
理解 RAG 第一部分:经典 RAG 的工作原理
图片由 Editor | Midjourney & Canva 提供
在本系列的第一篇文章中,我们介绍了检索增强生成(RAG),并解释了扩展传统大型语言模型(LLM)能力变得多么必要。我们还简要概述了 RAG 的核心思想:从外部知识库检索上下文相关的信,以确保 LLM 生成准确和最新的信息,同时避免幻觉,且无需不断重新训练模型。
本系列第二篇文章将揭秘传统 RAG 系统运行机制。尽管当下随着 AI 的飞速发展,许多增强和更复杂的 RAG 版本几乎每天都在涌现,但要理解最新的最先进的 RAG 方法,第一步是首先理解经典的 RAG 工作流程。
经典 RAG 工作流程
典型的 RAG 系统(如下图所示)处理三个关键的数据相关组件:
- 一个LLM,它已经从其训练数据(通常是数百万到数十亿个文本文档)中获得了知识。
- 一个向量数据库,也称为知识库,用于存储文本文档。但为什么称之为向量数据库呢?在 RAG 和整个自然语言处理(NLP)系统中,文本信息被转化为称为向量的数值表示,这些向量捕捉文本的语义含义。向量代表单词、句子或整个文档,并保留原始文本的关键属性,使得两个相似的向量与具有相似语义的单词、句子或文本片段相关联。将文本存储为数值向量可以提高系统的效率,从而能够快速找到和检索相关文档。
- 用户用自然语言表述的查询或提示。
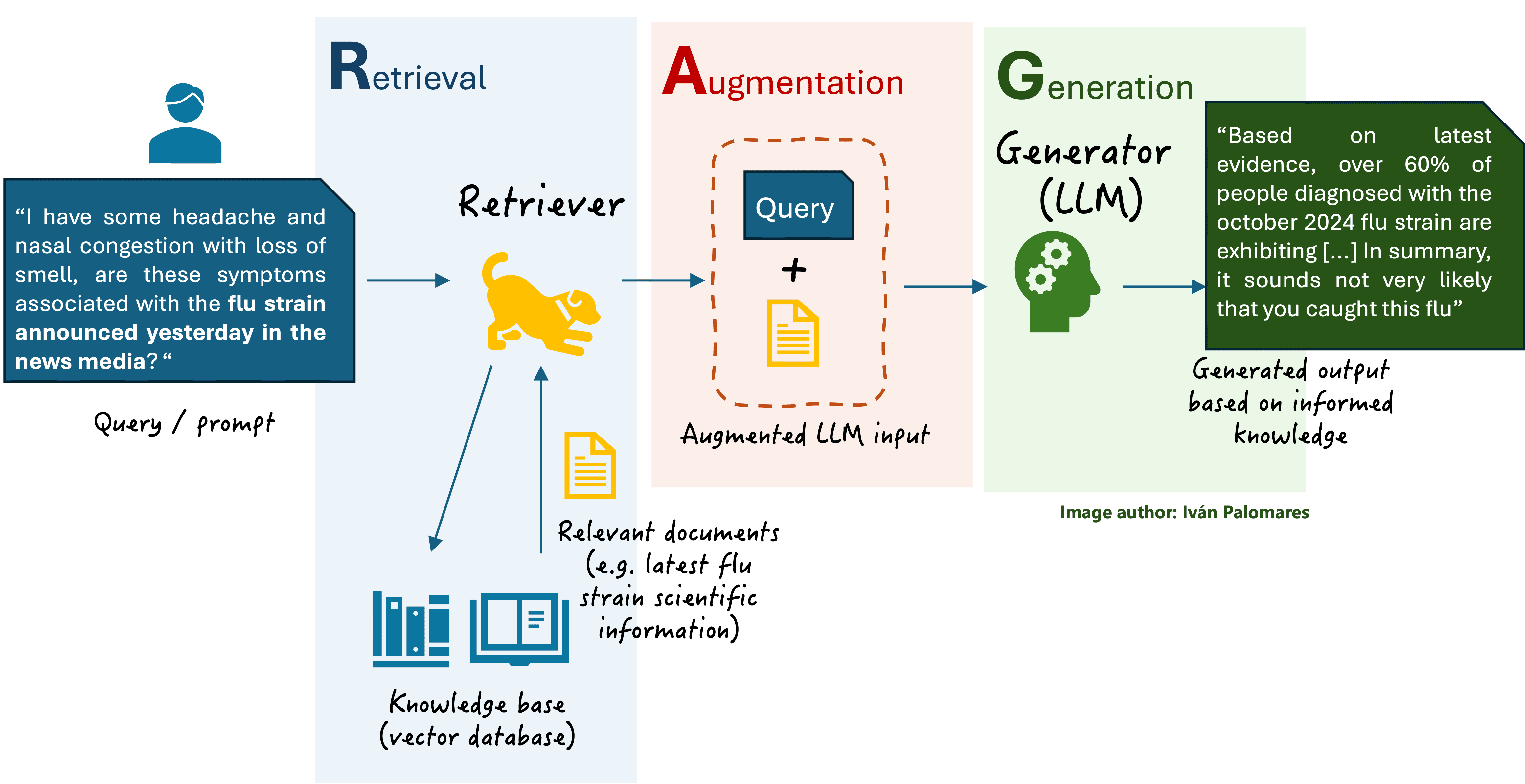
基本 RAG 系统的通用方案
简而言之,当用户向一个具备 RAG 引擎的基于 LLM 的助手提出自然语言问题时,从发送问题到接收答案之间会经历三个阶段:
- 检索(Retrieval):一个称为检索器(retriever)的组件访问向量数据库,查找并检索与用户查询相关的内容。
- 增强(Augmentation):通过结合检索到的文档中的上下文知识来增强原始用户查询。
- 生成(Generation):LLM(从 RAG 的角度也常被称为生成器(generator))接收经过相关上下文信息增强的用户查询,并生成更精确、更真实的文本回复。
检索器内部
检索器是 RAG 系统中用于查找相关信息以增强 LLM 最终输出的组件。你可以将其想象成一个增强的搜索引擎,它不仅仅匹配用户查询中的关键字与存储的文档,更能理解查询背后的含义。
检索器会扫描查询相关的海量领域知识(以向量化形式存储,即文本的数值表示),并提取最相关的文本片段,围绕它们构建一个上下文,然后附加到原始用户查询上。一种识别相关知识的常用技术是相似性搜索,即用户查询被编码为向量表示,然后将此向量与存储的向量数据进行比较。这样,识别出与用户查询最相关的知识片段,就归结为通过迭代执行一些数学计算来确定与该查询向量表示最接近(最相似)的向量。因此,检索器不仅能高效地,而且能准确地提取准确、上下文感知的信息。
生成器内部
RAG 中的生成器通常是一个复杂的语言模型,通常是基于Transformer 架构的 LLM,它接收来自检索器的增强输入,并生成准确、上下文感知且通常真实的回复。通过结合相关的外部信息,这种结果通常优于独立的 LLM。
在模型内部,生成过程涉及文本的理解和生成,由编码增强输入和逐字生成输出文本的组件管理。每个单词的预测都基于前面的单词:这个任务是在 LLM 中执行的最后一个阶段,称为下一个词预测(next-word prediction)问题:预测最有可能的下一个词,以保持生成消息的连贯性和相关性。
这篇文章更详细地阐述了由生成器驱动的语言生成过程。
展望未来
在本系列关于理解 RAG 的下一篇文章中,我们将介绍RAG 的融合方法,其特点是使用专门的方法来组合来自多个检索文档的信息,从而增强用于生成响应的上下文。
RAG 中融合方法的一个常见例子是重排序(reranking),它涉及根据用户相关性对多个检索到的文档进行评分和排序,然后再将最相关的文档传递给生成器。这有助于进一步提高增强上下文的质量,以及语言模型最终生成的响应。






与你之前的 open cv 博客不同,LLM 博客只有理论,没有实现或数学解释。
本博客及其关联网站 KDnuggets 上有大量实用的、动手操作的 LLM 教程。我自己写了一些,还有许多来自杰出贡献者的内容。请查看一下。