经网络模型。
将序列构建成监督学习问题意味着数据需要被分割成多个示例,模型可以从中学习并进行泛化。
每个样本都必须包含输入组件和输出组件。
输入组件将是一些先前的观测值,例如三年或36个时间步。
输出组件将是下个月的总销量,因为我们有兴趣开发一个模型来进行单步预测。
我们可以使用pandas DataFrame上的shift()函数来实现这一点。它允许我们将一列向下(向前)或向上(向后)移动。我们可以将序列作为数据列,然后创建该列的多个副本,向前或向后移动,以创建具有所需输入和输出元素的样本。
当序列向下移动时,会引入NaN值,因为我们在序列的开始之前没有值。
例如,定义为一列的序列
|
1 2 3 4 5 |
(t) 1 2 3 4 |
此列可以被移动并作为前一列插入
|
1 2 3 4 5 6 |
(t-1), (t) NaN, 1 1, 2 2, 3 3, 4 4 NaN |
我们可以看到,在第二行,值1被提供为先前时间步的观测值,而2是序列中的下一个值,当1作为输入提供时,模型可以预测或学习预测它。
带有NaN值的行可以被移除。
下面的series_to_supervised()函数实现了这个行为,允许您指定输入中要使用的滞后观测值数量以及每个样本的输出中要使用的数量。它还会删除包含NaN值的行,因为这些行不能用于训练或测试模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 将列表转换为监督学习格式 def series_to_supervised(data, n_in=1, n_out=1): df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 agg.dropna(inplace=True) return agg.values |
逐时验证
时间序列预测模型可以使用前向验证在测试集上进行评估。
前向验证是一种方法,模型会逐一预测测试数据集中的每个观测值。在对测试数据集中的某个时间点进行预测后,该预测的真实观测值会被添加到测试数据集中,并提供给模型。
更简单的模型可以在后续预测之前用先前的观测值进行重新拟合。更复杂的模型,如神经网络,由于计算成本高昂,不进行重新拟合。
尽管如此,该时间点的真实观测值可以作为输入的一部分,用于对下一个时间点进行预测。
首先,数据集被拆分为训练集和测试集。我们将调用train_test_split()函数来执行此拆分,并传入预先指定的要用作测试数据的观测值数量。
对于给定的配置,模型将只在训练数据集上拟合一次。
我们将定义一个通用的model_fit()函数来执行此操作,该函数可以针对我们稍后可能感兴趣的给定类型的神经网络进行填充。该函数接受训练数据集和模型配置,并返回准备好进行预测的拟合模型。
|
1 2 3 |
# 拟合模型 def model_fit(train, config): return None |
测试数据集的每个时间步都会被枚举。使用拟合模型进行预测。
同样,我们将定义一个名为model_predict()的通用函数,该函数接受拟合模型、历史记录和模型配置,并进行一次单步预测。
|
1 2 3 |
# 使用预先拟合的模型进行预测 def model_predict(model, history, config): return 0.0 |
预测值会被添加到预测列表中,而测试集中的真实观测值会被添加到观测值列表中,该列表以训练集中的所有观测值作为种子。该列表在预测验证的每个步骤中都会被构建起来,允许模型使用最近的历史记录进行单步预测。
然后,所有预测值都可以与测试集中的真实值进行比较,并计算误差度量。
我们将计算预测值和真实值之间的均方根误差(RMSE)。
RMSE计算为预测值和实际值之间平方差的平均值的平方根。measure_rmse()使用scikit-learn的mean_squared_error()函数来计算均方误差(MSE),然后再计算平方根。
|
1 2 3 |
# 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) |
将所有这些联系在一起的完整walk_forward_validation()函数如下所示。
它接受数据集、要用作测试集的观测值数量以及模型配置,并返回模型在测试集上的RMSE。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 拟合模型 model = model_fit(train, cfg) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = model_predict(model, history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) print(' > %.3f' % error) return error |
重复评估
神经网络模型是随机的。
这意味着,给定相同的模型配置和相同的训练数据集,每次训练模型时都会产生一组不同的内部权重,而这反过来又会产生不同的性能。
这是一个优势,允许模型具有适应性,并为复杂问题找到高性能的配置。
这也是在评估模型性能和选择最终模型以进行预测时的一个问题。
为了解决模型评估问题,我们将通过前向验证多次评估模型配置,并报告每次评估的平均误差。
这对于大型神经网络并不总是可行的,并且可能只对可以在几分钟或几小时内完成训练的小型网络有意义。
下面的repeat_evaluate()函数实现了这一点,并允许将重复次数指定为一个可选参数,默认值为10,并返回所有重复的平均RMSE分数。
|
1 2 3 4 5 6 7 8 9 10 |
# 评估模型,失败时返回 None def repeat_evaluate(data, config, n_test, n_repeats=10): # 将配置转换为键 key = str(config) # 拟合和评估模型n次 scores = [walk_forward_validation(data, n_test, config) for _ in range(n_repeats)] # 总结分数 result = mean(scores) print('> Model[%s] %.3f' % (key, result)) return (key, result) |
网格搜索
现在我们已经有了测试环境的所有组成部分。
剩下的是一个驱动搜索的函数。我们可以定义一个grid_search()函数,该函数接受数据集、要搜索的配置列表以及要用作测试集的观测值数量,并执行搜索。
一旦为每个配置计算出平均分数,配置列表将按升序排序,以便最佳分数列在最前面。
完整的函数如下所示。
|
1 2 3 4 5 6 7 |
# 网格搜索配置 def grid_search(data, cfg_list, n_test): # 评估配置 scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) return scores |
实例演示
现在我们已经定义了测试环境的各个组成部分,我们可以将它们全部联系起来并定义一个简单的持久化模型。
我们不需要拟合模型,所以model_fit()函数将被实现为简单地返回None。
|
1 2 3 |
# 拟合模型 def model_fit(train, config): return None |
我们将使用配置来定义一组先前观测值的索引偏移量,相对于要预测的时间,这些偏移量将用作预测。例如,12将使用要预测时间之前的12个月(相对偏移量-12)的观测值。
|
1 2 |
# 定义配置 cfg_list = [1, 6, 12, 24, 36] |
model_predict()函数可以被实现为使用此配置来持久化负相对偏移处的该值。
|
1 2 3 |
# 使用预先拟合的模型进行预测 def model_predict(model, history, offset): history[-offset] |
使用简单持久化模型使用框架的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
# 为航空旅客进行网格搜索持久化模型 from math import sqrt from numpy import mean from pandas import read_csv from sklearn.metrics import mean_squared_error # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 拟合模型 def model_fit(train, config): return None # 使用预先拟合的模型进行预测 def model_predict(model, history, offset): return history[-offset] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 拟合模型 model = model_fit(train, cfg) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = model_predict(model, history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) print(' > %.3f' % error) return error # 评估模型,失败时返回 None def repeat_evaluate(data, config, n_test, n_repeats=10): # 将配置转换为键 key = str(config) # 拟合和评估模型n次 scores = [walk_forward_validation(data, n_test, config) for _ in range(n_repeats)] # 总结分数 result = mean(scores) print('> Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test): # 评估配置 scores = [repeat_evaluate(data, cfg, n_test) for cfg in cfg_list] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # 定义数据集 series = read_csv('monthly-airline-passengers.csv', header=0, index_col=0) data = series.values # 数据分割 n_test = 12 # 模型配置 cfg_list = [1, 6, 12, 24, 36] # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('done') # 列出前10个配置 for cfg, error in scores[:10]: print(cfg, error) |
运行示例会打印出在最后12个月数据上使用前向验证评估的模型RMSE。
每个模型配置都评估了10次,尽管由于模型没有随机性,每次的分数都是相同的。
在运行结束时,会报告前三个性能最佳的模型配置及其RMSE。
我们可以预料到,保持一年前的值(相对偏移量-12)在持久化模型中获得了最佳性能。
|
1 2 3 4 5 6 7 8 9 10 11 |
... > 110.274 > 110.274 > 110.274 > Model[36] 110.274 完成 12 50.708316214732804 1 53.1515129919491 24 97.10990337413241 36 110.27352356753639 6 126.73495965991387 |
现在我们有了用于网格搜索模型超参数的健壮测试环境,我们可以使用它来评估一系列神经网络模型。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
网格搜索多层感知机
MLP有很多方面是我们可能想要调整的。
我们将定义一个非常简单的模型,带有一个隐藏层,并定义五个要调整的超参数。它们是
- n_input:用作模型输入的先前输入数量(例如,12个月)。
- n_nodes:隐藏层使用的节点数(例如,50)。
- n_epochs:训练轮数(例如,1000)。
- n_batch:每个小批量包含的样本数(例如,32)。
- n_diff:差分阶数(例如,0或12)。
现代神经网络可以处理原始数据,只需要很少的预处理,例如缩放和差分。尽管如此,对于时间序列数据,有时对序列进行差分可以使问题更容易建模。
回想一下,差分是将数据进行转换,即将先前观测值的值减去当前观测值,从而去除趋势或季节性结构。
我们将为网格搜索测试环境添加对差分的支持,以防它对您的特定问题有所帮助。它确实为内部航空旅客数据集增加了价值。
下面的difference()函数将计算给定阶数的差分。
|
1 2 3 |
# 差异数据集 def difference(data, order): return [data[i] - data[i - order] for i in range(order, len(data))] |
差分是可选的,其中阶数为0表示不进行差分,而阶数为1或12则要求在拟合模型之前对数据进行差分,并且模型预测值在返回预测之前需要反向差分。
我们现在可以定义在测试环境中拟合MLP模型所需的元素。
首先,我们必须解包超参数列表。
|
1 2 |
# 解包配置 n_input, n_nodes, n_epochs, n_batch, n_diff = config |
接下来,我们必须准备数据,包括差分、将数据转换为监督格式,以及将数据样本的输入和输出部分分开。
|
1 2 3 4 5 6 7 |
# 准备数据 if n_diff > 0: train = difference(train, n_diff) # 将序列转换为监督格式 data = series_to_supervised(train, n_in=n_input) # 分离输入和输出 train_x, train_y = data[:, :-1], data[:, -1] |
现在,我们可以使用提供的配置来定义和拟合模型。
|
1 2 3 4 5 6 7 |
# 定义模型 model = Sequential() model.add(Dense(n_nodes, activation='relu', input_dim=n_input)) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合模型 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) |
下面列出了model_fit()函数的完整实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 拟合模型 def model_fit(train, config): # 解包配置 n_input, n_nodes, n_epochs, n_batch, n_diff = config # 准备数据 if n_diff > 0: train = difference(train, n_diff) # transform series into supervised format data = series_to_supervised(train, n_in=n_input) # separate inputs and outputs train_x, train_y = data[:, :-1], data[:, -1] # 定义模型 model = Sequential() model.add(Dense(n_nodes, activation='relu', input_dim=n_input)) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合模型 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) return model |
前面选择的五个超参数绝不是模型中唯一或最好的要调整的超参数。您可以修改该函数来调整其他参数,例如添加更多隐藏层及其大小,以及更多内容。
模型拟合后,我们可以使用它来进行预测。
如果数据进行了差分处理,则必须对差分进行逆运算,以用于模型的预测。这包括将历史记录中相对于偏移量的值加回到模型预测的值上。
|
1 2 3 4 5 6 7 |
# invert difference correction = 0.0 if n_diff > 0: correction = history[-n_diff] ... # correct forecast if it was differenced return correction + yhat[0] |
这也意味着必须对历史记录进行差分处理,以便用于进行预测的输入数据具有预期的形式。
|
1 2 |
# calculate difference history = difference(history, n_diff) |
准备好后,我们可以使用历史数据创建一个样本作为模型输入,以进行一步预测。
一个样本的形状必须是 [1, n_input],其中 n_input 是选择的滞后观测值数量。
|
1 2 |
# shape input for model x_input = array(history[-n_input:]).reshape((1, n_input)) |
最后,可以进行预测。
|
1 2 |
# 进行预测 yhat = model.predict(x_input, verbose=0) |
下面列出了model_predict()函数的完整实现。
接下来,我们需要定义每个超参数要尝试的值范围。
我们可以定义一个model_configs()函数,该函数创建要尝试的不同参数组合列表。
我们将定义一小组配置作为示例,包括 12 个月的差分,我们预计这将是必需的。鼓励您尝试独立的模型,查看学习曲线诊断图,并利用领域信息来设置超参数的网格搜索值范围。
还鼓励您重复网格搜索,以缩小到看起来表现更好的值范围。
下面列出了model_configs()函数的实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# create a list of configs to try def model_configs(): # define scope of configs n_input = [12] n_nodes = [50, 100] n_epochs = [100] n_batch = [1, 150] n_diff = [0, 12] # create configs configs = list() for i in n_input: for j in n_nodes: for k in n_epochs: for l in n_batch: for m in n_diff: cfg = [i, j, k, l, m] configs.append(cfg) print('Total configs: %d' % len(configs)) return configs |
现在,我们拥有了用于单变量时间序列预测问题的 MLP 模型网格搜索所需的所有组件。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 |
# grid search mlps for airline passengers from math import sqrt from numpy import array from numpy import mean from pandas import DataFrame 从 pandas 导入 concat from pandas import read_csv from sklearn.metrics import mean_squared_error from keras.models import Sequential from keras.layers import Dense # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 将列表转换为监督学习格式 def series_to_supervised(data, n_in=1, n_out=1): df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 agg.dropna(inplace=True) return agg.values # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 差异数据集 def difference(data, order): return [data[i] - data[i - order] for i in range(order, len(data))] # 拟合模型 def model_fit(train, config): # 解包配置 n_input, n_nodes, n_epochs, n_batch, n_diff = config # 准备数据 if n_diff > 0: train = difference(train, n_diff) # transform series into supervised format data = series_to_supervised(train, n_in=n_input) # separate inputs and outputs train_x, train_y = data[:, :-1], data[:, -1] # 定义模型 model = Sequential() model.add(Dense(n_nodes, activation='relu', input_dim=n_input)) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合模型 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) return model # forecast with the fit model def model_predict(model, history, config): # 解包配置 n_input, _, _, _, n_diff = config # 准备数据 correction = 0.0 if n_diff > 0: correction = history[-n_diff] history = difference(history, n_diff) # shape input for model x_input = array(history[-n_input:]).reshape((1, n_input)) # 进行预测 yhat = model.predict(x_input, verbose=0) # correct forecast if it was differenced return correction + yhat[0] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 拟合模型 model = model_fit(train, cfg) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = model_predict(model, history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) print(' > %.3f' % error) return error # 评估模型,失败时返回 None def repeat_evaluate(data, config, n_test, n_repeats=10): # 将配置转换为键 key = str(config) # 拟合和评估模型n次 scores = [walk_forward_validation(data, n_test, config) for _ in range(n_repeats)] # 总结分数 result = mean(scores) print('> Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test): # 评估配置 scores = [repeat_evaluate(data, cfg, n_test) for cfg in cfg_list] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # create a list of configs to try def model_configs(): # define scope of configs n_input = [12] n_nodes = [50, 100] n_epochs = [100] n_batch = [1, 150] n_diff = [0, 12] # create configs configs = list() for i in n_input: for j in n_nodes: for k in n_epochs: for l in n_batch: for m in n_diff: cfg = [i, j, k, l, m] configs.append(cfg) print('Total configs: %d' % len(configs)) return configs # 定义数据集 series = read_csv('monthly-airline-passengers.csv', header=0, index_col=0) data = series.values # 数据分割 n_test = 12 # 模型配置 cfg_list = model_configs() # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('done') # list top 3 configs for cfg, error in scores[:3]: print(cfg, error) |
运行示例,我们可以看到框架将评估总共八种配置。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行示例几次并比较平均结果。
每种配置将评估 10 次;这意味着将使用前向验证创建和评估 10 个模型,以计算 RMSE 分数,然后在报告的 10 个分数的平均值用于对配置进行评分。
然后对分数进行排序,并报告具有最低 RMSE 的前 3 个配置。与报告 RMSE 为 50.70 的朴素模型相比,找到了一个有技能的模型配置。
我们可以看到,以 [12, 100, 100, 1, 12] 的配置实现了最佳 RMSE 18.98,这可以解释为
- n_input: 12
- n_nodes: 100
- n_epochs: 100
- n_batch: 1
- n_diff: 12
下面列出了网格搜索的截断示例输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Total configs: 8 > 20.707 > 29.111 > 17.499 > 18.918 > 28.817 ... > 21.015 > 20.208 > 18.503 > Model[[12, 100, 100, 150, 12]] 19.674 完成 [12, 100, 100, 1, 12] 18.982720013625606 [12, 50, 100, 150, 12] 19.33004059448595 [12, 100, 100, 1, 0] 19.5389405532858 |
网格搜索卷积神经网络
现在我们可以调整框架来网格搜索 CNN 模型。
与 MLP 模型一样,可以搜索的超参数集基本相同,只是隐藏层中的节点数可以被卷积层中的滤波器图数和核大小替换。
在 CNN 模型中选择的要网格搜索的超参数集如下:
- n_input:用作模型输入的先前输入数量(例如,12个月)。
- n_filters:卷积层中的滤波器图数(例如 32)。
- n_kernel:卷积层中的核大小(例如 3)。
- n_epochs:训练轮数(例如,1000)。
- n_batch:每个小批量包含的样本数(例如,32)。
- n_diff:差分阶数(例如,0或12)。
您可能希望研究的一些额外超参数是:在池化层之前使用两个卷积层,重复卷积和池化层模式,使用 dropout,以及更多。
我们将定义一个非常简单的 CNN 模型,其中包含一个卷积层和一个最大池化层。
|
1 2 3 4 5 6 7 |
# 定义模型 model = Sequential() model.add(Conv1D(filters=n_filters, kernel_size=n_kernel, activation='relu', input_shape=(n_input, n_features))) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') |
数据必须像 MLP 一样进行准备。
与 MLP 期望输入数据的形状为 [samples, features] 不同,1D CNN 模型期望数据的形状为 [samples, timesteps, features],其中 features 映射到通道,在这个例子中是 1,因为我们每个月测量一个变量。
|
1 2 3 |
# reshape input data into [samples, timesteps, features] n_features = 1 train_x = train_x.reshape((train_x.shape[0], train_x.shape[1], n_features)) |
下面列出了model_fit()函数的完整实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 拟合模型 def model_fit(train, config): # 解包配置 n_input, n_filters, n_kernel, n_epochs, n_batch, n_diff = config # 准备数据 if n_diff > 0: train = difference(train, n_diff) # transform series into supervised format data = series_to_supervised(train, n_in=n_input) # separate inputs and outputs train_x, train_y = data[:, :-1], data[:, -1] # reshape input data into [samples, timesteps, features] n_features = 1 train_x = train_x.reshape((train_x.shape[0], train_x.shape[1], n_features)) # 定义模型 model = Sequential() model.add(Conv1D(filters=n_filters, kernel_size=n_kernel, activation='relu', input_shape=(n_input, n_features))) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) return model |
使用拟合的 CNN 模型进行预测与使用拟合的 MLP 模型进行预测非常相似。
同样,唯一的区别是,一个样本的输入数据必须具有三维形状。
|
1 |
x_input = array(history[-n_input:]).reshape((1, n_input, 1)) |
下面列出了model_predict()函数的完整实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# forecast with the fit model def model_predict(model, history, config): # 解包配置 n_input, _, _, _, _, n_diff = config # 准备数据 correction = 0.0 if n_diff > 0: correction = history[-n_diff] history = difference(history, n_diff) x_input = array(history[-n_input:]).reshape((1, n_input, 1)) # 预测 yhat = model.predict(x_input, verbose=0) return correction + yhat[0] |
最后,我们可以定义一个模型要评估的配置列表。与之前一样,我们可以通过定义要尝试的超参数值列表来做到这一点,这些列表被组合成一个列表。我们将尝试少量配置,以确保示例在合理的时间内执行。
下面列出了完整的model_configs()函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# create a list of configs to try def model_configs(): # define scope of configs n_input = [12] n_filters = [64] n_kernels = [3, 5] n_epochs = [100] n_batch = [1, 150] n_diff = [0, 12] # create configs configs = list() for a in n_input: for b in n_filters: for c in n_kernels: for d in n_epochs: for e in n_batch: for f in n_diff: cfg = [a,b,c,d,e,f] configs.append(cfg) print('Total configs: %d' % len(configs)) return configs |
现在,我们拥有了用于单变量时间序列预测的卷积神经网络超参数网格搜索所需的所有要素。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
# grid search cnn for airline passengers from math import sqrt from numpy import array from numpy import mean from pandas import DataFrame 从 pandas 导入 concat from pandas import read_csv from sklearn.metrics import mean_squared_error from keras.models import Sequential from keras.layers import Dense from keras.layers import Flatten from keras.layers.convolutional import Conv1D from keras.layers.convolutional import MaxPooling1D # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 将列表转换为监督学习格式 def series_to_supervised(data, n_in=1, n_out=1): df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 agg.dropna(inplace=True) return agg.values # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 差异数据集 def difference(data, order): return [data[i] - data[i - order] for i in range(order, len(data))] # 拟合模型 def model_fit(train, config): # 解包配置 n_input, n_filters, n_kernel, n_epochs, n_batch, n_diff = config # 准备数据 if n_diff > 0: train = difference(train, n_diff) # transform series into supervised format data = series_to_supervised(train, n_in=n_input) # separate inputs and outputs train_x, train_y = data[:, :-1], data[:, -1] # reshape input data into [samples, timesteps, features] n_features = 1 train_x = train_x.reshape((train_x.shape[0], train_x.shape[1], n_features)) # 定义模型 model = Sequential() model.add(Conv1D(filters=n_filters, kernel_size=n_kernel, activation='relu', input_shape=(n_input, n_features))) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) return model # forecast with the fit model def model_predict(model, history, config): # 解包配置 n_input, _, _, _, _, n_diff = config # 准备数据 correction = 0.0 if n_diff > 0: correction = history[-n_diff] history = difference(history, n_diff) x_input = array(history[-n_input:]).reshape((1, n_input, 1)) # 预测 yhat = model.predict(x_input, verbose=0) return correction + yhat[0] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 拟合模型 model = model_fit(train, cfg) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = model_predict(model, history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) print(' > %.3f' % error) return error # 评估模型,失败时返回 None def repeat_evaluate(data, config, n_test, n_repeats=10): # 将配置转换为键 key = str(config) # 拟合和评估模型n次 scores = [walk_forward_validation(data, n_test, config) for _ in range(n_repeats)] # 总结分数 result = mean(scores) print('> Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test): # 评估配置 scores = [repeat_evaluate(data, cfg, n_test) for cfg in cfg_list] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # create a list of configs to try def model_configs(): # define scope of configs n_input = [12] n_filters = [64] n_kernels = [3, 5] n_epochs = [100] n_batch = [1, 150] n_diff = [0, 12] # create configs configs = list() for a in n_input: for b in n_filters: for c in n_kernels: for d in n_epochs: for e in n_batch: for f in n_diff: cfg = [a,b,c,d,e,f] configs.append(cfg) print('Total configs: %d' % len(configs)) return configs # 定义数据集 series = read_csv('monthly-airline-passengers.csv', header=0, index_col=0) data = series.values # 数据分割 n_test = 12 # 模型配置 cfg_list = model_configs() # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('done') # 列出前10个配置 for cfg, error in scores[:3]: print(cfg, error) |
运行示例,我们可以看到只有八种不同的配置被评估。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行示例几次并比较平均结果。
我们可以看到,[12, 64, 5, 100, 1, 12] 的配置实现了 18.89 的 RMSE,这与实现 50.70 的朴素预测模型相比是有技能的。
我们可以将此配置解包为
- n_input: 12
- n_filters: 64
- n_kernel: 5
- n_epochs: 100
- n_batch: 1
- n_diff: 12
下面列出了网格搜索的截断示例输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Total configs: 8 > 23.372 > 28.317 > 31.070 ... > 20.923 > 18.700 > 18.210 > Model[[12, 64, 5, 100, 150, 12]] 19.152 完成 [12, 64, 5, 100, 1, 12] 18.89593462072732 [12, 64, 5, 100, 150, 12] 19.152486150334234 [12, 64, 3, 100, 150, 12] 19.44680151564605 |
网格搜索长短期记忆网络
现在我们可以采用该框架来网格搜索 LSTM 模型的超参数。
LSTM 模型的超参数将与 MLP 的超参数相同,共五个;它们是
- n_input:用作模型输入的先前输入数量(例如,12个月)。
- n_nodes:隐藏层使用的节点数(例如,50)。
- n_epochs:训练轮数(例如,1000)。
- n_batch:每个小批量包含的样本数(例如,32)。
- n_diff:差分阶数(例如,0或12)。
我们将定义一个简单的LSTM模型,其中包含一个隐藏的LSTM层,节点的数量指定了该层中单元的数量。
|
1 2 3 4 5 6 7 8 |
# 定义模型 model = Sequential() model.add(LSTM(n_nodes, activation='relu', input_shape=(n_input, n_features))) model.add(Dense(n_nodes, activation='relu')) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合模型 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) |
探索调整其他配置可能会很有趣,例如使用双向输入层、堆叠LSTM层,甚至使用CNN或ConvLSTM输入模型的混合模型。
与CNN模型一样,LSTM模型期望输入数据的形状为三维:样本、时间步长和特征。
|
1 2 3 |
# reshape input data into [samples, timesteps, features] n_features = 1 train_x = train_x.reshape((train_x.shape[0], train_x.shape[1], n_features)) |
下面列出了model_fit()函数的完整实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 拟合模型 def model_fit(train, config): # 解包配置 n_input, n_nodes, n_epochs, n_batch, n_diff = config # 准备数据 if n_diff > 0: train = difference(train, n_diff) # transform series into supervised format data = series_to_supervised(train, n_in=n_input) # separate inputs and outputs train_x, train_y = data[:, :-1], data[:, -1] # reshape input data into [samples, timesteps, features] n_features = 1 train_x = train_x.reshape((train_x.shape[0], train_x.shape[1], n_features)) # 定义模型 model = Sequential() model.add(LSTM(n_nodes, activation='relu', input_shape=(n_input, n_features))) model.add(Dense(n_nodes, activation='relu')) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合模型 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) return model |
同样,与CNN一样,用于进行预测的单个输入样本也必须重塑为预期的三维结构。
|
1 2 |
# 将样本重塑为 [样本数, 时间步长, 特征数] x_input = array(history[-n_input:]).reshape((1, n_input, 1)) |
完整的model_predict()函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# forecast with the fit model def model_predict(model, history, config): # 解包配置 n_input, _, _, _, n_diff = config # 准备数据 correction = 0.0 if n_diff > 0: correction = history[-n_diff] history = difference(history, n_diff) # 将样本重塑为 [样本数, 时间步长, 特征数] x_input = array(history[-n_input:]).reshape((1, n_input, 1)) # 预测 yhat = model.predict(x_input, verbose=0) return correction + yhat[0] |
我们现在可以定义用于创建要评估的模型配置列表的函数。
LSTM模型训练起来比MLP和CNN模型慢很多;因此,您可能希望每次运行评估的配置数量较少。
我们将定义一组非常简单的两个配置来探索:随机梯度下降和批量梯度下降。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# create a list of configs to try def model_configs(): # define scope of configs n_input = [12] n_nodes = [100] n_epochs = [50] n_batch = [1, 150] n_diff = [12] # create configs configs = list() for i in n_input: for j in n_nodes: for k in n_epochs: for l in n_batch: for m in n_diff: cfg = [i, j, k, l, m] configs.append(cfg) print('Total configs: %d' % len(configs)) return configs |
现在我们拥有了对LSTM模型进行网格搜索以进行单变量时间序列预测所需的所有内容。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 |
# 网格搜索lstm以预测航空公司乘客数量 from math import sqrt from numpy import array from numpy import mean from pandas import DataFrame 从 pandas 导入 concat from pandas import read_csv from sklearn.metrics import mean_squared_error from keras.models import Sequential from keras.layers import Dense 来自 keras.层 导入 LSTM # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 将列表转换为监督学习格式 def series_to_supervised(data, n_in=1, n_out=1): df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 agg.dropna(inplace=True) return agg.values # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 差异数据集 def difference(data, order): return [data[i] - data[i - order] for i in range(order, len(data))] # 拟合模型 def model_fit(train, config): # 解包配置 n_input, n_nodes, n_epochs, n_batch, n_diff = config # 准备数据 if n_diff > 0: train = difference(train, n_diff) # transform series into supervised format data = series_to_supervised(train, n_in=n_input) # separate inputs and outputs train_x, train_y = data[:, :-1], data[:, -1] # reshape input data into [samples, timesteps, features] n_features = 1 train_x = train_x.reshape((train_x.shape[0], train_x.shape[1], n_features)) # 定义模型 model = Sequential() model.add(LSTM(n_nodes, activation='relu', input_shape=(n_input, n_features))) model.add(Dense(n_nodes, activation='relu')) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') # 拟合模型 model.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0) return model # forecast with the fit model def model_predict(model, history, config): # 解包配置 n_input, _, _, _, n_diff = config # 准备数据 correction = 0.0 if n_diff > 0: correction = history[-n_diff] history = difference(history, n_diff) # 将样本重塑为 [样本数, 时间步长, 特征数] x_input = array(history[-n_input:]).reshape((1, n_input, 1)) # 预测 yhat = model.predict(x_input, verbose=0) return correction + yhat[0] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 拟合模型 model = model_fit(train, cfg) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = model_predict(model, history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) print(' > %.3f' % error) return error # 评估模型,失败时返回 None def repeat_evaluate(data, config, n_test, n_repeats=10): # 将配置转换为键 key = str(config) # 拟合和评估模型n次 scores = [walk_forward_validation(data, n_test, config) for _ in range(n_repeats)] # 总结分数 result = mean(scores) print('> Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test): # 评估配置 scores = [repeat_evaluate(data, cfg, n_test) for cfg in cfg_list] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # create a list of configs to try def model_configs(): # define scope of configs n_input = [12] n_nodes = [100] n_epochs = [50] n_batch = [1, 150] n_diff = [12] # create configs configs = list() for i in n_input: for j in n_nodes: for k in n_epochs: for l in n_batch: for m in n_diff: cfg = [i, j, k, l, m] configs.append(cfg) print('Total configs: %d' % len(configs)) return configs # 定义数据集 series = read_csv('monthly-airline-passengers.csv', header=0, index_col=0) data = series.values # 数据分割 n_test = 12 # 模型配置 cfg_list = model_configs() # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('done') # 列出前10个配置 for cfg, error in scores[:3]: print(cfg, error) |
运行示例,我们可以看到只评估了两种不同的配置。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。考虑运行示例几次并比较平均结果。
我们可以看到,配置为[12, 100, 50, 1, 12]的模型达到了21.24的RMSE,这与达到50.70的朴素预测模型相比是有效的。
该模型需要更多的调整,并且通过混合配置(例如,将CNN模型作为输入)可能会做得更好。
我们可以将此配置解包为
- n_input: 12
- n_nodes: 100
- n_epochs: 50
- n_batch: 1
- n_diff: 12
下面列出了网格搜索的截断示例输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
总配置数:2 > 20.488 > 17.718 > 21.213 ... > 22.300 > 20.311 > 21.322 > 模型[[12, 100, 50, 150, 12]] 21.260 完成 [12, 100, 50, 1, 12] 21.243775750634093 [12, 100, 50, 150, 12] 21.259553398553606 |
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 更多配置。探索其中一个模型的各种配置,看看是否能找到一个能带来更好性能的配置。
- 数据缩放。更新网格搜索框架,以支持在拟合模型之前对数据进行缩放(归一化和/或标准化),以及在预测时反转变换。
- 网络架构。探索对给定模型进行网格搜索更大的架构更改,例如添加更多隐藏层。
- 新数据集。在一个新的单变量时间序列数据集中探索给定模型的网格搜索。
- 多变量。更新网格搜索框架以支持小型多变量时间序列数据集,例如具有多个输入变量的数据集。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
总结
在本教程中,您将了解如何开发一个框架来对深度学习模型进行超参数网格搜索。
具体来说,你学到了:
- 如何开发一个通用的网格搜索框架来调整模型超参数。
- 如何对航空旅客单变量时间序列预测问题上的多层感知机模型进行超参数网格搜索。
- 如何调整框架以对卷积神经网络和长短期记忆神经网络进行超参数网格搜索。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






感谢您提供如此精彩的信息。
很高兴它有帮助。
在“网格搜索长短期记忆网络”一节中,为什么您只使用训练数据来做“series_to_supervised”而不是整个原始数据?谢谢!
因为我们应该保留一个测试集来评估我们的模型是否是一个好的模型。
只是想感谢您提供如此出色的教程。它们极大地帮助了我。
谢谢,很高兴听到这个。
你好杰森
一个非常全面且丰富的超参数教程(即模型误差输出与超参数输入的敏感性分析)。甚至对于练习模型定义,如MLP,CNN和LSTM也很有用。此外,还可以练习模块或函数来标准化代码。非常感谢。我得到了与您相同的结果,但有一些第一位小数的变化!。
我的评论,如果有用的话,与机器学习结构相关的两个主要核心有关
–第一个是关于数据集的“分帧”(即准备输入与标签(输出)以及数据集的训练与测试分割)。“def train_test_split”函数非常清晰,但“def series_to_supervised”函数不太清晰。可能是因为使用了DataFrame的方法DataFrame.shift[i]用于后向输入,这与shift[-i]用于前向或标签相矛盾:-)。我的建议是使用一些图示或绘图来更清晰地展示这些输入-标签是如何从原始数据集列中捕获的。
-第二个是关于维度和重塑的匹配。所以,模型定义的第一层参数(input_shape=)对于不同的模型(MLP、CNN、LSTM),或者如何重塑training_data(输入数据到[samples, timesteps, features]到不同的model_fit函数,或者最后是x_input到不同的model_predict函数(x_input = array(history[-n_input:]).reshape((1, n_input, 1)))。再说一遍,我的建议是使用一些图示或绘图或矩阵来显示这些维度如何匹配过程的不同输入部分(层、训练、预测等)。
根据我的经验,这些通常是代码中比较困难的部分……我总是需要努力处理它们。因此,在代码演示中强调这些难点……会有很大帮助。
感谢您的工作。
谢谢。
这篇帖子可能有助于理解时间序列到监督学习的映射
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
另一个好问题,我在这里更详细地介绍了
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
你说得对,图片会有帮助!
谢谢 Jason。
1)我看到了您对单步或多步以及单变量或多变量时间序列有用的函数
“def series_to_supervised(data, n_in=1, n_out=1, dropnan=True)”
但我还看到,设置pandas中“shift”函数的那个人决定使用shift(+i)向后(t-1)移动,使用shift(-1)向前(t+1)移动:有点违反直觉:-)
谢谢。
2)我现在更清楚了LSTM输入的3D维度的含义(我想CNN也是一样),如[样本数, 时间步长, 特征数]……谢谢
但我也看到,当您在input_shape参数中定义数据3D形状为[samples, timesteps, features]时,必须省略samples维度,并且只在setup中保留一个2D元组[timesteps, features],并且在x_input for model_predict中也必须设置samples为1,即[1, timesteps=1, features)=1。
我希望更多的例子能让我们更容易理解
谢谢
很好的观察!
很高兴它有帮助。
嗨,Jason,
很棒的教程!请告诉我如何为LSTM预测一个未来值。
例如,我有一个训练好的LSTM,想预测t(n+1)。
上面的例子只显示了使用测试集进行预测。
谢谢你
Joe
我在这里展示了如何对已训练好的LSTM模型进行预测
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
嗨 Jason
太棒了!谢谢
Joe
长短期记忆网络在时间序列预测方面表现最差。
人们普遍认为LSTM在时间序列中发挥着积极作用。
如何解释这个问题?
普遍认为?也许是出于非实践者的观点?
也许可以看看这个
https://machinelearning.org.cn/suitability-long-short-term-memory-networks-time-series-forecasting/
还有这个。
https://machinelearning.org.cn/findings-comparing-classical-and-machine-learning-methods-for-time-series-forecasting/
LSTMs可能在多变量和多步问题中有用,但我的测试表明CNN及其变体(convlstm和cnnlstm)仍然优于普通的LSTM。
你好 Jason,
感谢您的这篇文章。
我目前正在探索多变量多步网格搜索。我正在使用前向验证法,我有一个问题,我可以使用前向验证法来解决多步问题吗?
前向验证中的折叠将是(如果我错了请纠正我)
输入 [1, 2, 3 ] 输出 [4,5]
输入 [2, 3, 4 ] 输出 [5,6]
输入 [3, 4, 5 ] 输出 [6,7]
对于多变量多步,我将拥有
输入 [[1,2,3 ] [11, 22 , 33 ] [111,222,333] ] 输出 [4,5, 44, 55 , 444,555]
输入 [[2,3,4 ] [22 , 33, 44 ] [222,333,444] ] 输出 [5,6, 55 ,66,555,666]
因为输出将被展平。
我认为看起来不错。
我们使用验证集来调整模型,并使用测试集来评估模型。
时间序列预测模型可以在测试集上使用前向验证进行评估。我们是否缺少验证集?事实上,我们使用测试集来调整模型。
您可以将训练集分成训练集和验证集,通过在训练集上进行前向验证找到模型,然后在验证集上通过前向验证调整它,最后在测试集上通过前向验证进行评估。
这有帮助吗?
谢谢!我想到了另一个问题。
我们将数据集按时间顺序划分,因此我们单独划分了验证集和测试集。我们的模型无法学习验证集的信息。很可能验证集的数据是必须学习的。也许验证集对于时间序列来说并不重要。但是,时间信息的新损失可能会导致模型性能变差。
也许可以。
测试框架和评估模型的方法通常是针对特定项目设计的。您必须设计它,以便您对模型的性能估算感到满意和自信。
你好。祝贺您提供的内容。是否有可能在此代码中实现并行化?我该如何强制使用所有可用的CPU核心?
我认为拟合每个深度学习模型都会使用所有核心。
Jason,非常感谢您与我们分享您的知识。非常感谢。
我想问一下,这个基础(monthly-airline-passengers.csv)是否有2000行和两列作为输入,例如机票价格和燃油价格,输出是乘客人数,是否可以应用此代码LSTM?
也许,我建议从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好Jason,我有一些问题。
例如,我有一个多变量时间序列问题。我使用了LSTM方法。在构建模型之后,我对用于预测的输入xhat感到有些困惑。
例如,我有6个月的每日数据集观察。如果我训练5个月的数据集,然后使用这6个月的xhat作为输入来查看我的模型有多好。
然后,如果我想预测第7个月,我该如何创建xhat作为输入?
感谢您创建如此出色的数据科学博客。您太棒了。
您模型的输入将是您在进行预测时定义的输入。
如果模型需要1周的输入来做出预测,那么您需要一周之前的观测值作为输入。
这有帮助吗?
我需要MLP的这个案例,请
我想知道您是否尝试过设置numpy和Tensorflow的随机数种子来重现这个示例的结果。我读过您关于Keras可复现性的帖子,并尝试过实现其中的建议,但都没有成功。您认为上面的示例模型是否过于复杂,无法重现结果?
不,抱歉,我尽量避免固定种子。这与机器学习算法的随机性作斗争。
多次运行取平均值,这是我最好的建议!
明白了。谢谢Jason。
Jason,
为什么您不使用GridSearchCV而编写自己的函数?我读了您的代码,在我看来,您的代码结构与预先构建的GridSearchCV(一堆for循环)相同。您不想使用GridSearchCV/RandomizedSearchCV的原因是什么?
更多的控制。
我明白了。您是否有如何将GridSearchCV(来自scikit-learn)与LSTM一起使用的示例?我一直在形状方面遇到问题(GridSearch需要输入数组的形状为[n_samples, n_features],而LSTM要求[samples, timesteps, features])?
不,我建议手动进行LSTM的网格搜索。
精彩的帖子!非常有价值!两个问题。
1)“history”在前向验证中做什么?
2)在同一段代码“history”之后,据我所知,您一次预测一个示例用于每个测试集。我们可以(或者应该)一次预测100个,就像批处理一样,以加快速度吗?
谢谢
谢谢。
History提供了输入或重新训练的上下文,更多内容请看这里
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
嗨,Jason,
我从您出色的文章中学到了很多关于LSTM的知识。
在这段代码中,我认为您遗漏了test_x数组的最后一个条目,因为您在第一个循环中没有添加任何test_x的值。
for i in range(len(test))
# 拟合模型并对历史数据进行预测
yhat = model_predict(model, history, cfg)
# 将预测结果存储到预测列表中
predictions.append(yhat)
# 将实际观测值添加到历史数据中以供下一次循环使用
history.append(test[i])
将“history.append(test[i])”移到循环顶部,在调用model_predict之前,将开始添加test_x值,并考虑test_x的最后一个条目。
你觉得呢?
它在循环的末尾,因为在前向验证期间,我们希望在进行预测后添加“观测值”。
这确实会让您错过最后一个观测值。
你好 Jason,
我们可以对多变量时间序列数据使用GRID SEARCH CV吗?
是的,但您必须自己实现,因为CV对于时间序列无效,而您必须使用前向验证。
你好Jason。我经常关注您的指南,我有一个关于您在这里的回答的问题。据我所知,GridsearchCV由于交叉验证消除了样本顺序的依赖性而不能用于时间序列数据。但是,如果我使用KerasRegressor(就像您在另一篇精彩文章中使用KerasClassifier一样)作为GridsearchCV函数的包装器,然后“破解”该函数以不使用交叉验证,正如这篇帖子所建议的那样:https://stackoverflow.com/questions/44636370/scikit-learn-gridsearchcv-without-cross-validation-unsupervised-learning
人们只需将cv参数设置为:cv=ShuffleSplit(test_size=0.20, n_splits=1)
这听起来是可行的,但我更愿意为时间序列数据编写自己的GridSearchCV版本,这样意图就更清楚了。时间序列的交叉验证方式有点不同。因此,看到您尝试这个我并不感到惊讶。
谢谢Jason…………。
不客气。
嗨,Jason,
感谢您的建议。我发现您推荐的通用框架很有帮助。
> # 网格搜索配置
> def grid_search(data, cfg_list, n_test)
> # 评估配置
> scores = scores = [repeat_evaluate(data, cfg, n_test) for cfg in cfg_list]
> # 按误差升序排序配置
> scores.sort(key=lambda tup: tup[1])
> return scores
“scores = scores =”这一行有什么意义吗?我在您的帖子中经常看到这种格式,但不确定赋值是否重复,或者我是否遗漏了什么。
不,看起来像是一个笔误。
谢谢,已修正。
你好。感谢您的精彩教程。但是,我对history感到困惑。对于MLP代码,似乎在前向验证的预测中只使用了history中的最后n_input个样本。
在第一个循环迭代中,使用了训练数据最后n_input个样本。然后对于每次其他迭代,使用前n_input个测试样本。
如果是这样,为什么history必须初始化为整个训练集?而且,为什么我们不直接使用测试数据来计算误差而不使用history呢?
我们正在使用前向验证,您可以在这里了解更多信息
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
你好,感谢您的帖子,我想问一下,我将为时间序列预测做一个LSTM神经网络。那么,我的问题是,我是否可以训练一个模型并在所有预测中使用它?输入数据每次可能不同(输入数据量),或者我是否需要为新数据每次都训练一个新模型?
尝试一下,看看它是否适合您的数据集。
你好Jason!我有两个关于CNN的问题(我正在使用迁移学习后得到的CNN)
我花了好几天时间试图理解如何为CNN进行网格搜索,但我不知道如何将您的代码用于我的图像数据集。
是否也可以使用网格搜索来优化学习率?
非常感谢您的信息
是的,您可以,也许这会有所帮助
https://machinelearning.org.cn/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
那么,关于使用图像来训练网络而不是CSV文件呢?
这应该不是问题,它们都只是数据数组。
你好Jason,我喜欢这篇帖子。您能否以图表形式向我展示这篇帖子中使用的LSTM网络架构?
您可以通过调用model.summary()来总结模型,您也可以创建图表。在此了解更多信息
https://machinelearning.org.cn/visualize-deep-learning-neural-network-model-keras/
你好,Jason!
1. 根据您的经验,您将如何使用自动化超参数调整,您认为它是一个好选择吗?
我听说过 Amazon SageMaker、Comet.ml、Cloud ML 等,甚至还有 Hyperopt 或 SMAC 等库。
2. 对您来说,最佳选择是什么,为什么?
非常感谢您所做的一切。
3. 另外,以下哪种方法更好
– Tree Parzen Estimator (TPE)
– 贝叶斯优化(高斯过程代理)
– Sequential Model-based Algorithm Configuration (SMAC)
– 随机森林回归
它们都不同。也许可以在您的问题上测试它们,看看哪种最适合您的特定数据集。
我自己不使用它们,而是自己进行网格搜索。
嗨,Jason!
首先,我很高兴这个网站的存在!谢谢您!我正在攻读硕士学位,研究时间序列,但对前向验证有一些疑问。
我们可以运行类似的前向交叉验证并提取每个 k 折的信息吗?
不,k 折交叉验证不适用于时间序列。
这是一个很好的练习。请问您是否有用于多变量的 MLP 代码?拜托,我急需,需要为每个变量提供不同的窗口。非常感谢。您帮了我很多。
是的,有很多例子。您可以在这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason,
感谢您的伟大贡献。
我在将 n_outs 更改为 2 时遇到了问题,收到了以下错误:
检查输入时出错:预期 dense_7_input 的形状为 (12,),但得到的是形状为 (13,) 的数组
您能否谈谈 n_out 大于 1 的情况?
再次感谢
抱歉,我没有能力调试这个更改。
感谢您的帖子。我对实现深度 Q 学习时间序列网格搜索感兴趣,我将环境(框架)作为调整不同参数,状态作为观测值,测试集作为搜索。最佳行动路径将是最佳分数吗?是否可以实现?您能给我一些关于如何实现深度 Q 学习时间序列的思路吗?
抱歉,我没有关于这个主题的教程。
你好 Jason
您能否查看我在以下链接中的问题?
https://stackoverflow.com/questions/59248081/how-to-tune-the-hyperparameters-for-time-series-data-using-models-built-with-pyt
抱歉,我无法回答 Stack Overflow 上的问题。
也许您可以将您的问题概括为一两句话?
你好 Jason,
谢谢你的回复!您在这里所做的是,对于一种配置,您会重复评估 10 次并计算此配置的分数平均值。此外,在一种配置的每次评估中,您会通过查看过去 12 个月来预测一个时间步,然后包括该时间步来预测下一个时间步,依此类推(使用历史记录)。
但就像在此链接中一样,https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/,它说您不仅包括该时间步,还会重新训练该模型并预测下一个时间步,而这在您的情况下找不到。
此外,在我的情况下,我的数据已经被过去 5 天的窗口处理了,我需要用它来预测当天的交易信号——上涨/下跌,这样我就不需要历史记录了。
最后,我的问题是,如果我需要在这些窗口化数据上调整超参数,那么我不需要历史记录,但该如何进行分割?我能否一次性预测测试集中的多个窗口,然后进行滚动或扩展分析?例如,我有 4 年的数据,那么训练 1.5 年的数据,预测 6 个月,然后将这 6 个月的数据包含进来训练,并为接下来的 6 个月进行测试,依此类推,就像扩展分析一样。这样,一个配置会有 5-6 个模型,我将从所有模型中获得分数并对其进行平均。
是的,我为了性能原因跳过了重新训练——这很慢。您可以根据需要重新训练。
以与教程中相同的方式测试每组超参数——例如,在测试数据子集上进行前向验证。测试集的大小由您决定,确保它能代表您打算如何使用最终模型。
嗨,Jason,
感谢这篇教程,我喜欢您设置解决方案的方式。
我有一些关于 LSTM 部分的问题
1.) 为什么我们在将数据分割成训练/测试后进行差分?难道不应该先进行差分吗?
2.) 更改差分和输入参数会影响验证数据集的长度。您是否期望这对 RMSE 分数产生混淆影响?
谢谢
谢谢。
我不记得了,也许是偏好。是的,用其他方式可能更容易。
是的,模型依赖于数据的呈现方式。
嗨,Jason,
很棒的帖子。我还购买了您的时间序列预测书籍。我正在寻找关于时间序列聚类和预测的建议。我工作的公司有 15 万客户,他们供应电力。他们希望为每个客户构建模型来预测他们的消费需求。我研究数据已经几个月了,每个客户的消费数据非常相似。我尝试对它们进行聚类,但创建多个集群非常非常困难。同时,为 15 万个客户构建模型也不实际。您有什么一般性建议或想写一篇关于多个产品/客户的时间序列预测的帖子吗?
谢谢你
这听起来像一个很棒的项目。这里的建议可能会给您一些想法(将“网站”替换为“客户”)
https://machinelearning.org.cn/faq/single-faq/how-to-develop-forecast-models-for-multiple-sites
感谢您的回复。这确实是一个有趣的项目,但非常有挑战性。我正在评论您的建议。
为每个站点开发一个模型。(150k 个模型似乎不可能)
为一组站点开发一个模型。(我尝试使用 scipy.cluster.hierarchy 进行分组,但它们似乎都形成了一个组。所以帮助不大)
为所有站点开发一个模型。(是的,这似乎没问题,但每个客户都是不同的,他们的使用模式也不同,而公司对此不感兴趣 🙁)
上述方法的混合。
上述方法的集成。
您还有其他建议吗?或者有什么书或参考资料可以查看?
再次感谢
不客气。
在测试之前不要排除想法,计算成本非常便宜。
尝试逻辑分组,例如,人类类别。发挥创意!
目前没有关于这方面的书。
您说得对,计算成本很低。我做了一些快速搜索,发现了一些相关的参考资料。我希望像我一样的人能从中受益。
https://otexts.com/fpp2/hierarchical.html
https://stats.stackexchange.com/questions/389291/strategies-for-time-series-forecasting-for-2000-different-products
https://stats.stackexchange.com/questions/344705/product-demand-forecasting-for-thousands-of-products-across-multiple-stores
https://stats.stackexchange.com/questions/371295/training-one-model-to-work-for-many-time-series
感谢分享。
嗨,Jason,
由于我是初学者,您能否在这篇教程中也包含 LSTM 的学习率?谢谢。
感谢您的建议,这可能也有帮助
https://machinelearning.org.cn/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
你好 Jason,我有一个问题
为什么在 LSTM 层中使用激活函数 ‘relu’,因为它内部已经有三个激活函数(sigmoid 和 then)?
谢谢你
我们用 relu 替换了单元/层的输出激活。
您不必这样做,这是您的选择。
明白了,谢谢您的回复。
例如,如果我这样做
model = Sequential()
model.add(LSTM(n_nodes, activation=’relu’, input_dim=n_input))
model.add(Dense(1), activation=’linear’)
model.compile(loss=’mse’, optimizer=’adam’)
说输出我将使用线性激活,但 LSTM 我将使用 'relu'(替换了内部的 sigmoid 和 tahn),这是否正确?
是的。
嗨,Jason,
非常好的教程。我想在网络架构方面进行更多探索。但我发现调整 LSTM 层与其他超参数不同,因为这不仅仅是简单地调整一个值,还需要声明每一层,如果我没记错的话。
如果您能分享一篇关于调整隐藏层的教程或参考资料,我将非常感激。
谢谢。
谢谢。
是的。您可以通过单独的脚本或 for 循环手动测试每种不同的架构。这可能会有帮助
https://machinelearning.org.cn/how-to-grid-search-deep-learning-models-for-time-series-forecasting/
你好 Jason,
我正在处理一个时间序列问题。我有过去 5 年的历史数据,但从 2020 年 4 月到 2020 年 6 月的数据丢失了,因为在 COVID-19 封锁期间企业关闭了。因此,这里有 3 个月的日数据缺失。像 KNN 这样的传统插补策略是否适用于这么长的时间范围?您的建议是什么?
提前感谢您的回答。
不,您可能需要从去年同期复制,或者保留上一期的观测值。
嗨,Jason,
很棒的教程,谢谢!我一直在为多元 LSTM 网格搜索而苦苦挣扎,因为我对编程方面相当陌生。很难找到在线的多元示例。您有什么建议可以将您的示例转换为具有许多特征的多元示例吗?
感谢您的帮助和您的教程,这太棒了!
提前感谢您!
从上面的示例开始,并将模型更改为多元。
此外,这些教程也可能有帮助
https://machinelearning.org.cn/start-here/#deep_learning_time_series
谢谢 Jason!感谢您的快速回复。
不客气。
你好 Jason,感谢您出色的教程。
我有一个关于单变量时间序列的网格搜索多步预测(步长=3)的问题。
当我为我的问题使用您的网格搜索时,我在 walk_forward_validation(data, n_test, cfg) 中收到此错误:
“y_true 和 y_pred 的输出数量不同 (1!=3)”。
def walk_forward_validation(data, n_test, cfg)
predictions = list()
# 分割数据集
train, test = train_test_split(data, n_test)
# 拟合模型
model = model_fit(train, cfg)
# 使用训练数据集初始化历史数据
history = [x for x in train]
# 遍历测试集中的每个时间步
for i in range(len(test))
# 拟合模型并对历史数据进行预测
yhat = model_predict(model, history, cfg)
# 将预测结果存储到预测列表中
predictions.append(yhat)
# 将实际观测值添加到历史数据中以供下一次循环使用
history.append(test[i])
# 估计预测误差
error = measure_rmse(test, predictions)
print(‘ > %.3f’ % error)
return error
您能否给我一些建议?
很遗憾听到这个消息,这表明您的预测和测试数据在观测数量上不匹配,您需要更改/调试您的代码。
很棒的帖子!您将如何处理多个商店的销售预测问题?您是为每个商店进行超参数调优然后循环遍历所有商店(这样您将为每个商店设置 1 套参数)?还是将所有商店合并到一个包含商店 ID 的数据框中,然后一次性进行调优?
这取决于您的问题,两者都有意义。所以您最好在您的情况下测试哪种方法更准确。
你好,很棒的教程!
有没有办法在网格搜索完成后保存最佳模型权重?如果我使用 ModelCheckpoint 作为回调,它只会保存最后一个网格搜索迭代中的最佳性能模型,但这不能保证是最佳的。
我之所以这样问,是因为出于某种原因,即使我设置了随机种子并且保存了最佳性能参数的值,当我用相同的数据重新拟合它时,我得到的预测仍然不同。
最好在网格搜索后重新训练模型,因为网格搜索是为了帮助您评估模型设计,而不是创建永久使用的模型。但如果您坚持,您需要修改 walk_forward_validation() 函数,因为它是在函数返回后创建但丢弃模型的地方。
你好!非常感谢您的工作和教程!
我目前正在处理一个有 50 个样本的模型。我不确定我是否正确理解了前向验证的概念。我是否需要进行训练-验证-测试分离,然后对训练-验证数据应用前向验证以获取超参数?然后对训练-测试数据应用前向测试?
因为从我的理解来看,通过使用前向验证,您既调整了超参数模型,又测试了模型,所以我们只需要进行训练-测试分离?
哪种选择最好?
提前感谢你
你好 J.LLOP……以下内容可能对您感兴趣
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
你好,Jason
一篇精彩且鼓舞人心的文章……就像您网站上的大多数文章一样。
嗯,问题是,如果模型不会在 walk_forward_validation() 的 for 循环中进行重新拟合,我认为这个过程可以简化,让我用一个虚构的例子来解释。
series = [0,1,2,3,4,5,6,7,8,9]
series_to_supervised(series, n_in=3, n_out=1)
X, y
012, 3
123, 4
234, 5
345, 6
456, 7
567, 8
678, 9
train_test_split(X, y, n_test=3)
X_train, y_train
012, 3
123, 4
234, 5
345, 6
X_test, y_test
456, 7
567, 8
678, 9
walk_forward_validation(X, y, n_test=3)
X_train, y_train, X_test, y_test = train_test_split(X, y, n_test)
fit_model = model.fit(X_train, y_train)
predictions = fit_model.predict(X_test)
error = measure_rmse(y_test, predictions)
就是这样,您怎么看?
非常感谢。
JM Vericat
你好 JM……请将您的帖子精简为一个问题,以便我能更好地帮助您。
你好,James,
问题很简单,鉴于模型只拟合一次,这个简化程序是否适用于时间序列评估?
这就是为什么我提供一个虚构的例子来最好地解释这个问题。
谢谢你。
此致
JM Vericat
嗨,Jason,
感谢您分享您的专业知识,并对像我一样的学习者保持开放的态度,以便访问。
特别感谢这篇教程。
我一直收到 ‘score_model’、‘n_diff’ 和 ‘config’ 未定义的错误,我肯定遗漏了什么,您能帮忙吗?
你好 Jay……感谢提问。
我很想帮忙,但我实在没有能力为您调试代码。
我很乐意提出一些建议
考虑将代码积极削减到最低要求。这将帮助您隔离问题并专注于它。
考虑将问题简化为一个或几个简单的例子。
考虑寻找其他可行的类似代码示例,并慢慢修改它们以满足您的需求。这可能会暴露您的失误。
考虑在 StackOverflow 上发布您的问题和代码。
相信我,在决定打扰您之前,我已经尝试了所有这些建议。
这与我必须导入的任何库有关吗?
你好,
谢谢您的教程。
在 walk forward validation 函数定义中,您不应该在 for 循环的里面而不是外面调用 model_fit() 函数吗?
# 拟合模型
model = model_fit(train, cfg)
for i in range(len(test))
这个 model_fit() 应该在 for 循环内,因为预测被追加到历史记录中,这将作为 model_fit() 函数的训练。在外面调用它会破坏前向验证概念的全部目的。
————————————————————————————————————————————–
在这篇教程 https://machinelearning.org.cn/random-forest-for-time-series-forecasting 中,
random_forest_forecast() 函数在 for 循环内被调用,该函数进行拟合和预测。
# 来自上面这篇教程的代码
def walk_forward_validation(data, n_test)
for i in range(len(test))
yhat = random_forest_forecast(history, testX)
如果我的理解有误或指出了这一点,请纠正我。
感谢分享——我一直在浏览您的网站一段时间了——
它包含很多专业内容——太棒了!
Diego,您太客气了!我们感谢您的反馈和支持。