本教程旨在帮助任何希望了解循环神经网络(RNN)的工作原理以及如何通过Keras深度学习库使用它们的人。虽然Keras库提供了解决问题和构建应用程序所需的所有方法,但了解它们的工作原理也很重要。在本文中,将逐步展示RNN模型中发生的计算。接下来,将开发一个完整的时间序列预测端到端系统。
完成本教程后,您将了解:
- RNN的结构
- RNN在给定输入时如何计算输出
- 如何为Keras中的SimpleRNN准备数据
- 如何训练SimpleRNN模型
通过我的书 《Transformer模型与注意力机制构建》 开启您的项目。它提供了自学教程和工作代码,指导您构建一个能够
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

理解Keras中的简单循环神经网络。图片来自Mehreen Saeed,部分权利保留。
教程概述
本教程分为两部分;它们是
- RNN的结构
- RNN不同层相关的不同权重和偏差
- 在给定输入时计算输出的计算方式
- 时间序列预测的完整应用程序
先决条件
假定您在开始实现RNN之前已经具备RNN的基础知识。《循环神经网络入门及驱动它们的数学原理》可以帮助您快速了解RNN。
现在我们开始实现部分。
导入部分
为了开始实现RNN,让我们添加导入部分。
|
1 2 3 4 5 6 7 8 |
from pandas import read_csv import numpy as np from keras.models import Sequential from keras.layers import Dense, SimpleRNN from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error import math import matplotlib.pyplot as plt |
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Keras SimpleRNN
下面的函数返回一个包含SimpleRNN层和Dense层的模型,用于学习序列数据。input_shape指定参数(time_steps x features)。我们将简化一切,使用单变量数据,即只有一个特征;时间步长将在下面讨论。
|
1 2 3 4 5 6 7 8 9 |
def create_RNN(hidden_units, dense_units, input_shape, activation): model = Sequential() model.add(SimpleRNN(hidden_units, input_shape=input_shape, activation=activation[0])) model.add(Dense(units=dense_units, activation=activation[1])) model.compile(loss='mean_squared_error', optimizer='adam') 返回 model demo_model = create_RNN(2, 1, (3,1), activation=['linear', 'linear']) |
对象demo_model返回,其中包含通过SimpleRNN层创建的两个隐藏单元和通过Dense层创建的一个密集单元。input_shape设置为3x1,并且为了简单起见,两个层都使用了线性激活函数。回想一下,线性激活函数 $f(x) = x$ 对输入不做任何改变。网络如下所示
如果我们有$m$个隐藏单元(上面情况,$m=2$),则
- 输入:$x \in R$
- 隐藏单元:$h \in R^m$
- 输入单元的权重:$w_x \in R^m$
- 隐藏单元的权重:$w_h \in R^{mxm}$
- 隐藏单元的偏差:$b_h \in R^m$
- 密集层的权重:$w_y \in R^m$
- 密集层的偏差:$b_y \in R$
让我们看看上面的权重。注意:由于权重是随机初始化的,此处显示的权重结果将与您的不同。重要的是要了解正在使用的每个对象的结构是什么样的,以及它如何与其他对象交互以产生最终输出。
|
1 2 3 4 5 6 7 |
wx = demo_model.get_weights()[0] wh = demo_model.get_weights()[1] bh = demo_model.get_weights()[2] wy = demo_model.get_weights()[3] by = demo_model.get_weights()[4] print('wx = ', wx, ' wh = ', wh, ' bh = ', bh, ' wy =', wy, 'by = ', by) |
|
1 2 3 |
wx = [[ 0.18662322 -1.2369459 ]] wh = [[ 0.86981213 -0.49338293] [ 0.49338293 0.8698122 ]] bh = [0. 0.] wy = [[-0.4635998] [ 0.6538409]] by = [0.] |
现在让我们做一个简单的实验,看看SimpleRNN和Dense层的输出是如何产生的。请牢记此图。
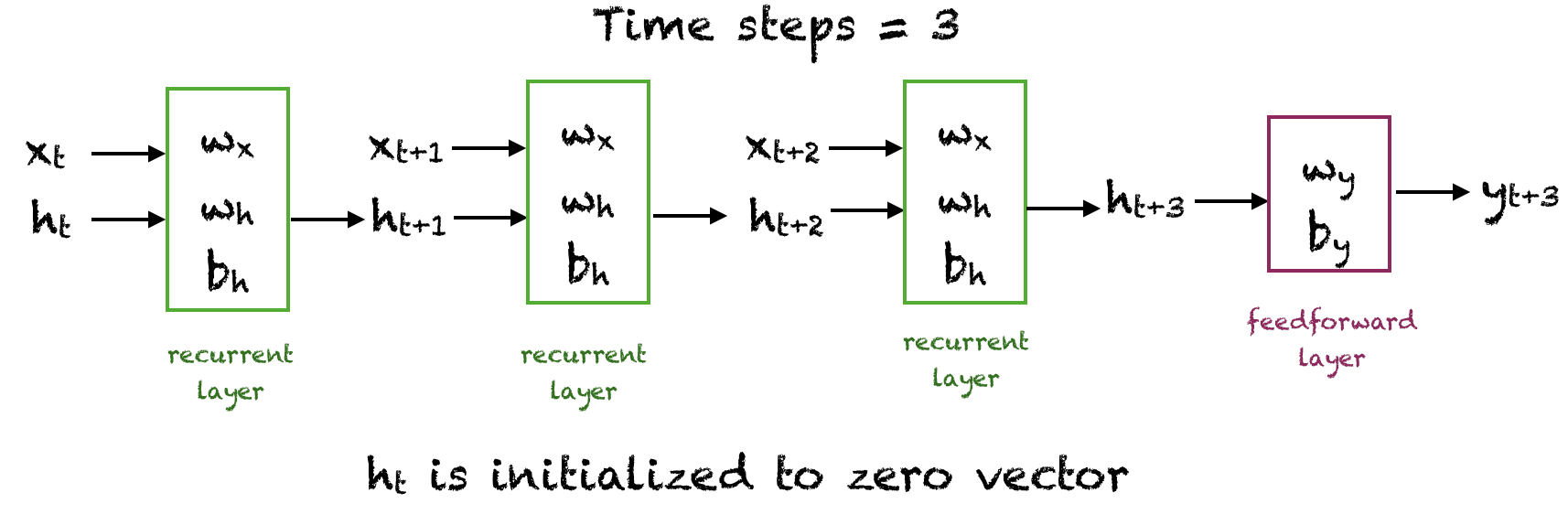
循环神经网络的层
我们将输入x经过三个时间步,让网络生成一个输出。将计算时间步1、2和3的隐藏单元的值。$h_0$初始化为零向量。输出$o_3$由$h_3$和$w_y$计算得出。由于我们使用的是线性单元,因此不需要激活函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
x = np.array([1, 2, 3]) # 将输入重塑为所需的 sample_size x time_steps x features x_input = np.reshape(x,(1, 3, 1)) y_pred_model = demo_model.predict(x_input) m = 2 h0 = np.zeros(m) h1 = np.dot(x[0], wx) + h0 + bh h2 = np.dot(x[1], wx) + np.dot(h1,wh) + bh h3 = np.dot(x[2], wx) + np.dot(h2,wh) + bh o3 = np.dot(h3, wy) + by print('h1 = ', h1,'h2 = ', h2,'h3 = ', h3) print("Prediction from network ", y_pred_model) print("Prediction from our computation ", o3) |
|
1 2 3 |
h1 = [[ 0.18662322 -1.23694587]] h2 = [[-0.07471441 -3.64187904]] h3 = [[-1.30195881 -6.84172557]] Prediction from network [[-3.8698118]] Prediction from our computation [[-3.86981216]] |
在太阳黑子数据集上运行RNN
现在我们已经了解了SimpleRNN和Dense层是如何组合在一起的。让我们在一个简单的时间序列数据集上运行一个完整的RNN。我们需要遵循以下步骤:
- 从给定的URL读取数据集
- 将数据分割成训练集和测试集
- 将输入准备成Keras所需的格式
- 创建一个RNN模型并进行训练
- 在训练集和测试集上进行预测,并打印两个集合的均方根误差
- 查看结果
步骤1、2:读取数据并分割成训练集和测试集
下面的函数从给定的URL读取训练和测试数据,并将其分割成指定百分比的训练和测试数据。它返回训练和测试数据的单维数组,同时使用scikit-learn中的MinMaxScaler将数据缩放到0到1之间。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 参数 split_percent 定义了训练样本的比例 def get_train_test(url, split_percent=0.8): df = read_csv(url, usecols=[1], engine='python') data = np.array(df.values.astype('float32')) scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data).flatten() n = len(data) # 用于分割训练和测试数据的点 split = int(n*split_percent) train_data = data[range(split)] test_data = data[split:] return train_data, test_data, data sunspots_url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-sunspots.csv' train_data, test_data, data = get_train_test(sunspots_url) |
步骤3:为Keras重塑数据
下一步是准备Keras模型训练的数据。输入数组的形状应为:total_samples x time_steps x features。
有很多方法可以准备时间序列数据进行训练。我们将创建具有不重叠时间步的输入行。下面的图示为时间步=2的例子。这里,时间步表示用于预测时间序列数据下一个值的先前时间步的数量。
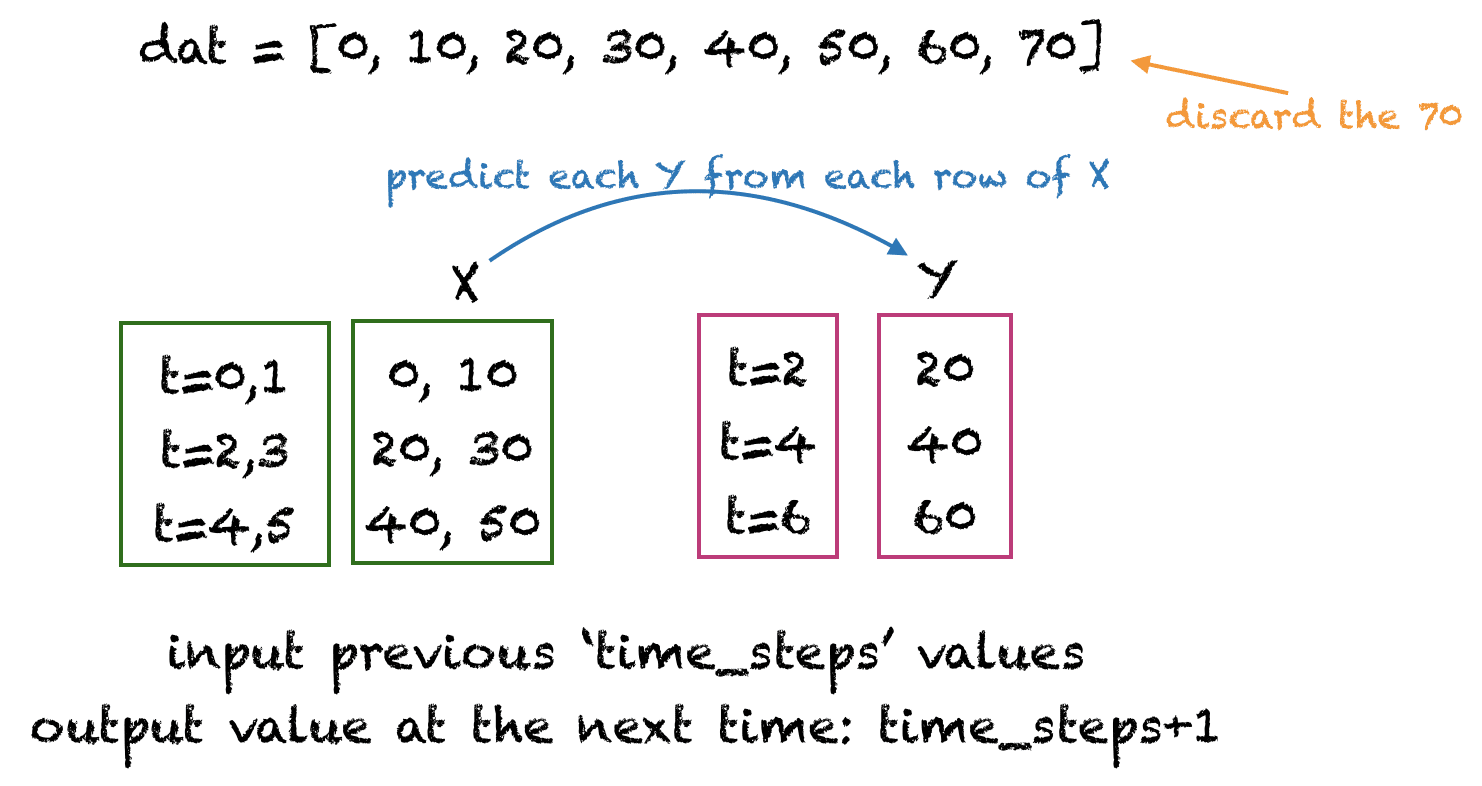
太阳黑子示例的数据准备方式
下面的get_XY()函数以一维数组作为输入,并将其转换为所需的输入X和目标Y数组。我们将为太阳黑子数据集使用12个time_steps,因为太阳黑子通常有12个月的周期。您可以尝试其他time_steps值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 准备输入 X 和目标 Y def get_XY(dat, time_steps): # 目标数组的索引 Y_ind = np.arange(time_steps, len(dat), time_steps) Y = dat[Y_ind] # 准备 X rows_x = len(Y) X = dat[range(time_steps*rows_x)] X = np.reshape(X, (rows_x, time_steps, 1)) return X, Y time_steps = 12 trainX, trainY = get_XY(train_data, time_steps) testX, testY = get_XY(test_data, time_steps) |
步骤4:创建RNN模型并进行训练
在此步骤中,您可以重用上面定义的create_RNN()函数。
|
1 2 3 |
model = create_RNN(hidden_units=3, dense_units=1, input_shape=(time_steps,1), activation=['tanh', 'tanh']) model.fit(trainX, trainY, epochs=20, batch_size=1, verbose=2) |
步骤5:计算并打印均方根误差
print_error()函数计算实际值和预测值之间的均方误差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def print_error(trainY, testY, train_predict, test_predict): # 预测的误差 train_rmse = math.sqrt(mean_squared_error(trainY, train_predict)) test_rmse = math.sqrt(mean_squared_error(testY, test_predict)) # 打印RMSE print('Train RMSE: %.3f RMSE' % (train_rmse)) print('Test RMSE: %.3f RMSE' % (test_rmse)) # 进行预测 train_predict = model.predict(trainX) test_predict = model.predict(testX) # 均方误差 print_error(trainY, testY, train_predict, test_predict) |
|
1 2 |
Train RMSE: 0.058 RMSE Test RMSE: 0.077 RMSE |
步骤6:查看结果
下面的函数绘制实际目标值和预测值。红线分隔了训练和测试数据点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 绘制结果 def plot_result(trainY, testY, train_predict, test_predict): actual = np.append(trainY, testY) predictions = np.append(train_predict, test_predict) rows = len(actual) plt.figure(figsize=(15, 6), dpi=80) plt.plot(range(rows), actual) plt.plot(range(rows), predictions) plt.axvline(x=len(trainY), color='r') plt.legend(['Actual', 'Predictions']) plt.xlabel('Observation number after given time steps') plt.ylabel('Sunspots scaled') plt.title('Actual and Predicted Values. The Red Line Separates The Training And Test Examples') plot_result(trainY, testY, train_predict, test_predict) |
生成的图表如下:
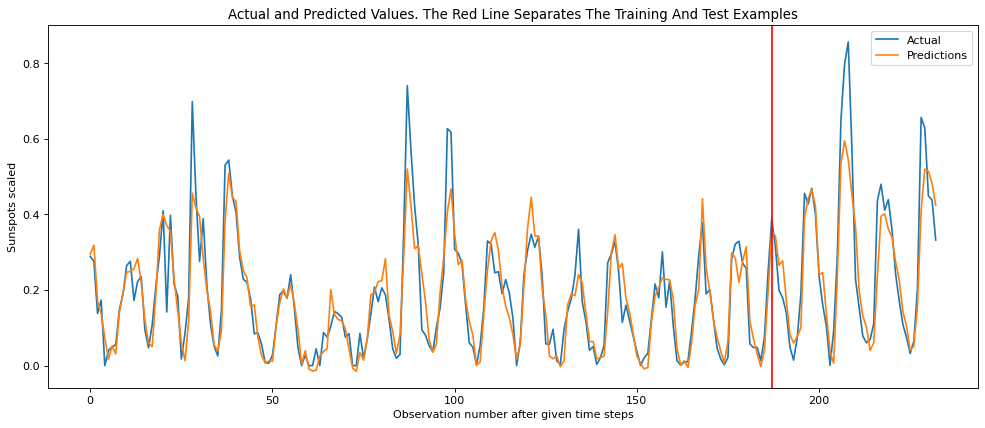
合并代码
本教程的全部代码如下。请在您自己的环境中尝试,并试验不同的隐藏单元和时间步长。您可以向网络添加第二个SimpleRNN,看看它的行为如何。您还可以使用scaler对象将数据重新缩放到其正常范围。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# 参数 split_percent 定义了训练样本的比例 def get_train_test(url, split_percent=0.8): df = read_csv(url, usecols=[1], engine='python') data = np.array(df.values.astype('float32')) scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data).flatten() n = len(data) # 用于分割训练和测试数据的点 split = int(n*split_percent) train_data = data[range(split)] test_data = data[split:] return train_data, test_data, data # 准备输入 X 和目标 Y def get_XY(dat, time_steps): Y_ind = np.arange(time_steps, len(dat), time_steps) Y = dat[Y_ind] rows_x = len(Y) X = dat[range(time_steps*rows_x)] X = np.reshape(X, (rows_x, time_steps, 1)) return X, Y def create_RNN(hidden_units, dense_units, input_shape, activation): model = Sequential() model.add(SimpleRNN(hidden_units, input_shape=input_shape, activation=activation[0])) model.add(Dense(units=dense_units, activation=activation[1])) model.compile(loss='mean_squared_error', optimizer='adam') 返回 model def print_error(trainY, testY, train_predict, test_predict): # 预测的误差 train_rmse = math.sqrt(mean_squared_error(trainY, train_predict)) test_rmse = math.sqrt(mean_squared_error(testY, test_predict)) # 打印RMSE print('Train RMSE: %.3f RMSE' % (train_rmse)) print('Test RMSE: %.3f RMSE' % (test_rmse)) # 绘制结果 def plot_result(trainY, testY, train_predict, test_predict): actual = np.append(trainY, testY) predictions = np.append(train_predict, test_predict) rows = len(actual) plt.figure(figsize=(15, 6), dpi=80) plt.plot(range(rows), actual) plt.plot(range(rows), predictions) plt.axvline(x=len(trainY), color='r') plt.legend(['Actual', 'Predictions']) plt.xlabel('Observation number after given time steps') plt.ylabel('Sunspots scaled') plt.title('Actual and Predicted Values. The Red Line Separates The Training And Test Examples') sunspots_url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-sunspots.csv' time_steps = 12 train_data, test_data, data = get_train_test(sunspots_url) trainX, trainY = get_XY(train_data, time_steps) testX, testY = get_XY(test_data, time_steps) # 创建模型并进行训练 model = create_RNN(hidden_units=3, dense_units=1, input_shape=(time_steps,1), activation=['tanh', 'tanh']) model.fit(trainX, trainY, epochs=20, batch_size=1, verbose=2) # 进行预测 train_predict = model.predict(trainX) test_predict = model.predict(testX) # 打印错误 print_error(trainY, testY, train_predict, test_predict) # 绘制结果 plot_result(trainY, testY, train_predict, test_predict) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 深度学习入门 by Wei Di, Anurag Bhardwaj, and Jianing Wei.
- 深度学习 by Ian Goodfellow, Joshua Bengio, and Aaron Courville.
文章
总结
在本教程中,您了解了循环神经网络及其各种架构。
具体来说,你学到了:
- RNN的结构
- RNN如何从先前的输入计算输出
- 如何使用RNN实现端到端的时序预测系统
Do you have any questions about RNNs discussed in this post? Ask your questions in the comments below, and I will do my best to answer.
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






当我使用tensorflow.keras时,在create_RNN()中抛出了NotImplementedError。我应该更新什么?谢谢。
create_RNN() 是这里定义的函数。哪一行触发了NotImplementedError?
在“model.add(SimpleRNN(hidden_units, input_shape=input_shape, activation=activation[0]))”中
错误在
~/anaconda3/envs/py38/lib/python3.8/site-packages/tensorflow/python/framework/ops.py in __array__(self)
850
851 def __array__(self)
–> 852 raise NotImplementedError(
853 “Cannot convert a symbolic Tensor ({}) to a numpy array.”
854 ” 此错误可能表明您尝试将 Tensor 传递给”
NotImplementedError: 无法将符号张量 (simple_rnn/strided_slice:0) 转换为 numpy 数组。此错误可能表明您尝试将张量传递给 NumPy 调用,这是不支持的
Python 版本是 3.8.12
Tensorflow 版本是 2.4.1
谢谢。
错误仍然没有修复 NotImplementedError: 无法将符号张量 (simple_rnn_1/strided_slice:0) 转换为 numpy 数组。此错误可能表明您尝试将张量传递给 NumPy 调用,这是不支持的
你好 Master56^^…请提供完整的代码列表和你的 Python 编码环境的描述。
此致,
你好 Mehran,
感谢您提供如此有见地的帖子!我浏览了其他在线课程和实验室的学习材料,但直到我读了您的帖子,我才真正掌握 RNN 中到底发生了什么。它写得非常好,而且清晰明了。代码同样非常容易遵循,我希望在此示例的基础上进行扩展,为我的研究项目实现 RNN!
祝好,
Tommy
Tommy,感谢你的精彩反馈!我们感谢你的支持和反馈!
非常棒的帖子!
我可能发现了一个小小的拼写错误
h1 = np.dot(x[0], wx) + h0 + bh
应该是
h1 = np.dot(x[0], wx) + np.dot(h0,wh) + bh
无论如何,结果没有改变,因为 h0 是全零
谢谢 Paolo!我们感谢您的反馈。
我们需要关于这个的更多信息,并且它也可以在 colab 或 jupyter 中复制粘贴执行
你好 cesiy…您是否成功执行了示例代码?如果没有,请告诉我们有什么不工作或您收到的任何错误消息。
谢谢!那么一个序列具有多个特征(每个时间步)的情况呢?我尝试了以下方法,但 Keras 输出一个值,而手动计算输出两个值
# hidden_units, dense_units, input_shape, activation
m = 2
demo_model = create_RNN(m, 1, (3,2), activation=[‘tanh’, ‘linear’])
wx = demo_model.get_weights()[0]
wh = demo_model.get_weights()[1]
bh = demo_model.get_weights()[2]
wy = demo_model.get_weights()[3]
by = demo_model.get_weights()[4]
print(‘wx = ‘, wx, ‘\nwh = ‘, wh, ‘\nbh = ‘, bh, ‘\nwy =’, wy, ‘\nby = ‘, by)
x = np.array([1,0.1, 2,0.2, 3,0.3])
# 将输入重塑为所需的 sample_size x time_steps x features
x_input = np.reshape(x,(1, 3, 2))
print(‘x =’, x)
print(‘x_reshaped = ‘, x_input)
y_pred_model = demo_model.predict(x_input)
h0 = np.zeros(m)
h1 = np.tanh(np.dot(x[0], wx) + np.dot(h0,wh) + bh)
h2 = np.tanh(np.dot(x[1], wx) + np.dot(h1,wh) + bh)
h3 = np.tanh(np.dot(x[2], wx) + np.dot(h2,wh) + bh)
o3 = np.dot(h3, wy) + by
print(‘h1 = ‘, h1, ‘h2 = ‘, h2, ‘h3 = ‘, h3)
print(“来自网络的预测 “, y_pred_model)
print(“来自我们计算的预测 “, o3)
输出
来自网络的预测 [[0.09162921]]
来自我们计算的预测 [[ 0.14343597] [-0.27000149]]
你好 Tasos…谢谢你的反馈!我们将审查此场景。
你好,我目前正在使用这个数据集,我需要使用一个分割(训练、测试、验证),其中训练:从第一行到 1965 行,验证:从 1966 行到 1975 行,测试:从 1976 行到最后一行。我目前不熟悉这种语言,因为我刚开始使用 Rstudio,而且我找不到解决方案,所以我想尽快得到答复。非常感谢。
你好 Odise…以下资源提供了在应用训练、测试和验证时的最佳实践。
https://machinelearning.org.cn/training-validation-test-split-and-cross-validation-done-right/
你好,
在第一个示例(Keras simpleRNN)中,您在没有训练模型的情况下获得了权重(编译模型后没有 fit 函数)
这是怎么回事?
提前感谢
还有一个问题,拜托
在第一个示例(Keras Simple RNN)中;
y_pred_model=demo_model.predict(x_input)
print(“来自网络的预测 “, y_pred_model)
我得到:[[-1.1634194]]!!
我只是复制并粘贴了您提供的代码
我有点困惑,时间步是序列的长度还是序列的数量?例如,我有 (16230,1),我想使用 24 作为时间步,所以它变成 (680,24,1),其中 680 是样本数,24 是时间步的长度,1 是特征。请问我说的对吗?