OpenCV库包含一个模块,实现了用于机器学习的k近邻算法。
在本教程中,您将学习如何应用OpenCV的k近邻算法来分类手写数字。
完成本教程后,您将了解:
- k近邻算法的一些最重要的特点。
- 如何在OpenCV中使用k近邻算法进行图像分类。
通过我的书《OpenCV 机器学习》启动您的项目。它提供了带有可用代码的自学教程。
让我们开始吧。

使用 OpenCV 进行 K-近邻分类
照片作者:Gleren Meneghin,部分权利保留。
教程概述
本教程分为两部分;它们是
- 回顾k近邻算法的工作原理
- 在OpenCV中使用k近邻进行图像分类
先决条件
本教程假设您已熟悉以下内容:
回顾k近邻算法的工作原理
k近邻(kNN)算法已经在Jason Brownlee的这篇教程中得到了很好的解释,但让我们先来回顾一下他教程中的一些要点。
- kNN算法不涉及任何学习。它只是存储并使用整个训练数据集作为其模型表示。因此,kNN也被称为懒惰学习算法。
- 由于存储了整个训练数据集,因此保持数据集的整洁、经常用新数据更新、并尽可能避免异常值是有意义的。
- 新的实例通过搜索整个训练数据集,根据选择的距离度量找到最相似的实例来进行预测。距离度量的选择通常基于数据的属性。
- 如果kNN用于解决回归问题,则通常使用k个最相似实例的平均值或中位数来生成预测。
- 如果kNN用于解决分类问题,则可以通过k个最相似实例中出现频率最高的类别来生成预测。
- 可以通过尝试不同的值并观察对问题效果最好的值来调整k的值。
- kNN算法的计算成本随着训练数据集的大小而增加。kNN算法在输入数据的维度增加时也会遇到困难。
在OpenCV中使用k近邻进行图像分类
在本教程中,我们将考虑分类手写数字的应用。
在之前的教程中,我们已经看到OpenCV提供了图像digits.png,该图像由5,000个20x20像素的子图像组成,“拼贴”而成,每个子图像都包含一个0到9的手写数字。
我们还了解了如何将数据集图像转换为特征向量表示,然后将它们输入到机器学习算法中。
我们将把OpenCV的数字数据集分成训练集和测试集,将它们转换为特征向量,然后使用这些特征向量来训练和测试kNN分类器以分类手写数字。
注意:我们之前提到kNN算法不涉及任何训练/学习,但我们将使用训练数据集来区分将用于模型表示的图像和稍后将用于测试的图像。
让我们开始加载OpenCV的数字图像,将其分成训练集和测试集,并使用方向梯度直方图(HOG)技术将它们转换为特征向量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from cv2 import imshow, waitKey from digits_dataset import split_images, split_data from feature_extraction import hog_descriptors # 加载完整的训练图像 img, sub_imgs = split_images('Images/digits.png', 20) # 检查是否正确加载了图像 imshow('Training image', img) waitKey(0) # 检查子图像是否正确分割 imshow('Sub-image', sub_imgs[0, 0, :, :].reshape(20, 20)) waitKey(0) # 将数据集分为训练集和测试集 train_imgs, train_labels, test_imgs, test_labels = split_data(20, sub_imgs, 0.5) # 使用HOG技术将训练和测试图像转换为特征向量 train_hog = hog_descriptors(train_imgs) test_hog = hog_descriptors(test_imgs) |
接下来,我们将初始化一个kNN分类器。
|
1 2 3 |
from cv2 import ml knn = ml.KNearest_create() |
然后用数据集的训练集对其进行‘训练’。对于数据集的训练集,我们可以使用图像像素本身的强度值(根据函数的预期输入,将其转换为32位浮点值)
|
1 |
knn.train(float32(train_imgs), ml.ROW_SAMPLE, train_labels) |
或者使用HOG技术生成的特征向量。在上一节中,我们提到kNN算法在处理高维数据时会遇到困难。使用HOG技术生成更紧凑的图像数据表示有助于缓解这个问题。
|
1 |
knn.train(train_hog, ml.ROW_SAMPLE, train_labels) |
让我们继续本教程,利用HOG特征向量。
训练好的kNN分类器现在可以用来测试数据集的测试集,然后通过计算匹配真实值的正确预测百分比来计算其准确率。目前,k的值将经验性地设置为3。
|
1 2 3 4 5 6 |
from numpy import sum k = 3 ret, result, neighbours, dist = knn.findNearest(test_hog, k) accuracy = (sum(result == test_labels) / test_labels.size) * 100 |
然而,正如我们在上一节中提到的,通常的做法是通过尝试不同的值并观察最适合当前问题的值来调整k的值。我们也可以尝试使用不同的比例值分割数据集,看看它们对预测准确率的影响。
为此,我们将上面的kNN分类器代码放入一个嵌套的for循环中,外层循环遍历不同的比例值,内层循环遍历不同的k值。在内层循环中,我们还将用计算出的准确率值填充一个字典,以便稍后使用Matplotlib绘制它们。
我们还将包含一个检查,以确保我们加载了正确的图像并正确地将其分割成子图像。为此,我们将使用OpenCV的imshow方法显示图像,然后是waitKey,输入为零,它将停止并等待键盘事件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
from cv2 import imshow, waitKey, ml from numpy import sum from matplotlib.pyplot import plot, show, title, xlabel, ylabel, legend from digits_dataset import split_images, split_data from feature_extraction import hog_descriptors # 加载完整的训练图像 img, sub_imgs = split_images('Images/digits.png', 20) # 检查是否正确加载了图像 imshow('Training image', img) waitKey(0) # 检查子图像是否正确分割 imshow('Sub-image', sub_imgs[0, 0, :, :].reshape(20, 20)) waitKey(0) # 定义不同的训练-测试分割 ratio = [0.5, 0.7, 0.9] for i in ratio: # 将数据集分为训练集和测试集 train_imgs, train_labels, test_imgs, test_labels = split_data(20, sub_imgs, i) # 使用HOG技术将训练和测试图像转换为特征向量 train_hog = hog_descriptors(train_imgs) test_hog = hog_descriptors(test_imgs) # 初始化一个kNN分类器并用训练数据进行训练 knn = ml.KNearest_create() knn.train(train_hog, ml.ROW_SAMPLE, train_labels) # 初始化一个字典来存储比例和准确率值 accuracy_dict = {} # 使用对应于'k'的值作为键来填充字典 keys = range(3, 16) for k in keys: # 在测试数据上测试kNN分类器 ret, result, neighbours, dist = knn.findNearest(test_hog, k) # 计算准确率并打印 accuracy = (sum(result == test_labels) / test_labels.size) * 100 print("Accuracy: {0:.2f}%, Training: {1:.0f}%, k: {2}".format(accuracy, i* 100, k)) # 使用对应于准确率的值来填充字典 accuracy_dict[k] = accuracy # 绘制准确率值与'k'值的关系图 plot(accuracy_dict.keys(), accuracy_dict.values(), marker='o', label=str(i * 100) + '%') title('k近邻模型的准确率') xlabel('k') ylabel('准确率') legend(loc='upper right') show() |
绘制不同比例和不同k值下的预测准确率,可以更深入地了解这些不同值对当前应用预测准确率的影响。
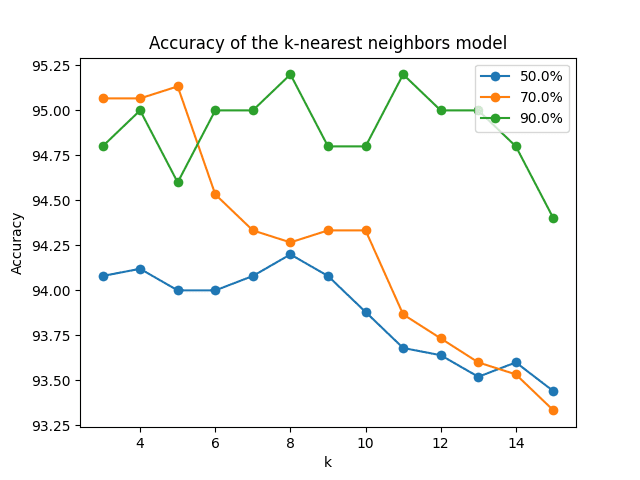
不同训练集分割和不同'k'值下的预测准确率的线图
尝试使用不同的图像描述符,并调整所选算法的各种参数,然后再将数据输入kNN算法,并研究您更改后kNN的输出。
想开始学习 OpenCV 机器学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
书籍
- 使用 Python 精通 OpenCV 4, 2019.
网站
- OpenCV,https://opencv.ac.cn/
- OpenCV KNearest类,https://docs.opencv.ac.cn/4.7.0/dd/de1/classcv_1_1ml_1_1KNearest.html
总结
在本教程中,您学习了如何应用OpenCV的k近邻算法来分类手写数字。
具体来说,你学到了:
- k近邻算法的一些最重要的特点。
- 如何在OpenCV中使用k近邻算法进行图像分类。
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
开始使用 OpenCV 进行机器学习!

学习如何在图像处理项目中使用机器学习技术
...以高级方式使用 OpenCV,超越像素处理
在我的新电子书中探索如何实现
OpenCV 机器学习
它提供带有所有可用 Python 代码的自学教程,让您从新手成长为专家。它为您提供了
逻辑回归、随机森林、支持向量机、k 均值聚类、神经网络等等……所有这些都使用 OpenCV 中的机器学习模块






暂无评论。