在第 1 部分,Transformer 模型中位置编码的温和介绍中,我们讨论了 Transformer 模型的位置编码层。我们还展示了如何在 Python 中自行实现此层及其功能。在本教程中,您将在 Keras 和 Tensorflow 中实现位置编码层。然后,您可以在完整的 Transformer 模型中使用此层。
完成本教程后,您将了解:
- Keras 中的文本向量化
- Keras 中的嵌入层
- 如何子类化嵌入层并编写您自己的位置编码层。
通过我的书使用注意力构建 Transformer 模型,启动您的项目。它提供了带有工作代码的自学教程,指导您构建一个功能齐全的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

Keras 中的 Transformer 位置编码层,第 2 部分
图片作者:Ijaz Rafi。保留部分权利
教程概述
本教程分为三个部分;它们是:
- Keras 中的文本向量化和嵌入层
- 在 Keras 中编写您自己的位置编码层
- 随机初始化和可调谐嵌入
- 来自《Attention Is All You Need》的固定权重嵌入
- 位置编码层输出的图形视图
导入部分
首先,让我们编写导入所有所需库的部分
|
1 2 3 4 5 6 |
import tensorflow as tf 从 tensorflow 导入 convert_to_tensor, string 从 tensorflow.keras.layers 导入 TextVectorization, Embedding, Layer 从 tensorflow.data 导入 Dataset import numpy as np import matplotlib.pyplot as plt |
文本向量化层
让我们从一组已经预处理和清理过的英语短语开始。文本向量化层创建一个单词字典,并将每个单词替换为其在字典中对应的索引。让我们看看如何使用文本向量化层映射这两个句子
- 我是一个机器人
- 你也是机器人
请注意,文本已经转换为小写,并删除了所有标点符号和文本中的噪声。接下来,将这两个短语转换为固定长度为 5 的向量。Keras 的 `TextVectorization` 层需要一个最大词汇量和输出序列的所需长度进行初始化。该层的输出是一个形状为
(句子数量,输出序列长度)
以下代码片段使用 `adapt` 方法生成词汇表。然后,它创建文本的向量化表示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
output_sequence_length = 5 vocab_size = 10 sentences = [["我是一个机器人"], ["你也是机器人"]] sentence_data = Dataset.from_tensor_slices(sentences) # 创建 TextVectorization 层 vectorize_layer = TextVectorization( output_sequence_length=output_sequence_length, max_tokens=vocab_size) # 训练该层以创建字典 vectorize_layer.adapt(sentence_data) # 将所有句子转换为张量 word_tensors = convert_to_tensor(sentences, dtype=tf.string) # 使用单词张量获取向量化短语 vectorized_words = vectorize_layer(word_tensors) print("词汇表: ", vectorize_layer.get_vocabulary()) print("向量化单词: ", vectorized_words) |
|
1 2 3 4 |
词汇表:['', '[UNK]', 'robot', 'you', 'too', 'i', 'am', 'a'] 向量化单词:tf.Tensor( [[5 6 7 2 0] [3 4 2 0 0]], shape=(2, 5), dtype=int64) |
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
嵌入层
Keras `Embedding` 层将整数转换为密集向量。此层将这些整数映射到随机数,这些随机数在训练阶段会进行调整。但是,您也可以选择将映射设置为一些预定义权重值(稍后显示)。要初始化此层,您需要指定要映射的最大整数值以及输出序列的长度。
词嵌入
让我们看看该层如何将 `vectorized_text` 转换为张量。
|
1 2 3 4 |
output_length = 6 word_embedding_layer = Embedding(vocab_size, output_length) embedded_words = word_embedding_layer(vectorized_words) print(embedded_words) |
输出已添加了一些注释,如下所示。请注意,每次运行此代码时,您都会看到不同的输出,因为权重是随机初始化的。

词嵌入。由于涉及随机数,此输出每次运行代码时都会不同。
位置嵌入
您还需要相应位置的嵌入。最大位置对应于 `TextVectorization` 层的输出序列长度。
|
1 2 3 4 |
position_embedding_layer = Embedding(output_sequence_length, output_length) position_indices = tf.range(output_sequence_length) embedded_indices = position_embedding_layer(position_indices) print(embedded_indices) |
输出如下所示

位置索引嵌入
Transformer 中位置编码层的输出
在 Transformer 模型中,最终输出是词嵌入和位置嵌入的总和。因此,当您设置两个嵌入层时,您需要确保两者的 `output_length` 相同。
|
1 2 |
final_output_embedding = embedded_words + embedded_indices print("最终输出: ", final_output_embedding) |
输出如下所示,并附有注释。同样,由于随机权重初始化,这与您运行代码的结果会有所不同。

添加词嵌入和位置嵌入后的最终输出
子类化 Keras 嵌入层
在实现 Transformer 模型时,您需要编写自己的位置编码层。这非常简单,因为基本功能已经为您提供了。这个Keras 示例展示了如何子类化 `Embedding` 层以实现您自己的功能。您可以根据需要向其中添加更多方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class PositionEmbeddingLayer(Layer): def __init__(self, sequence_length, vocab_size, output_dim, **kwargs): super(PositionEmbeddingLayer, self).__init__(**kwargs) self.word_embedding_layer = Embedding( input_dim=vocab_size, output_dim=output_dim ) self.position_embedding_layer = Embedding( input_dim=sequence_length, output_dim=output_dim ) def call(self, inputs): position_indices = tf.range(tf.shape(inputs)[-1]) embedded_words = self.word_embedding_layer(inputs) embedded_indices = self.position_embedding_layer(position_indices) return embedded_words + embedded_indices |
让我们运行这个层。
|
1 2 3 4 |
my_embedding_layer = PositionEmbeddingLayer(output_sequence_length, vocab_size, output_length) embedded_layer_output = my_embedding_layer(vectorized_words) print("来自 my_embedded_layer 的输出: ", embedded_layer_output) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
my_embedded_layer 的输出:tf.Tensor( [[[ 0.06798736 -0.02821309 0.00571618 0.00314623 -0.03060734 0.01111387] [-0.06097465 0.03966043 -0.05164248 0.06578685 0.03638128 -0.03397174] [ 0.06715029 -0.02453769 0.02205854 0.01110986 0.02345785 0.05879898] [-0.04625867 0.07500569 -0.05690887 -0.07615659 0.01962536 0.00035865] [ 0.01423577 -0.03938593 -0.08625181 0.04841495 0.06951572 0.08811047]] [[ 0.0163899 0.06895607 -0.01131684 0.01810524 -0.05857501 0.01811318] [ 0.01915303 -0.0163289 -0.04133433 0.06810946 0.03736673 0.04218033] [ 0.00795418 -0.00143972 -0.01627307 -0.00300788 -0.02759011 0.09251165] [ 0.0028762 0.04526488 -0.05222676 -0.02007698 0.07879823 0.00541583] [ 0.01423577 -0.03938593 -0.08625181 0.04841495 0.06951572 0.08811047]]], shape=(2, 5, 6), dtype=float32) |
Transformer 中的位置编码:《Attention Is All You Need》
P(k, 2i) &=& \sin\Big(\frac{k}{n^{2i/d}}\Big)\\
P(k, 2i+1) &=& \cos\Big(\frac{k}{n^{2i/d}}\Big)
\end{eqnarray}
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class PositionEmbeddingFixedWeights(Layer): def __init__(self, sequence_length, vocab_size, output_dim, **kwargs): super(PositionEmbeddingFixedWeights, self).__init__(**kwargs) word_embedding_matrix = self.get_position_encoding(vocab_size, output_dim) position_embedding_matrix = self.get_position_encoding(sequence_length, output_dim) self.word_embedding_layer = Embedding( input_dim=vocab_size, output_dim=output_dim, weights=[word_embedding_matrix], trainable=False ) self.position_embedding_layer = Embedding( input_dim=sequence_length, output_dim=output_dim, weights=[position_embedding_matrix], trainable=False ) def get_position_encoding(self, seq_len, d, n=10000): P = np.zeros((seq_len, d)) for k in range(seq_len): for i in np.arange(int(d/2)): denominator = np.power(n, 2*i/d) P[k, 2*i] = np.sin(k/denominator) P[k, 2*i+1] = np.cos(k/denominator) return P def call(self, inputs): position_indices = tf.range(tf.shape(inputs)[-1]) embedded_words = self.word_embedding_layer(inputs) embedded_indices = self.position_embedding_layer(position_indices) return embedded_words + embedded_indices |
接下来,我们设置所有内容来运行此层。
|
1 2 3 4 |
attnisallyouneed_embedding = PositionEmbeddingFixedWeights(output_sequence_length, vocab_size, output_length) attnisallyouneed_output = attnisallyouneed_embedding(vectorized_words) print("来自 my_embedded_layer 的输出: ", attnisallyouneed_output) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
my_embedded_layer 的输出:tf.Tensor( [[[-0.9589243 1.2836622 0.23000172 1.9731903 0.01077196 1.9999421 ] [ 0.56205547 1.5004725 0.3213085 1.9603932 0.01508068 1.9999142 ] [ 1.566284 0.3377554 0.41192317 1.9433732 0.01938933 1.999877 ] [ 1.0504174 -1.4061394 0.2314966 1.9860148 0.01077211 1.9999698 ] [-0.7568025 0.3463564 0.18459873 1.982814 0.00861763 1.9999628 ]] [[ 0.14112 0.0100075 0.1387981 1.9903207 0.00646326 1.9999791 ] [ 0.08466846 -0.11334133 0.23099795 1.9817369 0.01077207 1.9999605 ] [ 1.8185948 -0.8322937 0.185397 1.9913884 0.00861771 1.9999814 ] [ 0.14112 0.0100075 0.1387981 1.9903207 0.00646326 1.9999791 ] [-0.7568025 0.3463564 0.18459873 1.982814 0.00861763 1.9999628 ]]], shape=(2, 5, 6), dtype=float32) |
可视化最终嵌入
为了可视化嵌入,我们取两个更长的句子:一个技术性的,另一个只是一个引语。我们将设置 `TextVectorization` 层和位置编码层,看看最终输出是什么样子。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
technical_phrase = "要理解机器学习算法,您需要" +\ "理解诸如函数梯度、"+\ "矩阵的 Hessian 和优化等概念" wise_phrase = "帕特里克·亨利说,不自由毋宁死"+\ "当他在三月向第二次弗吉尼亚大会发表讲话时" total_vocabulary = 200 sequence_length = 20 final_output_len = 50 phrase_vectorization_layer = TextVectorization( output_sequence_length=sequence_length, max_tokens=total_vocabulary) # 学习字典 phrase_vectorization_layer.adapt([technical_phrase, wise_phrase]) # 将所有句子转换为张量 phrase_tensors = convert_to_tensor([technical_phrase, wise_phrase], dtype=tf.string) # 使用单词张量获取向量化短语 vectorized_phrases = phrase_vectorization_layer(phrase_tensors) random_weights_embedding_layer = PositionEmbeddingLayer(sequence_length, total_vocabulary, final_output_len) fixed_weights_embedding_layer = PositionEmbeddingFixedWeights(sequence_length, total_vocabulary, final_output_len) random_embedding = random_weights_embedding_layer(vectorized_phrases) fixed_embedding = fixed_weights_embedding_layer(vectorized_phrases) |
现在让我们看看两个短语的随机嵌入是什么样子。
|
1 2 3 4 5 6 7 8 9 10 |
fig = plt.figure(figsize=(15, 5)) title = ["技术短语", "智慧短语"] for i in range(2): ax = plt.subplot(1, 2, 1+i) matrix = tf.reshape(random_embedding[i, :, :], (sequence_length, final_output_len)) cax = ax.matshow(matrix) plt.gcf().colorbar(cax) plt.title(title[i], y=1.2) fig.suptitle("随机嵌入") plt.show() |
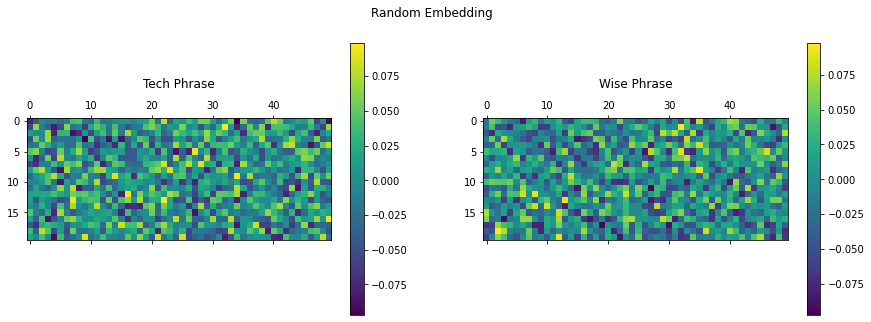
随机嵌入
下面可视化了来自固定权重层的嵌入。
|
1 2 3 4 5 6 7 8 9 10 |
fig = plt.figure(figsize=(15, 5)) title = ["技术短语", "智慧短语"] for i in range(2): ax = plt.subplot(1, 2, 1+i) matrix = tf.reshape(fixed_embedding[i, :, :], (sequence_length, final_output_len)) cax = ax.matshow(matrix) plt.gcf().colorbar(cax) plt.title(title[i], y=1.2) fig.suptitle("来自 Attention is All You Need 的固定权重嵌入") plt.show() |
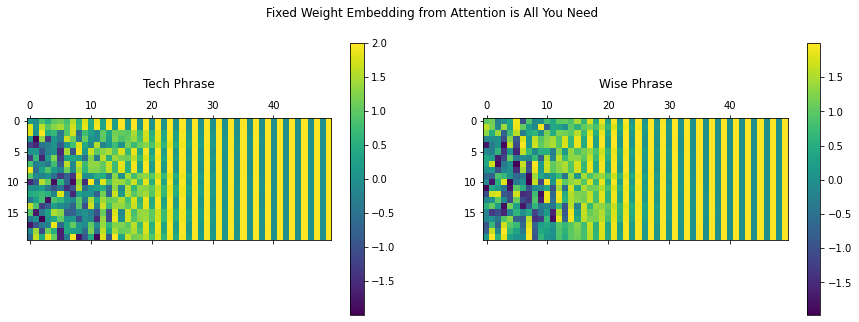
使用正弦位置编码进行嵌入
您可以看到使用默认参数初始化的嵌入层输出随机值。另一方面,使用正弦生成的固定权重为每个短语创建了独特的签名,其中编码了每个单词的位置信息。
您可以根据您的特定应用尝试可调谐或固定权重实现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
论文
- 注意力就是你所需要的一切, 2017
文章
- Transformer 注意力机制
- Transformer 模型
- 用于语言理解的 Transformer 模型
- 在 Keras 模型中使用预训练的词嵌入
- 使用序列到序列 Transformer 进行英语到西班牙语翻译
- Transformer 模型中位置编码的温和介绍,第 1 部分
总结
在本教程中,您了解了 Keras 中位置编码层的实现。
具体来说,你学到了:
- Keras 中的文本向量化层
- Keras 中的位置编码层
- 创建您自己的位置编码类
- 在 Keras 中为位置编码层设置您自己的权重
您对本文中讨论的位置编码有任何疑问吗?请在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






感谢您超级清晰和有用的解释!
很棒的反馈,Guydo!
嗨 James,很棒的帖子、网站和内容,恭喜。关于 transformer,我正在进入这个新世界,理解它并不太难,但我看到每个例子都总是专注于 NLP,如果我想将 transformer 用于时间序列,我是否应该为此目的使用特殊的位置编码层?我的意思是,我知道时间数据可以使用 sin 和 cos 在数据准备预处理中编码,然后再将这些时间数据输入我们的网络,但是,如果我想在时间序列中保持每个元素的位置,位置编码是必要的吗?
再次感谢。
嗨 Pablo…非常欢迎!希望以下资源对您有帮助
https://machinelearning.org.cn/a-gentle-introduction-to-positional-encoding-in-transformer-models-part-1/
亲爱的 Mehreen Saeed
当我学习这个博客时,它显示无法从 'tensorflow.keras.layers' 导入名称 'TextVectorization'。如何解决此错误?
谢谢您。
很棒的教程!我对 PositionEmbeddingFixedWeights 类有一个问题。为什么要将 word_embedding_matrix 设置为等于 get_position_embedding 而不是随机初始化它?谢谢!
嗨 HZ…非常欢迎!该设置仅用于说明目的。随机初始化实际上是首选方法。请采纳您的建议,并告诉我们您的发现!
这个博客中的位置嵌入层与我们在第 1 部分中构建的正弦/余弦函数不同,对吗?我们现在使用与词嵌入相同的方法生成嵌入吗?
不用管我之前的评论,我没有查看本教程的其余部分,发现它已经包含了基于正弦/余弦的位置编码
谢谢您的更新,Diego!
在时间序列预测任务中,当我们将其传递给 transformer 模型而不破坏其排序的时间序列性质时,我们需要位置编码吗?
各位作者,您好,
感谢您为本书所做的努力。
请问能否解释一下为什么在整本书中,词嵌入都被设置为不可训练的?(我的问题与位置编码无关)
嗨 Ivan,
我来这里也是问同样的问题。然后我注意到 HZ 问过同样的问题(2022 年 11 月 8 日)。作者的回答似乎是这只是为了说明目的。实际上,对于词嵌入,最好使用随机初始化的可训练权重(或者使用现成的预训练词嵌入,在这种情况下,您可能希望将它们设置为不可训练,我想?)
希望这有帮助。这本书很有用,但我经常发现自己对所提供的代码示例需要格外小心,并与其他更严谨的资源进行双重检查和交叉引用。
非常有教育意义的文章。谢谢!
对于代码我有一个问题
word_embedding_matrix = self.get_position_encoding(vocab_size, output_dim)
position_embedding_matrix = self.get_position_encoding(sequence_length, output_dim)
它们都使用以下函数,默认 n=10000。这两个调用中是否有一个应该采用除了 10000 之外的其他输入 n 值?
def get_position_encoding(self, seq_len, d, n=10000)
P = np.zeros((seq_len, d))
for k in range(seq_len)
for i in np.arange(int(d/2))
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
嗨 Harrison…非常欢迎!给定 n 的值可以被视为一个需要优化的参数。
你好,
看起来很棒。
您想用 pytorch 重写 transformer 吗?
嗨 BH…这总是一个选择。我们更喜欢 Tensorflow/Keras。