我们已经熟悉了Transformer注意力机制在神经机器翻译中实现的自注意力概念。现在我们将把重点转移到Transformer架构本身的细节,以发现如何在不依赖循环和卷积的情况下实现自注意力。
在本教程中,您将了解Transformer模型的网络架构。
完成本教程后,您将了解:
- Transformer 架构如何在没有循环和卷积的情况下实现编码器-解码器结构
- Transformer 编码器和解码器如何工作
- Transformer 自注意力与循环层和卷积层的使用比较
通过我的书《使用注意力构建 Transformer 模型》来启动您的项目。它提供了自学教程和可运行代码,指导您构建一个功能完备的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。
Transformer 模型
照片由 Samule Sun 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- Transformer 架构
- 编码器
- 解码器
- 总结:Transformer 模型
- 与循环层和卷积层的比较
先决条件
本教程假设您已熟悉以下内容:
Transformer 架构
Transformer 架构遵循编码器-解码器结构,但不依赖循环和卷积来生成输出。
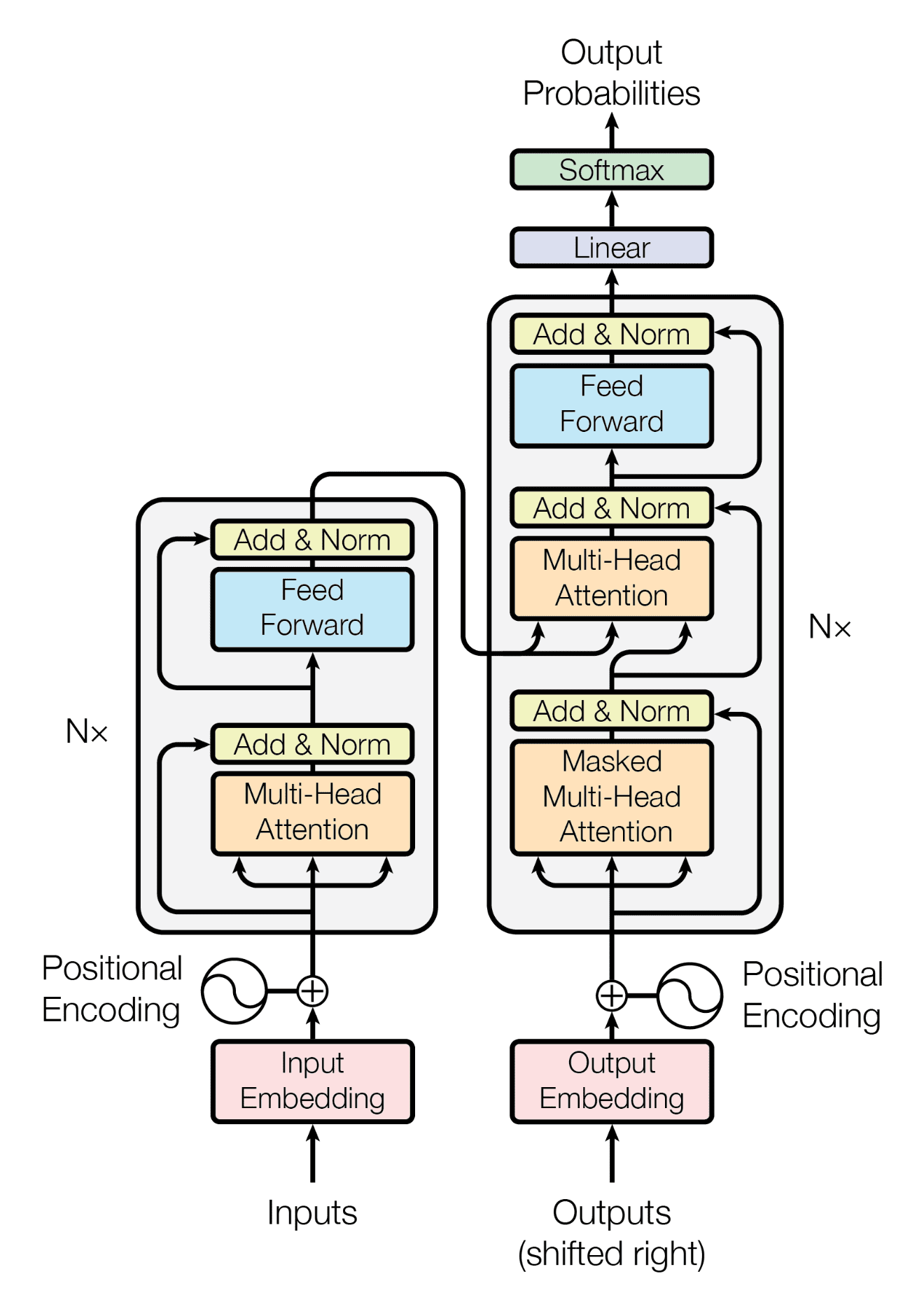
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
简而言之,Transformer 架构左半部分的编码器任务是将输入序列映射到一系列连续表示,然后将其输入到解码器。
架构右半部分的解码器接收编码器的输出以及前一个时间步的解码器输出以生成输出序列。
在每个步骤中,模型都是自回归的,在生成下一个符号时,将先前生成的符号作为附加输入进行消费。
—— 《Attention Is All You Need》,2017。
编码器
Transformer 架构的编码器块
摘自“Attention Is All You Need”
编码器由 $N$ = 6 个相同的层堆叠而成,每个层由两个子层组成
- 第一个子层实现多头自注意力机制。您已经看到多头机制实现了 $h$ 个头,这些头接收查询、键和值的(不同)线性投影版本,每个头并行生成 $h$ 个输出,然后用于生成最终结果。
- 第二个子层是一个全连接的前馈网络,由两个线性变换组成,中间带有 ReLU(修正线性单元)激活函数。
$$\text{FFN}(x) = \text{ReLU}(\mathbf{W}_1 x + b_1) \mathbf{W}_2 + b_2$$
Transformer 编码器的六个层对输入序列中的所有单词应用相同的线性变换,但*每个*层都采用不同的权重 ($\mathbf{W}_1, \mathbf{W}_2$) 和偏置 ($b_1, b_2$) 参数来完成此操作。
此外,这两个子层都包含一个残差连接。
每个子层后面还有一个归一化层 $\text{layernorm}(.) $,它归一化了子层输入 $x$ 和子层本身生成的输出 $\text{sublayer}(x)$ 之间的和。
$$\text{layernorm}(x + \text{sublayer}(x))$$
一个需要牢记的重要考虑因素是,Transformer 架构由于不使用循环,因此无法固有地捕获序列中单词相对位置的任何信息。此信息必须通过向输入嵌入引入*位置编码*来注入。
位置编码向量与输入嵌入具有相同的维度,并使用不同频率的正弦和余弦函数生成。然后,它们简单地与输入嵌入求和,以*注入*位置信息。
解码器
Transformer 架构的解码器块
摘自“Attention Is All You Need”
解码器与编码器有几个相似之处。
解码器也由 $N$ = 6 个相同的层堆叠而成,每个层由三个子层组成
- 第一个子层接收解码器堆栈的先前输出,用位置信息增强它,并在其上实现多头自注意力。虽然编码器被设计为*无论*单词在序列中的位置如何,都关注输入序列中的所有单词,但解码器被修改为*只*关注前面的单词。因此,对位置 $i$ 的单词的预测只能依赖于序列中在该单词之前出现的已知输出。 在多头注意力机制(并行实现多个单一注意力函数)中,这是通过在矩阵 $\mathbf{Q}$ 和 $\mathbf{K}$ 的标量乘法产生的值上引入一个掩码来实现的。这种掩码通过抑制否则将对应于非法连接的矩阵值来实现
$$
\text{mask}(\mathbf{QK}^T) =
\text{mask} \left( \begin{bmatrix}
e_{11} & e_{12} & \dots & e_{1n} \\
e_{21} & e_{22} & \dots & e_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
e_{m1} & e_{m2} & \dots & e_{mn} \\
\end{bmatrix} \right) =
\begin{bmatrix}
e_{11} & -\infty & \dots & -\infty \\
e_{21} & e_{22} & \dots & -\infty \\
\vdots & \vdots & \ddots & \vdots \\
e_{m1} & e_{m2} & \dots & e_{mn} \\
\end{bmatrix}
$$
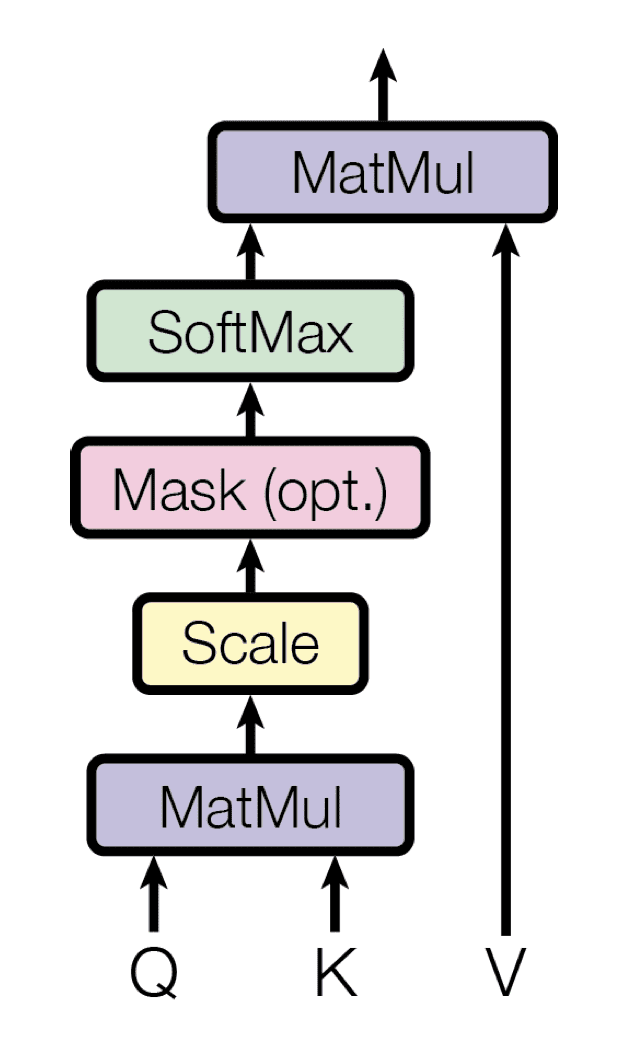
解码器中的多头注意力实现了多个被掩码的单注意力函数
摘自“Attention Is All You Need”
遮蔽使得解码器是单向的(与双向编码器不同)。
—— 《Python 高级深度学习》,2019 年。
- 第二层实现了一个多头自注意力机制,类似于编码器第一个子层中实现的机制。 在解码器侧,这个多头机制接收来自前一个解码器子层的查询,以及来自编码器输出的键和值。这允许解码器关注输入序列中的所有单词。
- 第三层实现了一个全连接的前馈网络,类似于编码器第二个子层中实现的网络。
此外,解码器侧的三个子层也都有残差连接,并且后面跟着一个归一化层。
位置编码也以与之前为编码器解释的相同方式添加到解码器的输入嵌入中。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
总结:Transformer 模型
Transformer 模型的运行方式如下
- 组成输入序列的每个单词都被转换为 $d_{\text{model}}$ 维嵌入向量。
- 表示输入单词的每个嵌入向量通过将其(逐元素)与相同 $d_{\text{model}}$ 长度的位置编码向量求和来增强,从而将位置信息引入输入。
- 增强后的嵌入向量被输入到由上述两个子层组成的编码器块中。由于编码器关注输入序列中的所有单词,无论它们是在所考虑单词之前还是之后,因此 Transformer 编码器是*双向的*。
- 解码器在时间步 $t-1$ 接收其自身的预测输出词作为输入。
- 解码器的输入也以与编码器侧相同的方式通过位置编码进行增强。
- 增强后的解码器输入被输入到由上述解码器块组成的三个子层中。第一个子层应用掩码以阻止解码器关注后续单词。在第二个子层,解码器还接收编码器的输出,这使得解码器现在可以关注输入序列中的所有单词。
- 解码器的输出最终通过一个全连接层,然后是一个 softmax 层,以生成输出序列中下一个单词的预测。
与循环层和卷积层的比较
Vaswani 等人(2017)解释说,他们放弃使用循环和卷积的动机基于几个因素
- 自注意力层在较短序列长度下比循环层更快,并且在非常长的序列长度下可以限制为仅考虑输入序列中的一个邻域。
- 循环层所需的顺序操作数量取决于序列长度,而自注意力层的这个数量保持不变。
- 在卷积神经网络中,核宽度直接影响输入和输出位置对之间建立的长期依赖关系。跟踪长期依赖关系需要使用大核或堆叠卷积层,这可能会增加计算成本。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019.
论文
- 注意力就是你所需要的一切, 2017.
总结
在本教程中,您了解了 Transformer 模型的网络架构。
具体来说,你学到了:
- Transformer 架构如何在没有循环和卷积的情况下实现编码器-解码器结构
- Transformer 编码器和解码器如何工作
- Transformer 自注意力与循环层和卷积层的比较
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






嗨,Stefania Cristina,您能否在从主干网络中获取卷积特征后立即使用编码器块进行目标检测任务,而排除解码器部分?
嗨,Kelvin,在计算机视觉领域,通常使用的是编码器块,它并行接收多个图像块,以及相应的位置编码。编码器输出通常会传递给 MLP 进行分类。但是,我也遇到过编码器块前面有卷积层,这些层首先提取图像特征,然后再将它们传递给编码器的架构。
嗨,Stefania Cristina,我可以使用 Transformer 模型进行时间序列分类吗?如果可以,请指导我编码。我是这个领域的新手。
谢谢
嗨,Saeid……您可能会对以下内容感兴趣
https://towardsdatascience.com/multi-class-classification-with-transformers-6cf7b59a033a
文中提到:“在卷积神经网络中,核宽度直接影响输入和输出位置对之间可以建立的长期依赖关系。跟踪长期依赖关系需要使用大核,或堆叠卷积层,这可能会增加计算成本。”
我不确定我是否正确理解了这段话。Transformer 模型接收顺序输入,例如文本、音频等。同样,在 CNN 中使用文本音频类型的输入时,我们使用一维卷积,它使用宽度始终为 1 的单维核。在这种情况下,我们只配置核的高度,我大多使用 4 或 7。
在我看来,我认为这个说法不是一个有效的比较。
感谢这篇文章
嗨,Furkan。注意力机制背后的理念是在输入和输出之间建立*全局依赖关系*。这意味着预测输出值的过程将考虑全部输入数据(无论是文本形式还是图像形式等)。从这个意义上说,我们可以说 Transformer 可以捕捉长程依赖关系,无论是文本中相距较远的单词之间的依赖关系,还是图像中相距较远的像素之间的依赖关系等等。
用 Vaswani 等人的话说,“一个核宽度 $k < n$ 的单卷积层无法连接所有输入和输出位置对。这需要堆叠 $O(n/k)$ 个卷积层(在连续核的情况下)……”,其中 $n$ 是序列长度。在 CNN 中,感受野取决于核的大小。例如,如果想通过 CNN 捕捉图像中的长程依赖关系,就需要使用一个大的二维核(覆盖 $k \times k$ 像素的邻域)来尽可能扩大感受野,或者堆叠长序列的卷积层,这两种方法都可能计算成本高昂。在处理文本时,您将使用您提到的1D核,但是您的核宽度(您称之为“高度”)仍将定义您的感受野大小,这通常是序列中每个标记周围的局部邻域。
非常感谢,先生,这真的简明易懂!
请问,您能否解释一下使用 Transformer 进行图像分类的代码?
嗨,Imene…以下内容可能会让您感兴趣
https://paperswithcode.com/method/vision-transformer
感谢您的逐步讲解。您能否解释一下如何使用 Transformer 对数值数据进行预测和异常检测?
大多数资料都是专门针对 NLP 的
嗨,sara……以下资源是关于这个主题的一个很好的入门介绍
https://medium.com/@moussab.orabi/enable-transformers-with-anomaly-detection-in-high-order-multivariate-time-series-data-509a5df39151
“循环层所需的顺序操作数量取决于序列长度,而自注意力层的这个数量保持不变。”
——这说不通,考虑到 Transformer 模型本身在输入长度上是有限制的?Transformer 不允许以恒定的操作数量处理任意长的序列 🙂
嗨,Roman……您可能会对以下内容感兴趣
https://machinelearning.org.cn/the-transformer-attention-mechanism/
嗨,Roman,您提到的评论与其说是关于输入序列的长度,不如说是关于应用于输入的*操作数量*。引用 Vaswani 等人的话:“如表 1 所示,自注意力层以恒定数量的顺序执行操作连接所有位置,而循环层需要 O(n) 个顺序操作。”,其中 n 是输入序列长度。
查看 Vaswani 论文中的表 1,我们可以看到自注意力层的顺序操作次数是 O(1),这意味着它*不*是输入大小的函数,这与循环层的顺序操作次数相反。这是因为,当 Transformer 架构中的自注意力层以查询、键和值的形式接收其输入时,它将对它们应用一组固定数量的顺序操作,即:查询和键之间的点积乘法,然后是缩放(以及掩码,但这是可选的),softmax 归一化,以及与值进行最终的点积乘法(有关更多详细信息,请参阅 James 提供的链接)。
你好 Stefania,
非常感谢您这篇关于 Transformer 模型的精彩且易于理解的文章。然而,要将 Transformer 作为 seq2seq 模型使用,我很好奇如何为编码器和/或解码器添加约束。例如,约束可以是输出序列的预期长度。谢谢!
嗨,Rashedur……以下资源可能会让您感兴趣
https://machinelearning.org.cn/encoder-decoder-attention-sequence-to-sequence-prediction-keras/
嗨 James,
谢谢你的回复。实际上,我有一个基于 LSTM 的 seq2seq 模型来添加约束(例如,输出序列的长度)。现在我有兴趣使用 Transformer(TransformerEncoder 和 TransformerDecoder)来添加约束。但我不知道如何使用 Transformer 来实现。
@Stefania Cristina,我有一个小疑问。如果您能回答我的以下问题,我将不胜感激。
@任何人的回复都将不胜感激。
任务:“使用带有 Transformer 模型(例如 T5 基础模型)的 NLP 进行抽取式/抽象式文本摘要”
1. 尽管所有编码器和解码器在架构上是相同的,但在 Transformer 中拥有多个编码器和解码器块有什么好处?
2. 由于第一个编码器接收文本摘要任务中的输入句子,然后处理后的输入向量传输到第二个编码器,依此类推。那么,来自第一个编码器的这些输入向量在第二个及后续编码器中有什么变化?
3. 根据架构,最后一个编码器的输入向量表示传递到所有解码器,那么由于所有解码器都是堆叠的,每个解码器块中会发生什么计算?
4. 在英译英文本摘要中,输入到解码器块的是什么?是目标摘要吗?我有点困惑。如果目标摘要被输入到解码器,那么目标摘要输入和编码器输入之间会进行什么计算?
5. 解码器的哪个部分主要负责选择将成为最终摘要句子一部分的单词/句子?
如果任何人能帮助我理解这些问题,我将不胜感激。
提前感谢。
嗨,Hasan……请将您的问题缩小到一个,以便我们更好地帮助您。
嗨,Stefania,
Transformer 解码器是如何在不使用循环的情况下,基于所有先前预测的单词来预测其自身的单词的?
我看到在训练时,解码器迭代地使用最终的密集层预测下一个单词,这在训练中是并行完成的,但我不明白并行训练在这里是如何工作的。
问题
——输入嵌入是一个接一个地输入到编码器吗?
——构成编码器和解码器的相同层是并行的还是串行的(它们是分别处理输入的不同副本,还是顺序堆叠的)?
嗨,Dario……以下资源可能会让您感兴趣
https://machinelearning.org.cn/lstm-autoencoders/
在训练过程中,您有“输出”数据来喂给您的解码器。
但是,在验证或测试期间会发生什么?您不知道输出。
图片是高达模型而不是真正的变形金刚 🙂
嗨,Stefania,感谢您关于注意力、Transformer 等主题的教程。我是这个领域的新手,发现您的教程对于获得高层理解非常有帮助。您能否提供任何链接来解释查询、键、值是什么。谢谢。
嗨,Peter……以下资源希望能为您提供清晰的解释
https://stats.stackexchange.com/questions/421935/what-exactly-are-keys-queries-and-values-in-attention-mechanisms
你好。我们可以使用 Transformer 对时间序列数据进行预测吗?您能给我一些指导吗?