在了解了如何实现 Transformer 模型的缩放点积注意力和多头注意力之后,让我们通过应用其编码器来进一步实现一个完整的 Transformer 模型。我们的最终目标仍然是将整个模型应用于自然语言处理(NLP)。
在本教程中,您将了解如何在 TensorFlow 和 Keras 中从头开始实现 Transformer Encoder。
完成本教程后,您将了解:
- 构成 Transformer Encoder 的层。
- 如何从头开始实现 Transformer Encoder。
通过我的书《Transformer 模型与注意力机制》来启动您的项目。它提供了自学教程和可运行的代码,指导您构建一个功能齐全的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

在 TensorFlow 和 Keras 中从头开始实现 Transformer Encoder
照片由 ian dooley 拍摄,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- Transformer 架构回顾
- Transformer Encoder
- 从头开始实现 Transformer Encoder
- 全连接前馈神经网络和层归一化
- Encoder 层
- Transformer Encoder
- 测试代码
先决条件
本教程假设您已熟悉以下内容:
Transformer 架构回顾
回想一下,Transformer 架构遵循编码器-解码器结构。左侧的编码器负责将输入序列映射到一系列连续表示;右侧的解码器接收编码器的输出以及前一个时间步的解码器输出,以生成输出序列。
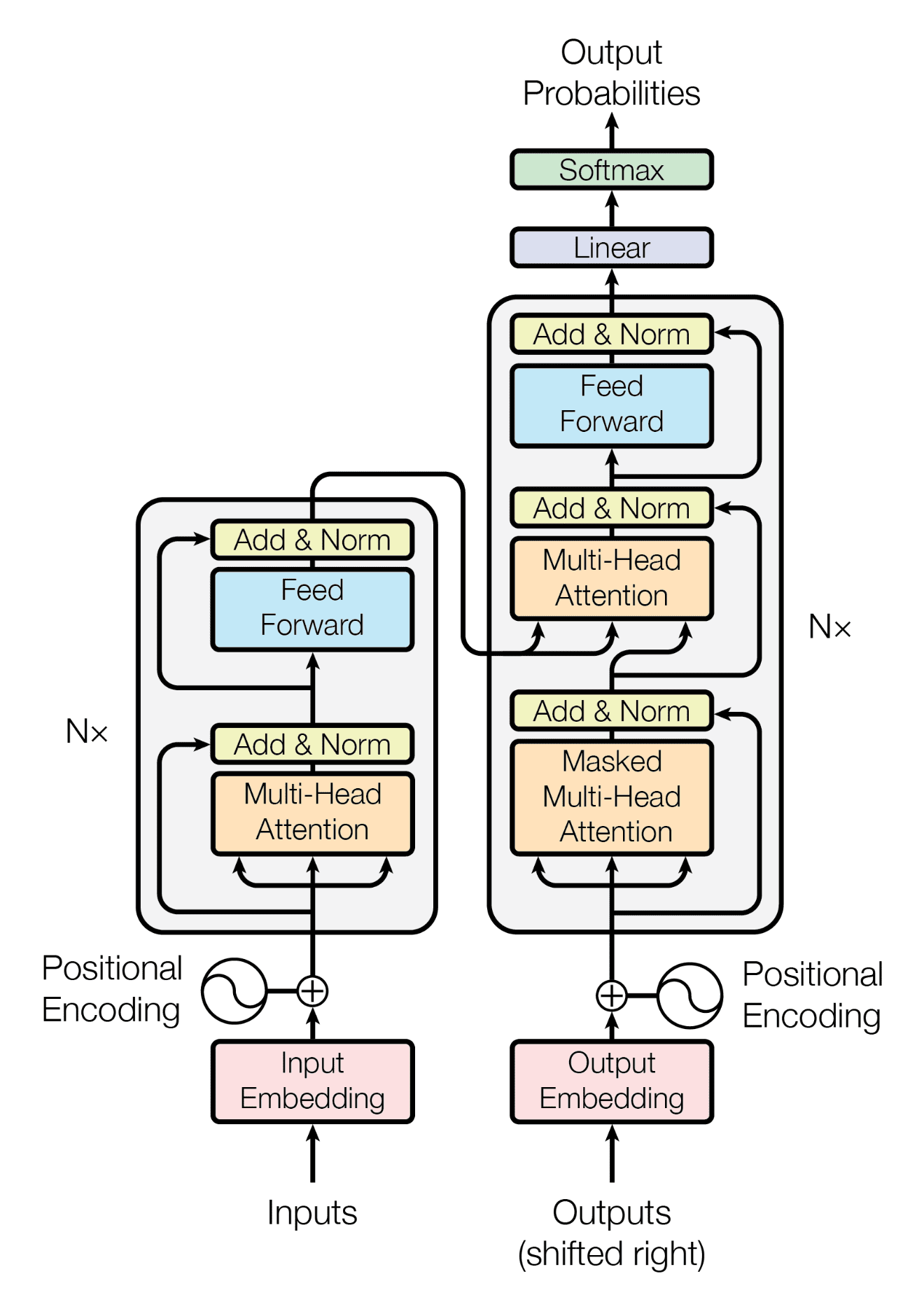
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
在生成输出序列时,Transformer 不依赖于循环和卷积。
您已经看到 Transformer 的解码器部分在其架构上与编码器有很多相似之处。在本教程中,您将重点关注构成 Transformer Encoder 的组件。
Transformer Encoder
Transformer Encoder 由 $N$ 个相同的层组成,每一层又包含两个主要子层。
- 第一个子层包含一个接收查询、键和值作为输入的自注意力机制。
- 第二个子层包含一个全连接前馈网络。
Transformer 架构的 Encoder 块
摘自“Attention Is All You Need”
在每个子层之后,都应用了层归一化,其中子层的输入(通过残差连接)和输出被馈入。每个层归一化步骤的输出如下:
LayerNorm(子层输入 + 子层输出)
为了实现这种涉及子层输入和输出之间加法的操作,Vaswani 等人设计了模型中的所有子层和嵌入层,使其输出维度为 $d_{\text{model}}$ = 512。
另外,回想一下,查询、键和值是 Transformer Encoder 的输入。
在这里,查询、键和值承载了经过嵌入并增强了位置信息后的相同输入序列,其中查询和键的维度为 $d_k$,值的维度为 $d_v$。
此外,Vaswani 等人还通过在每个子层(层归一化步骤之前)的输出以及在位置编码馈入编码器之前应用 Dropout 来引入正则化。
现在让我们看看如何在 TensorFlow 和 Keras 中从头开始实现 Transformer Encoder。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
在 TensorFlow 和 Keras 中从头开始实现 Transformer Encoder
全连接前馈神经网络和层归一化
让我们从创建图中所示的*前馈*和*Add & Norm*层的类开始。
Vaswani 等人指出,全连接前馈网络由两个线性变换组成,中间有一个 ReLU 激活。第一个线性变换的输出维度为 $d_{ff}$ = 2048,第二个线性变换的输出维度为 $d_{\text{model}}$ = 512。
为此,让我们首先创建 FeedForward 类,它继承自 Keras 的 Layer 基类,并初始化密集层和 ReLU 激活。
|
1 2 3 4 5 6 7 |
class FeedForward(Layer): def __init__(self, d_ff, d_model, **kwargs): super(FeedForward, self).__init__(**kwargs) self.fully_connected1 = Dense(d_ff) # 第一个全连接层 self.fully_connected2 = Dense(d_model) # 第二个全连接层 self.activation = ReLU() # ReLU 激活层 ... |
我们将添加 call() 类方法,该方法接收输入,将其通过两个带 ReLU 激活的全连接层,并返回维度为 512 的输出。
|
1 2 3 4 5 6 |
... def call(self, x): # 输入被传递给两个全连接层,中间有一个 ReLU x_fc1 = self.fully_connected1(x) return self.fully_connected2(self.activation(x_fc1)) |
下一步是创建另一个类 AddNormalization,它也继承自 Keras 的 Layer 基类,并初始化一个层归一化层。
|
1 2 3 4 5 |
class AddNormalization(Layer): def __init__(self, **kwargs): super(AddNormalization, self).__init__(**kwargs) self.layer_norm = LayerNormalization() # 层归一化层 ... |
在该方法中,包含将子层的输入和输出相加并对结果应用层归一化的类方法。
|
1 2 3 4 5 6 7 |
... def call(self, x, sublayer_x): # 子层的输入和输出需要具有相同的形状才能相加 add = x + sublayer_x # 对和应用层归一化 return self.layer_norm(add) |
Encoder 层
接下来,您将实现 Encoder 层,Transformer Encoder 将对其进行 $N$ 次相同的复制。
为此,让我们创建 EncoderLayer 类,并初始化它包含的所有子层。
|
1 2 3 4 5 6 7 8 9 10 |
class EncoderLayer(Layer): def __init__(self, h, d_k, d_v, d_model, d_ff, rate, **kwargs): super(EncoderLayer, self).__init__(**kwargs) self.multihead_attention = MultiHeadAttention(h, d_k, d_v, d_model) self.dropout1 = Dropout(rate) self.add_norm1 = AddNormalization() self.feed_forward = FeedForward(d_ff, d_model) self.dropout2 = Dropout(rate) self.add_norm2 = AddNormalization() ... |
在这里,您可能会注意到您已经初始化了 FeedForward 和 AddNormalization 类的实例,这些类刚刚在上一节中创建,并将它们的输出分别赋给了变量 feed_forward 和 add_norm(1 和 2)。Dropout 层不言自明,其中 rate 定义了输入单元被设置为 0 的频率。您在之前的教程中创建了 MultiHeadAttention 类,如果您将代码保存到单独的 Python 脚本中,请不要忘记 import 它。我将我的代码保存在一个名为 *multihead_attention.py* 的 Python 脚本中,因此我需要包含代码行 *from multihead_attention import MultiHeadAttention*。
现在让我们继续创建 call() 类方法,该方法实现所有 Encoder 子层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
... def call(self, x, padding_mask, training): # 多头注意力层 multihead_output = self.multihead_attention(x, x, x, padding_mask) # 期望的输出形状 = (batch_size, sequence_length, d_model) # 添加 Dropout 层 multihead_output = self.dropout1(multihead_output, training=training) # 后面是 Add & Norm 层 addnorm_output = self.add_norm1(x, multihead_output) # 期望的输出形状 = (batch_size, sequence_length, d_model) # 后面是全连接层 feedforward_output = self.feed_forward(addnorm_output) # 期望的输出形状 = (batch_size, sequence_length, d_model) # 添加另一个 Dropout 层 feedforward_output = self.dropout2(feedforward_output, training=training) # 后面是另一个 Add & Norm 层 return self.add_norm2(addnorm_output, feedforward_output) |
除了输入数据外,call() 方法还可以接收填充掩码。简要回顾一下在之前的教程中提到的内容,*填充*掩码是为了防止输入序列中的零填充与实际输入值一起被处理。
同样的方法也可以接收一个 training 标志,当设置为 True 时,Dropout 层只在训练时应用。
Transformer Encoder
最后一步是为 Transformer Encoder 创建一个类,该类应命名为 Encoder。
|
1 2 3 4 5 6 7 |
class Encoder(Layer): def __init__(self, vocab_size, sequence_length, h, d_k, d_v, d_model, d_ff, n, rate, **kwargs): super(Encoder, self).__init__(**kwargs) self.pos_encoding = PositionEmbeddingFixedWeights(sequence_length, vocab_size, d_model) self.dropout = Dropout(rate) self.encoder_layer = [EncoderLayer(h, d_k, d_v, d_model, d_ff, rate) for _ in range(n)] ... |
Transformer Encoder 接收输入序列,该序列在经过词嵌入和位置编码过程后得到。为了计算位置编码,让我们利用 Mehreen Saeed 在这篇教程中描述的 PositionEmbeddingFixedWeights 类。
正如您在前面的部分中所做的那样,在这里,您还将创建一个 call() 类方法,该方法将词嵌入和位置编码应用于输入序列,并将结果馈送给 $N$ 个 Encoder 层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... def call(self, input_sentence, padding_mask, training): # 生成位置编码 pos_encoding_output = self.pos_encoding(input_sentence) # 期望的输出形状 = (batch_size, sequence_length, d_model) # 添加 Dropout 层 x = self.dropout(pos_encoding_output, training=training) # 将位置编码后的值传递给每个 Encoder 层 for i, layer in enumerate(self.encoder_layer): x = layer(x, padding_mask, training) return x |
完整的 Transformer Encoder 代码列表如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
from tensorflow.keras.layers import LayerNormalization, Layer, Dense, ReLU, Dropout from multihead_attention import MultiHeadAttention from positional_encoding import PositionEmbeddingFixedWeights # 实现 Add & Norm 层 class AddNormalization(Layer): def __init__(self, **kwargs): super(AddNormalization, self).__init__(**kwargs) self.layer_norm = LayerNormalization() # 层归一化层 def call(self, x, sublayer_x): # 子层的输入和输出需要具有相同的形状才能相加 add = x + sublayer_x # 对和应用层归一化 return self.layer_norm(add) # 实现前馈层 class FeedForward(Layer): def __init__(self, d_ff, d_model, **kwargs): super(FeedForward, self).__init__(**kwargs) self.fully_connected1 = Dense(d_ff) # 第一个全连接层 self.fully_connected2 = Dense(d_model) # 第二个全连接层 self.activation = ReLU() # ReLU 激活层 def call(self, x): # 输入被传递到两个全连接层,中间有一个 ReLU 激活函数 x_fc1 = self.fully_connected1(x) return self.fully_connected2(self.activation(x_fc1)) # 实现 Encoder Layer (编码器层) class EncoderLayer(Layer): def __init__(self, h, d_k, d_v, d_model, d_ff, rate, **kwargs): super(EncoderLayer, self).__init__(**kwargs) self.multihead_attention = MultiHeadAttention(h, d_k, d_v, d_model) self.dropout1 = Dropout(rate) self.add_norm1 = AddNormalization() self.feed_forward = FeedForward(d_ff, d_model) self.dropout2 = Dropout(rate) self.add_norm2 = AddNormalization() def call(self, x, padding_mask, training): # 多头注意力层 multihead_output = self.multihead_attention(x, x, x, padding_mask) # 预期输出形状 = (batch_size, sequence_length, d_model) # 添加一个 Dropout 层 multihead_output = self.dropout1(multihead_output, training=training) # 后面跟着一个 Add & Norm 层 (加法和归一化层) addnorm_output = self.add_norm1(x, multihead_output) # 预期输出形状 = (batch_size, sequence_length, d_model) # 后面跟着一个全连接层 feedforward_output = self.feed_forward(addnorm_output) # 预期输出形状 = (batch_size, sequence_length, d_model) # 添加另一个 Dropout 层 feedforward_output = self.dropout2(feedforward_output, training=training) # 后面跟着另一个 Add & Norm 层 (加法和归一化层) return self.add_norm2(addnorm_output, feedforward_output) # 实现 Encoder (编码器) class Encoder(Layer): def __init__(self, vocab_size, sequence_length, h, d_k, d_v, d_model, d_ff, n, rate, **kwargs): super(Encoder, self).__init__(**kwargs) self.pos_encoding = PositionEmbeddingFixedWeights(sequence_length, vocab_size, d_model) self.dropout = Dropout(rate) self.encoder_layer = [EncoderLayer(h, d_k, d_v, d_model, d_ff, rate) for _ in range(n)] def call(self, input_sentence, padding_mask, training): # 生成位置编码 pos_encoding_output = self.pos_encoding(input_sentence) # 预期输出形状 = (batch_size, sequence_length, d_model) # 添加一个 Dropout 层 x = self.dropout(pos_encoding_output, training=training) # 将位置编码后的值传递给每个编码器层 for i, layer in enumerate(self.encoder_layer): x = layer(x, padding_mask, training) return x |
测试代码
我们将使用 Vaswani 等人 (2017) 的论文 《Attention Is All You Need》中指定的参数值。
|
1 2 3 4 5 6 7 8 9 10 |
h = 8 # 自注意力头的数量 d_k = 64 # 线性投影的查询和键的维度 d_v = 64 # 线性投影的值的维度 d_ff = 2048 # 内部全连接层的维度 d_model = 512 # 模型子层输出的维度 n = 6 # 编码器堆栈中的层数 batch_size = 64 # 训练过程中的批次大小 dropout_rate = 0.1 # Dropout 层中输入单元的丢弃频率 ... |
至于输入序列,在您到达在另一个教程中 训练完整的 Transformer 模型 的阶段之前,您将使用模拟数据,届时您将使用实际的句子。
|
1 2 3 4 5 6 |
... enc_vocab_size = 20 # 编码器的词汇表大小 input_seq_length = 5 # 输入序列的最大长度 input_seq = random.random((batch_size, input_seq_length)) ... |
接下来,您将创建一个 Encoder 类的实例,将其输出分配给 encoder 变量,然后输入输入参数,并打印结果。您暂时将 padding_mask 参数设置为 None,但当您实现完整的 Transformer 模型时会再回头处理它。
|
1 2 3 |
... encoder = Encoder(enc_vocab_size, input_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate) print(encoder(input_seq, None, True)) |
将所有内容结合起来,生成以下代码清单
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from numpy import random enc_vocab_size = 20 # 编码器的词汇表大小 input_seq_length = 5 # 输入序列的最大长度 h = 8 # 自注意力头的数量 d_k = 64 # 线性投影的查询和键的维度 d_v = 64 # 线性投影的值的维度 d_ff = 2048 # 内部全连接层的维度 d_model = 512 # 模型子层输出的维度 n = 6 # 编码器堆栈中的层数 batch_size = 64 # 训练过程中的批次大小 dropout_rate = 0.1 # Dropout 层中输入单元的丢弃频率 input_seq = random.random((batch_size, input_seq_length)) encoder = Encoder(enc_vocab_size, input_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate) print(encoder(input_seq, None, True)) |
运行此代码将生成一个形状为 (batch size, sequence length, model dimensionality) 的输出。请注意,由于输入序列的随机初始化和 Dense 层的参数值,您看到的输出可能会有所不同。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
tf.Tensor( [[[-0.4214715 -1.1246173 -0.8444572 ... 1.6388322 -0.1890367 1.0173352 ] [ 0.21662089 -0.61147404 -1.0946581 ... 1.4627445 -0.6000164 -0.64127874] [ 0.46674493 -1.4155326 -0.5686513 ... 1.1790234 -0.94788337 0.1331717 ] [-0.30638126 -1.9047263 -1.8556844 ... 0.9130118 -0.47863355 0.00976158] [-0.22600567 -0.9702025 -0.91090447 ... 1.7457147 -0.139926 -0.07021569]] ... [[-0.48047638 -1.1034104 -0.16164204 ... 1.5588069 0.08743562 -0.08847156] [-0.61683714 -0.8403657 -1.0450369 ... 2.3587787 -0.76091915 -0.02891812] [-0.34268388 -0.65042275 -0.6715749 ... 2.8530657 -0.33631966 0.5215888 ] [-0.6288677 -1.0030932 -0.9749813 ... 2.1386387 0.0640307 -0.69504136] [-1.33254 -1.2524267 -0.230098 ... 2.515467 -0.04207756 -0.3395423 ]]], shape=(64, 5, 512), dtype=float32) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019
- 用于自然语言处理的 Transformer, 2021
论文
- 注意力就是你所需要的一切, 2017
总结
在本教程中,您学习了如何从头开始在 TensorFlow 和 Keras 中实现 Transformer 编码器。
具体来说,你学到了:
- 构成 Transformer 编码器的层
- 如何从头开始实现 Transformer 编码器
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






你好 Stefania,
感谢这篇精彩的文章。我还在阅读《使用注意力构建 Transformer 模型》这本书。我有一个关于“Transformer 的位置编码”的第 14.4 章的问题。
在这里,我不太理解为什么您要使用
word_embedding_matrix = self.get_position_encoding(vocab_size, output_dim)
来初始化 word_embedding_matrix,引用论文“Attention Is All You Need”。
我不太明白这个“get_position_encoding”方法是如何将单词表示为嵌入的。您能帮我解答一下吗?
谢谢!!
这可能有点令人困惑,但您可以尝试将其视为一种生成随机矩阵的方式。词嵌入矩阵只是用于编码单词(大约有 10,000 个),将其映射到更短的向量(例如,50 个浮点数)。我们不希望两个不相关的、不同的单词共享相同的向量。因此,最好将嵌入矩阵随机化,但也要保证它不会“冲突”。碰巧位置编码满足这个属性,因此在这里被滥用了。
事实上,您也可以使用 numpy.random 来生成一个随机矩阵。但在这种情况下,最好也设置“trainable=True”,让 Keras 进行微调,以避免不必要的冲突。
好的,现在明白了。感谢您的澄清,Adrian。MachineLearningMastery 始终是我学习数据科学的最佳导师。继续加油!!!
您好,老师,我正在尝试将上述代码应用于单变量风力发电数据。是否可以修改上述代码以用于风力发电(时间序列)数据?
您好 Bashir…是的,这是可能的。请继续,如果您有任何问题,请告诉我们!