我们已经组装了完整的Transformer模型,现在我们准备对其进行神经机器翻译的训练。为此,我们将使用一个训练数据集,其中包含简短的英语和德语句子对。我们还将重新审视掩码在训练过程中计算准确率和损失指标的作用。
在本教程中,您将学习如何训练Transformer模型进行神经机器翻译。
完成本教程后,您将了解:
- 如何准备训练数据集
- 如何将填充掩码应用于损失和准确率计算
- 如何训练Transformer模型
通过我的书《使用注意力构建Transformer模型》启动您的项目。它提供了带有工作代码的自学教程,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

训练Transformer模型
图片来自v2osk,保留部分权利。
教程概述
本教程分为四个部分;它们是
- Transformer 架构回顾
- 准备训练数据集
- 将填充掩码应用于损失和准确率计算
- 训练 Transformer 模型
先决条件
本教程假设您已熟悉以下内容:
Transformer 架构回顾
回想一下,Transformer架构遵循编码器-解码器结构。左侧的编码器负责将输入序列映射到连续表示序列;右侧的解码器接收编码器的输出以及前一时间步的解码器输出来生成输出序列。
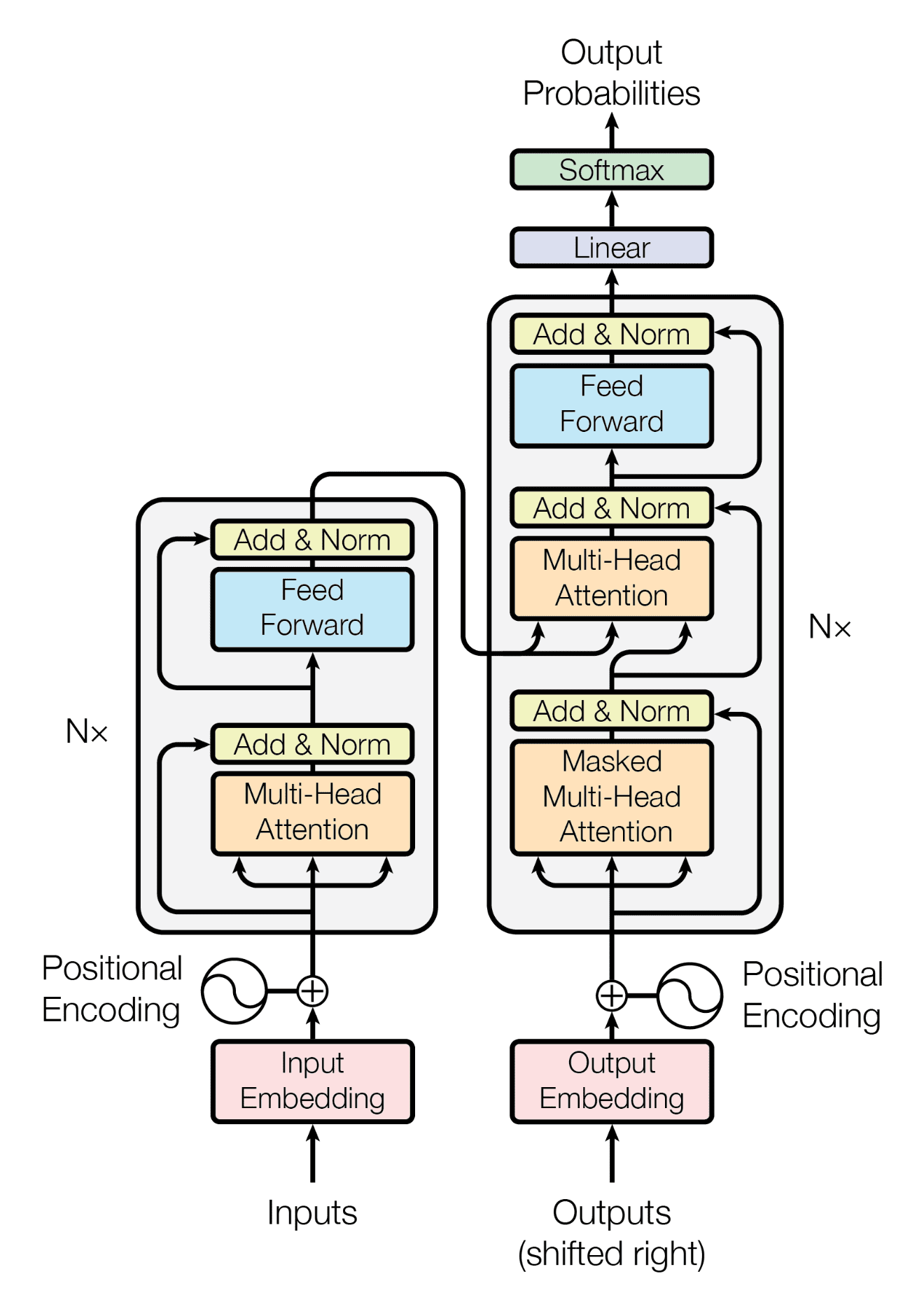
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
在生成输出序列时,Transformer 不依赖于循环和卷积。
您已经了解了如何实现完整的Transformer模型,因此现在可以继续对其进行神经机器翻译的训练。
让我们首先准备用于训练的数据集。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
准备训练数据集
为此,您可以参考之前的教程,其中涵盖了准备文本数据进行训练的材料。
您还将使用一个包含简短英语和德语句子对的数据集,您可以在此处下载。此特定数据集已经过清理,移除了不可打印和非字母字符以及标点符号,将所有Unicode字符进一步标准化为ASCII,并将所有大写字母更改为小写字母。因此,您可以跳过清理步骤,该步骤通常是数据准备过程的一部分。但是,如果您使用未经清理的数据集,您可以参考此前的教程学习如何进行清理。
让我们继续创建实现以下步骤的PrepareDataset类
- 从指定文件名加载数据集。
|
1 |
clean_dataset = load(open(filename, 'rb')) |
- 从数据集中选择要使用的句子数量。由于数据集很大,您将减小其大小以限制训练时间。但是,您可以探索使用完整数据集作为本教程的扩展。
|
1 |
dataset = clean_dataset[:self.n_sentences, :] |
- 将开始(<START>)和字符串结束(<EOS>)标记添加到每个句子。例如,英文句子
i like to run现在变为<START> i like to run <EOS>。这同样适用于其对应的德语翻译ich gehe gerne joggen,它现在变为<START> ich gehe gerne joggen <EOS>。
|
1 2 3 |
for i in range(dataset[:, 0].size): dataset[i, 0] = "<START> " + dataset[i, 0] + " <EOS>" dataset[i, 1] = "<START> " + dataset[i, 1] + " <EOS>" |
- 随机打乱数据集。
|
1 |
shuffle(dataset) |
- 根据预定义比例分割打乱后的数据集。
|
1 |
train = dataset[:int(self.n_sentences * self.train_split)] |
- 创建并训练一个分词器,用于将馈送到编码器中的文本序列,并找到最长序列的长度以及词汇量大小。
|
1 2 3 |
enc_tokenizer = self.create_tokenizer(train[:, 0]) enc_seq_length = self.find_seq_length(train[:, 0]) enc_vocab_size = self.find_vocab_size(enc_tokenizer, train[:, 0]) |
- 通过创建单词词汇表并将每个单词替换为其对应的词汇表索引,对将馈送到编码器中的文本序列进行分词。<START>和<EOS>标记也将成为此词汇表的一部分。每个序列也填充到最大短语长度。
|
1 2 3 |
trainX = enc_tokenizer.texts_to_sequences(train[:, 0]) trainX = pad_sequences(trainX, maxlen=enc_seq_length, padding='post') trainX = convert_to_tensor(trainX, dtype=int64) |
- 创建并训练一个分词器,用于将馈送到解码器中的文本序列,并找到最长序列的长度以及词汇量大小。
|
1 2 3 |
dec_tokenizer = self.create_tokenizer(train[:, 1]) dec_seq_length = self.find_seq_length(train[:, 1]) dec_vocab_size = self.find_vocab_size(dec_tokenizer, train[:, 1]) |
- 对将馈送到解码器中的文本序列重复类似的分词和填充过程。
|
1 2 3 |
trainY = dec_tokenizer.texts_to_sequences(train[:, 1]) trainY = pad_sequences(trainY, maxlen=dec_seq_length, padding='post') trainY = convert_to_tensor(trainY, dtype=int64) |
完整的代码清单如下(有关更多详细信息,请参阅此前的教程)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
从 pickle 导入 加载 from numpy.random import shuffle from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from tensorflow import convert_to_tensor, int64 class PrepareDataset: def __init__(self, **kwargs): super(PrepareDataset, self).__init__(**kwargs) self.n_sentences = 10000 # 数据集中包含的句子数量 self.train_split = 0.9 # 训练数据分割比例 # 拟合分词器 def create_tokenizer(self, dataset): tokenizer = Tokenizer() tokenizer.fit_on_texts(dataset) return tokenizer def find_seq_length(self, dataset): return max(len(seq.split()) for seq in dataset) def find_vocab_size(self, tokenizer, dataset): tokenizer.fit_on_texts(dataset) return len(tokenizer.word_index) + 1 def __call__(self, filename, **kwargs): # 加载干净数据集 clean_dataset = load(open(filename, 'rb')) # 减小数据集大小 dataset = clean_dataset[:self.n_sentences, :] # 包含字符串开始和结束标记 for i in range(dataset[:, 0].size): dataset[i, 0] = "<START> " + dataset[i, 0] + " <EOS>" dataset[i, 1] = "<START> " + dataset[i, 1] + " <EOS>" # 随机打乱数据集 shuffle(dataset) # 分割数据集 train = dataset[:int(self.n_sentences * self.train_split)] # 为编码器输入准备分词器 enc_tokenizer = self.create_tokenizer(train[:, 0]) enc_seq_length = self.find_seq_length(train[:, 0]) enc_vocab_size = self.find_vocab_size(enc_tokenizer, train[:, 0]) # 编码和填充输入序列 trainX = enc_tokenizer.texts_to_sequences(train[:, 0]) trainX = pad_sequences(trainX, maxlen=enc_seq_length, padding='post') trainX = convert_to_tensor(trainX, dtype=int64) # 为解码器输入准备分词器 dec_tokenizer = self.create_tokenizer(train[:, 1]) dec_seq_length = self.find_seq_length(train[:, 1]) dec_vocab_size = self.find_vocab_size(dec_tokenizer, train[:, 1]) # 编码和填充输入序列 trainY = dec_tokenizer.texts_to_sequences(train[:, 1]) trainY = pad_sequences(trainY, maxlen=dec_seq_length, padding='post') trainY = convert_to_tensor(trainY, dtype=int64) return trainX, trainY, train, enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size |
在继续训练Transformer模型之前,让我们先看看与训练数据集中第一个句子对应的PrepareDataset类的输出
|
1 2 3 4 5 |
# 准备训练数据 dataset = PrepareDataset() trainX, trainY, train_orig, enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size = dataset('english-german-both.pkl') print(train_orig[0, 0], '\n', trainX[0, :]) |
|
1 2 |
<START> did tom tell you <EOS> tf.Tensor([ 1 25 4 97 5 2 0], shape=(7,), dtype=int64) |
(注意:由于数据集已随机打乱,您可能会看到不同的输出。)
您可以看到,最初您有一个三个单词的句子(did tom tell you),您为其添加了开始和字符串结束标记。然后您将其向量化(您可能会注意到<START>和<EOS>标记分别被分配了词汇索引1和2)。向量化后的文本也用零填充,以使最终结果的长度与编码器的最大序列长度匹配
|
1 |
print('Encoder sequence length:', enc_seq_length) |
|
1 |
Encoder sequence length: 7 |
您可以类似地查看馈送到解码器中的相应目标数据
|
1 |
print(train_orig[0, 1], '\n', trainY[0, :]) |
|
1 2 |
<START> hat tom es dir gesagt <EOS> tf.Tensor([ 1 14 5 7 42 162 2 0 0 0 0 0], shape=(12,), dtype=int64) |
这里,最终结果的长度与解码器的最大序列长度匹配
|
1 |
print('Decoder sequence length:', dec_seq_length) |
|
1 |
Decoder sequence length: 12 |
将填充掩码应用于损失和准确率计算
回想一下,编码器和解码器中的填充掩码的重要性在于确保我们刚刚添加到向量化输入中的零值不会与实际输入值一起处理。
这在训练过程中也同样适用,在训练过程中需要一个填充掩码,以便在计算损失和准确率时不考虑目标数据中的零填充值。
让我们先看看损失的计算。
这将使用目标值和预测值之间的稀疏分类交叉熵损失函数进行计算,然后乘以一个填充掩码,以便只考虑有效的非零值。返回的损失是未掩码值的平均值
|
1 2 3 4 5 6 7 8 9 10 |
def loss_fcn(target, prediction): # 创建掩码,使零填充值不包含在损失计算中 padding_mask = math.logical_not(equal(target, 0)) padding_mask = cast(padding_mask, float32) # 对未掩码的值计算稀疏分类交叉熵损失 loss = sparse_categorical_crossentropy(target, prediction, from_logits=True) * padding_mask # 计算未掩码值的平均损失 return reduce_sum(loss) / reduce_sum(padding_mask) |
对于准确率的计算,首先比较预测值和目标值。预测输出是一个大小为(batch_size,dec_seq_length,dec_vocab_size)的张量,包含输出中标记的概率值(由解码器侧的softmax函数生成)。为了能够与目标值进行比较,只考虑每个概率值最高的标记,其字典索引通过操作argmax(prediction, axis=2)检索。在应用填充掩码之后,返回的准确率是未掩码值的平均值
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def accuracy_fcn(target, prediction): # 创建掩码,使零填充值不包含在准确率计算中 padding_mask = math.logical_not(math.equal(target, 0)) # 找到相等的预测值和目标值,并应用填充掩码 accuracy = equal(target, argmax(prediction, axis=2)) accuracy = math.logical_and(padding_mask, accuracy) # 将True/False值转换为32位浮点数 padding_mask = cast(padding_mask, float32) accuracy = cast(accuracy, float32) # 计算未掩码值的平均准确率 return reduce_sum(accuracy) / reduce_sum(padding_mask) |
训练 Transformer 模型
我们首先定义由Vaswani等人(2017)指定的模型和训练参数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 定义模型参数 h = 8 # 自注意力头的数量 d_k = 64 # 线性投影查询和键的维度 d_v = 64 # 线性投影值的维度 d_model = 512 # 模型层输出的维度 d_ff = 2048 # 内部全连接层的维度 n = 6 # 编码器堆栈中的层数 # 定义训练参数 epochs = 2 batch_size = 64 beta_1 = 0.9 beta_2 = 0.98 epsilon = 1e-9 dropout_rate = 0.1 |
(注意:只考虑两个时期以限制训练时间。但是,您可以探索进一步训练模型作为本教程的扩展。)
您还需要实现一个学习率调度器,该调度器首先在最初的warmup_steps中线性增加学习率,然后按步数平方根的倒数比例减少学习率。Vaswani等人用以下公式表示:
$$\text{learning_rate} = \text{d_model}^{−0.5} \cdot \text{min}(\text{step}^{−0.5}, \text{step} \cdot \text{warmup_steps}^{−1.5})$$
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
class LRScheduler(LearningRateSchedule): def __init__(self, d_model, warmup_steps=4000, **kwargs): super(LRScheduler, self).__init__(**kwargs) self.d_model = cast(d_model, float32) self.warmup_steps = warmup_steps def __call__(self, step_num): # 在最初的warmup_steps中线性增加学习率,之后递减 arg1 = step_num ** -0.5 arg2 = step_num * (self.warmup_steps ** -1.5) return (self.d_model ** -0.5) * math.minimum(arg1, arg2) |
LRScheduler类的一个实例随后作为Adam优化器的learning_rate参数传入
|
1 |
optimizer = Adam(LRScheduler(d_model), beta_1, beta_2, epsilon) |
接下来,将数据集分割成批次以进行训练准备
|
1 2 |
train_dataset = data.Dataset.from_tensor_slices((trainX, trainY)) train_dataset = train_dataset.batch(batch_size) |
这之后是创建模型实例
|
1 |
training_model = TransformerModel(enc_vocab_size, dec_vocab_size, enc_seq_length, dec_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate) |
在训练Transformer模型时,您将编写自己的训练循环,其中包含前面实现的损失和准确率函数。
Tensorflow 2.0 中的默认运行时是即时执行,这意味着操作一个接一个地立即执行。即时执行简单直观,使调试更容易。然而,它的缺点是无法利用使用图执行运行代码的全局性能优化。在图执行中,在执行张量计算之前会先构建一个图,这会产生计算开销。因此,图执行主要推荐用于大型模型训练,而不是小型模型训练,其中即时执行可能更适合执行简单的操作。由于Transformer模型足够大,我们将其应用于图执行进行训练。
为此,您将使用@function装饰器,如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
@function def train_step(encoder_input, decoder_input, decoder_output): with GradientTape() as tape: # 运行模型的前向传播以生成预测 prediction = training_model(encoder_input, decoder_input, training=True) # 计算训练损失 loss = loss_fcn(decoder_output, prediction) # 计算训练准确率 accuracy = accuracy_fcn(decoder_output, prediction) # 检索可训练变量相对于训练损失的梯度 gradients = tape.gradient(loss, training_model.trainable_weights) # 通过梯度下降更新可训练变量的值 optimizer.apply_gradients(zip(gradients, training_model.trainable_weights)) train_loss(loss) train_accuracy(accuracy) |
添加@function装饰器后,以张量作为输入的函数将被编译成图。如果@function装饰器被注释掉,则该函数将通过即时执行运行。
下一步是实现训练循环,该循环将调用上述train_step函数。训练循环将迭代指定数量的时期和数据集批次。对于每个批次,train_step函数计算训练损失和准确率度量,并应用优化器更新可训练模型参数。还包含一个检查点管理器,以便每五个时期保存一个检查点
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
train_loss = Mean(name='train_loss') train_accuracy = Mean(name='train_accuracy') # 创建检查点对象和管理器以管理多个检查点 ckpt = train.Checkpoint(model=training_model, optimizer=optimizer) ckpt_manager = train.CheckpointManager(ckpt, "./checkpoints", max_to_keep=3) for epoch in range(epochs): train_loss.reset_states() train_accuracy.reset_states() print("\nStart of epoch %d" % (epoch + 1)) # 遍历数据集批次 for step, (train_batchX, train_batchY) in enumerate(train_dataset): # 定义编码器和解码器输入以及解码器输出 encoder_input = train_batchX[:, 1:] decoder_input = train_batchY[:, :-1] decoder_output = train_batchY[:, 1:] train_step(encoder_input, decoder_input, decoder_output) if step % 50 == 0: print(f'Epoch {epoch + 1} Step {step} Loss {train_loss.result():.4f} Accuracy {train_accuracy.result():.4f}') # 在每个时期结束时打印时期号和损失值 print("Epoch %d: Training Loss %.4f, Training Accuracy %.4f" % (epoch + 1, train_loss.result(), train_accuracy.result())) # 每五个时期保存一个检查点 if (epoch + 1) % 5 == 0: save_path = ckpt_manager.save() print("Saved checkpoint at epoch %d" % (epoch + 1)) |
需要记住的一个重要点是,解码器的输入相对于编码器输入向右偏移一个位置。这种偏移背后的思想,结合解码器第一个多头注意力块中的前瞻掩码,是为了确保当前标记的预测只能依赖于之前的标记。
这种掩码,加上输出嵌入偏移一个位置的事实,确保了位置i的预测只能依赖于小于i位置的已知输出。
—— 《Attention Is All You Need》,2017。
正因为如此,编码器和解码器输入以以下方式馈送到Transformer模型中
encoder_input = train_batchX[:, 1:]
decoder_input = train_batchY[:, :-1]
将完整的代码清单组合起来会产生以下结果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 |
from tensorflow.keras.optimizers import Adam from tensorflow.keras.optimizers.schedules import LearningRateSchedule from tensorflow.keras.metrics import Mean from tensorflow import data, train, math, reduce_sum, cast, equal, argmax, float32, GradientTape, TensorSpec, function, int64 from keras.losses import sparse_categorical_crossentropy from model import TransformerModel from prepare_dataset import PrepareDataset from time import time # 定义模型参数 h = 8 # 自注意力头的数量 d_k = 64 # 线性投影查询和键的维度 d_v = 64 # 线性投影值的维度 d_model = 512 # 模型层输出的维度 d_ff = 2048 # 内部全连接层的维度 n = 6 # 编码器堆栈中的层数 # 定义训练参数 epochs = 2 batch_size = 64 beta_1 = 0.9 beta_2 = 0.98 epsilon = 1e-9 dropout_rate = 0.1 # 实现学习率调度器 class LRScheduler(LearningRateSchedule): def __init__(self, d_model, warmup_steps=4000, **kwargs): super(LRScheduler, self).__init__(**kwargs) self.d_model = cast(d_model, float32) self.warmup_steps = warmup_steps def __call__(self, step_num): # 在最初的warmup_steps中线性增加学习率,之后递减 arg1 = step_num ** -0.5 arg2 = step_num * (self.warmup_steps ** -1.5) return (self.d_model ** -0.5) * math.minimum(arg1, arg2) # 实例化Adam优化器 optimizer = Adam(LRScheduler(d_model), beta_1, beta_2, epsilon) # 准备数据集的训练集和测试集 dataset = PrepareDataset() trainX, trainY, train_orig, enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size = dataset('english-german-both.pkl') # 准备数据集批次 train_dataset = data.Dataset.from_tensor_slices((trainX, trainY)) train_dataset = train_dataset.batch(batch_size) # 创建模型 training_model = TransformerModel(enc_vocab_size, dec_vocab_size, enc_seq_length, dec_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate) # 定义损失函数 def loss_fcn(target, prediction): # 创建掩码,使零填充值不包含在损失计算中 padding_mask = math.logical_not(equal(target, 0)) padding_mask = cast(padding_mask, float32) # 对未掩码的值计算稀疏分类交叉熵损失 loss = sparse_categorical_crossentropy(target, prediction, from_logits=True) * padding_mask # 计算未掩码值的平均损失 return reduce_sum(loss) / reduce_sum(padding_mask) # 定义准确率函数 def accuracy_fcn(target, prediction): # 创建掩码,使零填充值不包含在准确率计算中 padding_mask = math.logical_not(equal(target, 0)) # 找到相等的预测值和目标值,并应用填充掩码 accuracy = equal(target, argmax(prediction, axis=2)) accuracy = math.logical_and(padding_mask, accuracy) # 将True/False值转换为32位浮点数 padding_mask = cast(padding_mask, float32) accuracy = cast(accuracy, float32) # 计算未掩码值的平均准确率 return reduce_sum(accuracy) / reduce_sum(padding_mask) # 包含指标监控 train_loss = Mean(name='train_loss') train_accuracy = Mean(name='train_accuracy') # 创建检查点对象和管理器以管理多个检查点 ckpt = train.Checkpoint(model=training_model, optimizer=optimizer) ckpt_manager = train.CheckpointManager(ckpt, "./checkpoints", max_to_keep=3) # 加快训练过程 @function def train_step(encoder_input, decoder_input, decoder_output): with GradientTape() as tape: # 运行模型的前向传播以生成预测 prediction = training_model(encoder_input, decoder_input, training=True) # 计算训练损失 loss = loss_fcn(decoder_output, prediction) # 计算训练准确率 accuracy = accuracy_fcn(decoder_output, prediction) # 检索可训练变量相对于训练损失的梯度 gradients = tape.gradient(loss, training_model.trainable_weights) # 通过梯度下降更新可训练变量的值 optimizer.apply_gradients(zip(gradients, training_model.trainable_weights)) train_loss(loss) train_accuracy(accuracy) for epoch in range(epochs): train_loss.reset_states() train_accuracy.reset_states() print("\nStart of epoch %d" % (epoch + 1)) start_time = time() # 遍历数据集批次 for step, (train_batchX, train_batchY) in enumerate(train_dataset): # 定义编码器和解码器输入以及解码器输出 encoder_input = train_batchX[:, 1:] decoder_input = train_batchY[:, :-1] decoder_output = train_batchY[:, 1:] train_step(encoder_input, decoder_input, decoder_output) if step % 50 == 0: print(f'Epoch {epoch + 1} Step {step} Loss {train_loss.result():.4f} Accuracy {train_accuracy.result():.4f}') # print("Samples so far: %s" % ((step + 1) * batch_size)) # 在每个时期结束时打印时期号和损失值 print("Epoch %d: Training Loss %.4f, Training Accuracy %.4f" % (epoch + 1, train_loss.result(), train_accuracy.result())) # 每五个时期保存一个检查点 if (epoch + 1) % 5 == 0: save_path = ckpt_manager.save() print("Saved checkpoint at epoch %d" % (epoch + 1)) print("Total time taken: %.2fs" % (time() - start_time)) |
运行代码会产生类似以下输出的结果(您可能会看到不同的损失和准确率值,因为训练是从头开始的,而训练时间取决于您可用于训练的计算资源)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Start of epoch 1 Epoch 1 Step 0 Loss 8.4525 Accuracy 0.0000 Epoch 1 Step 50 Loss 7.6768 Accuracy 0.1234 Epoch 1 Step 100 Loss 7.0360 Accuracy 0.1713 Epoch 1: Training Loss 6.7109, Training Accuracy 0.1924 Start of epoch 2 Epoch 2 Step 0 Loss 5.7323 Accuracy 0.2628 Epoch 2 Step 50 Loss 5.4360 Accuracy 0.2756 Epoch 2 Step 100 Loss 5.2638 Accuracy 0.2839 Epoch 2: Training Loss 5.1468, Training Accuracy 0.2908 Total time taken: 87.98s |
在仅使用CPU的相同平台上,仅使用即时执行运行代码需要155.13秒,这显示了使用图执行的好处。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019
- 用于自然语言处理的 Transformer, 2021
论文
- 注意力就是你所需要的一切, 2017
网站
总结
在本教程中,您学习了如何训练Transformer模型进行神经机器翻译。
具体来说,你学到了:
- 如何准备训练数据集
- 如何将填充掩码应用于损失和准确率计算
- 如何训练Transformer模型
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






亲爱的Stefania Cristina博士
当从model导入TransformerModel时,显示“No module named ‘model’”,如何解决?
谢谢你
嗨,Jack,model是一个Python (.py) 脚本文件,我将我们之前在本教程中组装的TransformerModel类保存在其中:https://machinelearning.org.cn/joining-the-transformer-encoder-and-decoder-and-masking/。您也可以为自己创建一个同名文件(model.py)。
我明白了,谢谢您,Stefania Cristina博士。
亲爱的 Stefania Cristina 博士
本教程用于神经机器翻译,如果我需要将其用于数据分类和数据回归任务,如何修改?
谢谢
Jack
亲爱的 Stefania Cristina 博士
为了避免重新训练,需要加载已训练的检查点,如何编写代码?
谢谢你
感谢迄今为止的博客。这是一个非常有趣的系列。
请注意,PrepareDataset类中有一个bug ... trainY = enc_tokenizer.texts_to_sequences(train[:, 1])。这应该是dec_tokenizer而不是enc_tokenizer。如果您按原样使用此类别,大多数序列将只返回2个标记,因为它无法识别英语词汇中的德语单词。
感谢您的反馈,Sacha!我们很感激!
感谢这个超棒的教程。我想知道如何将相同的代码应用于蛋白质无序区域预测。
输入是蛋白质序列,输出是二元序列(如果相应的残基无序,则为1,否则为0)。
例如
输入:AAAALLLLAKKK
输出:111111100001
嗨,Michel……不客气!您可能需要考虑一个序列到序列的模型
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
嗨,James,感谢您的教程。
如何将此模型用于问答预测?
Bert只支持512个标记,我可以使用此模型自定义训练我的数据集吗?
嗨,Jithin……您可能会发现以下内容很有趣
https://cs224d.stanford.edu/reports/Bogatyy.pdf
https://blog.paperspace.com/how-to-train-question-answering-machine-learning-models/
请问如何将张量还原成句子?
训练后,如何使用模型?我看到模型需要decode_output,所以我对此感到非常困惑
例如,训练后,我有一个句子“I want to go home”,那么我如何才能收到预测句子,例如predictSentence = model(‘I want to go home’)?
谢谢你
嗨,Peter……以下讨论应该能提供清晰的说明
https://stackoverflow.com/questions/61071537/how-to-convert-vector-back-to-sentence-using-tensorflows-universal-sentence-enc
以下文章可能对您也有帮助
https://machinelearning.org.cn/plotting-the-training-and-validation-loss-curves-for-the-transformer-model/
https://machinelearning.org.cn/inferencing-the-transformer-model/
嗨,Jason,
感谢这篇很棒的文章!
我对训练过程有点困惑,
根据我的理解,Transformer 解码器一次只生成一个标记(单词)。那么,`train_step` 函数中的这一行 “`prediction = training_model(encoder_input, decoder_input, training=True)`” 如何生成一个完整的句子,包含多个单词,用于后续的损失计算,而无需使用 for 循环来逐个生成单词呢?
能解释一下这个问题吗?
确实不是。Transformer 解码器会一次性生成整个句子,但有时我们对整个结果不完全自信,所以我们只取下一个标记。回想一下注意力机制是如何工作的:你有一个键(key)、一个值(value)和一个查询(query)。键和值来自编码器,查询是解码器输入。你可以传入一个空查询,并让注意力机制一次性为你提供所有内容。但你也可以提供一个部分句子,并让注意力机制填充句子的其余部分。这里使用的是前者。你提到的方式是后者。
谢谢您的回复
你的意思是解码器被训练成只预测最后一个标记,所以在这行 `decoder_input = train_batchY[:, :-1]` 中,最后一个标记被移除了吗?
另一个问题,Teacher Forcing 方法可以用于 Transformer 吗,或者说它已经被使用了吗?
我认为这行有错误。根据 Adrian 的解释,解码器输入应该只包含 START 标记。正确的行应该是
decoder_input = train_batchY[:, :1] # 不是 -1
请忽略我之前的回复,它是错误的。
encoder_input = train_batchX[:, 1:]
decoder_input = train_batchY[:, :-1]
decoder_output = train_batchY[:, 1:]
才是正确的方法。
以下是深入解释
编码器和解码器长度可能不同,即 enc_seq_length 不等于 dec_seq_length。这很合理,因为不同语言的句子长度不同。
解码器输入序列长度必须等于解码器输出序列长度,这个要求必须满足才能计算损失函数。
假设
enc_seq_length = 5
dec_seq_length = 7
START-token = 1
EOS-token = 2
enc_input = [[1,10,11,12,2]] # 我喜欢 Transformer
dec_input = [[1,100,101,102,103,2,0]] # ik hou van transformatoren
编码器不需要或标记,但为了书籍方便,它们保留了 EOS。这解释了 encoder_input = train_batchX[:, 1:]
解码器输入必须以不存在的单词开头。这在推理过程中清晰可见:为了指示神经网络开始生成输出文本,我们应该提供单个标记。基本上是 [[1, 0,0,0,…..]]。但在训练阶段,完整的句子也可以工作 [[1,100,101,102,103,2,0]](前瞻掩码将确保网络不会偷看后面的单词)。
解码器输出应该预测实际单词,神经网络不应该预测标记,这解释了 decoder_output = train_batchY[:, 1:]
为了能够计算损失函数,dec_input_seq_length 必须等于 dec_output_seq_length,因此 decoder_input = train_batchY[:, :-1]。
但有一个注意事项。为了在解码器中保留完整的句子,dec_seq_length 必须是实际 max(句子长度) + 1,以考虑 [:, :-1]。
以下是如何实现这一点
在 prepare_dataset.py 文件中,将 “+ 1” 添加到该行
dec_seq_length = self.get_seq_length(ds_Y, dec_tokenizer) + 1
Ivan,感谢您对本系列所有文章的评论。看来我只是几个月后才跟随您的脚步!在尝试实现和理解代码时,您的更正和解释非常有帮助。这本书确实需要在许多地方进行更新和更正。如果我没有偶然发现您的评论,我肯定会在(位置编码那一章附近)放弃它。
关于输入/输出的最后一点,我仍然有点迷茫,特别是由于网站在您的评论中因为使用了尖括号而删除了一些词。但我明白了大致意思。
一位旅行者对另一位说:祝您旅途顺利,再次感谢!
你好,
添加 和 标记时,更改为类似 的内容。
原因:分词器会移除特殊符号并小写文本。单词“start”在英语句子中使用了大约30次(检查 enc_tokenizer.get_config()[“word_counts”])。基本上,当前版本将普通单词-start 与分隔符-start 混淆了。
你好,
由于论坛限制,我不能使用尖括号,所以我会用大写来指代分隔符。
添加 START 和 EOS 标记时,将 START-token 更改为类似 SOS 的内容。
原因:分词器会移除特殊符号并将文本小写化。单词“start”在英语句子中使用了大约30次(检查 enc_tokenizer.get_config()[“word_counts”])。基本上,当前版本将普通单词-start 与分隔符-START 混淆了。
如果零只用于填充,并且单词索引从1开始,那么函数“accuracy_fcn”由于这一行而混淆了准确性数字
accuracy = math.equal(target, argmax(prediction, axis=2))
因为 argmax(prediction, axis=2) 返回的索引从0开始,而不是1。经过以下修正后,我得到了正确的数字。
accuracy = math.equal(target, argmax(prediction, axis=2) + 1)
如果我弄错了,请原谅。谢谢!
感谢您的教程。我如何在分类任务中调整代码?提前感谢
你好,
感谢您提供这些宝贵的教程资源。但是当我在 Colab 中运行代码时,LRScheduler 中出现了这个错误。
“TypeError: Cannot convert -0.5 to EagerTensor of dtype int64”
您有什么解决方案吗?我也会尝试自己解决。
此致,
Surasak 您好……非常欢迎!以下讨论可能会有所帮助
https://stackoverflow.com/questions/76001766/typeerror-cannot-convert-0-0-to-eagertensor-of-dtype-int64
您好!非常感谢您提供这个精彩的教程和代码演练!!当我使用与您完全相同的学习率调度器类执行 “optimizer = Adam(LRScheduler(d_model), beta_1, beta_2, epsilon) ” 时,我收到以下错误:“TypeError: cannot convert -0.5 to EagerTensor of dtype int64”。我正在 Google colab 中运行代码。非常感谢您的帮助。
Parisa 您好……以下资源可能会提供清晰的解释
https://tensorflowcn.cn/api_docs/python/tf/Tensor
你好,
如果我理解正确,解码器总是在训练以输出解码器输入加上标记。这应该是这样吗,还是代码中的错误?还是我理解错了?
Alan 您好……以下资源可能对您有用
https://machinelearning.org.cn/encoder-decoder-recurrent-neural-network-models-neural-machine-translation/
你好,
如果我理解正确,解码器总是在训练以输出解码器输入加上标记。这应该是这样吗,还是代码中的错误?还是我理解错了?
您的评论正在等待审核。
你好,
如果我理解正确,解码器总是在训练以输出解码器输入加上 EOS 标记。这应该是这样吗,还是代码中的错误?还是我理解错了?
你好,
如果我理解正确,解码器总是在训练以输出解码器输入加上 -EOS- 标记。这应该是这样吗,还是代码中的错误?还是我理解错了?
亲爱的 Jason Brownle,
抱歉,您有关于在时间序列预测中实现 Transformer 的任何指导吗?
Ali 您好……这份资源是一个很好的起点
https://arxiv.org/abs/2205.13504
亲爱的 Jason,
感谢您通过您的网站分享宝贵的知识。我有一个建议:如果可能的话,您能否创建一些资源来实现在时间序列预测或分类问题中的 Transformer?我有一个与此相关的项目,但我还没有找到任何有用的实现代码作为指导。
此致,
Amir 您好……非常欢迎!我们感谢您的建议!请确保您订阅了我们的时事通讯,以便及时了解新内容!
https://machinelearning.org.cn/newsletter/
你好,
感谢您分享这些精彩文章。我对使用 Transformer 进行时间序列预测很感兴趣。如果您能分享任何相关的教程来实现在时间序列预测中使用 Transformer,那就太棒了。
谢谢。
Madara 您好……这份资源可能也对您有所帮助。
https://hugging-face.cn/blog/autoformer
感谢您提供如此精彩的内容!我对使用传统的编码器-解码器架构训练 Transformer 模型进行因果语言建模(自动文本生成)很感兴趣。我知道在最初的《Attention Is All You Need》论文中,他们也使用了类似本文中的英德数据集进行训练。如果使用编码器-解码器架构可以实现,我该如何设置我的序列以进行语言生成呢?
具体来说,假设我想训练一部小说。
一种选择是设置一个任意的序列长度并从中创建我的序列。例如,第一个序列的编码器输入将是标记 1-30,解码器输入将是 2-31;第二个序列的编码器输入将是标记 2-31,解码器输入将是 3-32,依此类推。然而,在这种情况下,我的训练中将没有填充或序列结束标记,这在预测时会成为问题。
如果我按段落划分序列,例如,那么我可以有序列结束和填充标记,但那样我就不确定如何构建编码器和解码器输入了。
Piotr 您好……您可能需要从这里开始,然后在您阅读内容时提交任何具体问题
https://machinelearning.org.cn/start-here/#attention
James 您好,这篇文章似乎与我的具体问题最相关,因为它是您引用的注意力部分中唯一一篇训练实际数据的文章。如果我的问题有更合适的文章,请指明具体文章。如果没有人能回答这个具体问题,也没关系。谢谢
我如何能够构建一个具有多个按顺序排列的 Transformer 的模型?
这可能是架构的一种合理方式:像这篇文章所示的 Transformer 以处理序列并输出一个概率向量。您可以将句子中的每个单词视为一个数字,语言中有 N 个单词(称为词汇量大小)。那么输出将是一个 N 维向量,被视为概率。您可以将概率最高的那个作为输出单词。这就是“下一个标记”模型。因此,您可以以这样的方式连接两个 Transformer 模型:第一个 Transformer 生成一个 N 维向量,然后您使用 argmax 函数找到单个单词。重复此过程以生成一个单词序列。然后将这个单词序列输入到另一个 Transformer 模型中,以生成一个 M 维向量(第二个模型的输出词汇量大小),并再次使用 argmax 函数从向量中推导出单词。
这对于第一个模型将英语翻译成法语,第二个模型将法语翻译成德语的情况是合理的。