我们已经熟悉了Transformer 模型背后的理论及其注意力机制。我们已经通过了解如何实现缩放点积注意力,开始了实现完整模型的旅程。现在,我们将通过将缩放点积注意力封装到多头注意力机制中,这是其核心组成部分,从而进一步推进我们的旅程。我们的最终目标仍然是将完整模型应用于自然语言处理(NLP)。
在本教程中,您将学习如何在 TensorFlow 和 Keras 中从头开始实现多头注意力。
完成本教程后,您将了解:
- 构成多头注意力机制的层。
- 如何从头开始实现多头注意力机制。
通过我的书《构建带注意力的 Transformer 模型》来启动您的项目。它提供了自学教程和工作代码,指导您构建一个能够
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

如何在 TensorFlow 和 Keras 中从头开始实现多头注意力
照片来自Everaldo Coelho,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- Transformer 架构回顾
- Transformer 多头注意力
- 从头开始实现多头注意力
- 测试代码
先决条件
本教程假设您已熟悉以下内容:
Transformer 架构回顾
回想一下,Transformer 架构遵循编码器-解码器结构。左侧的编码器负责将输入序列映射到一系列连续表示;右侧的解码器接收编码器的输出以及前一时间步的解码器输出,以生成输出序列。
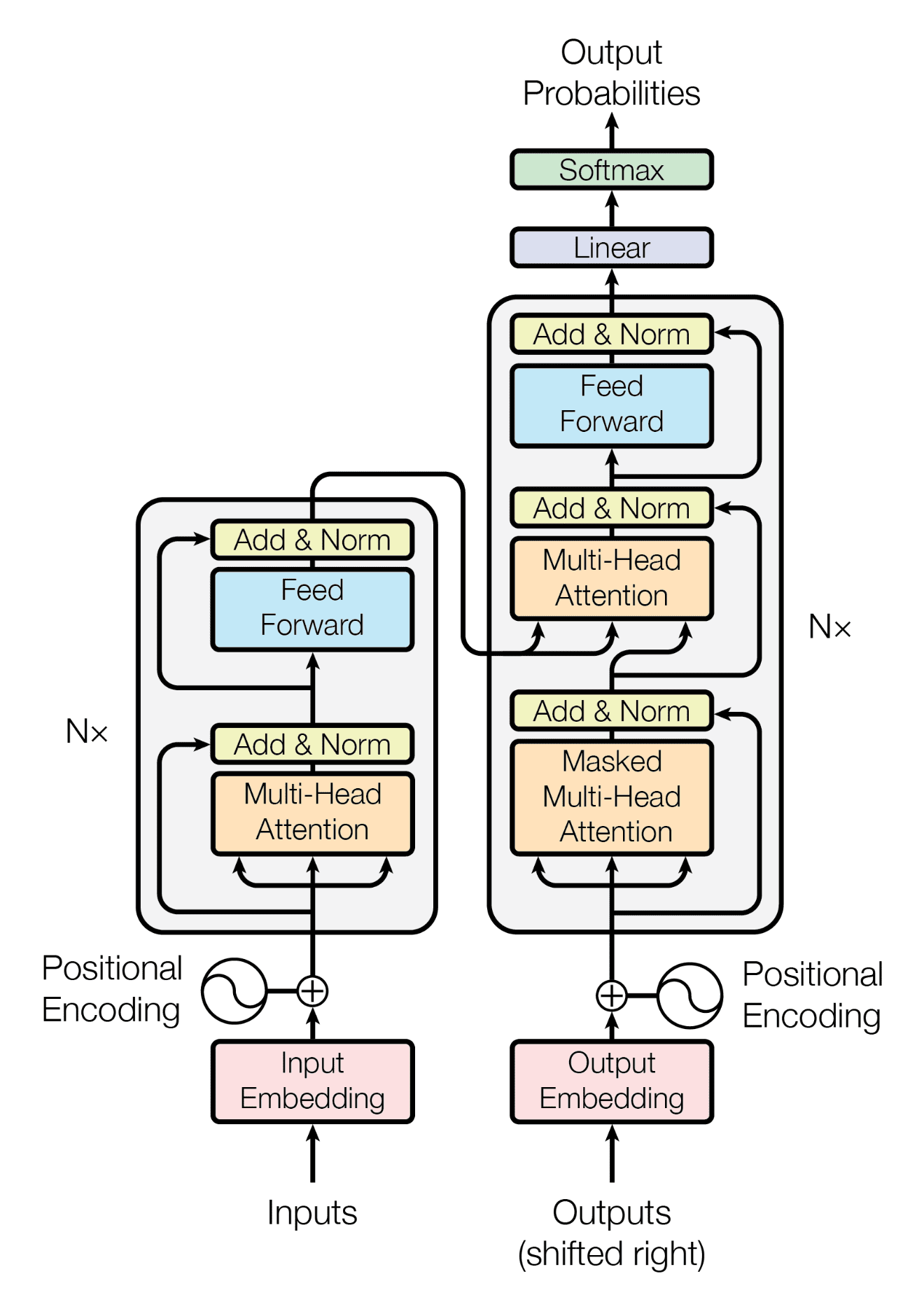
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
在生成输出序列时,Transformer 不依赖于循环和卷积。
您已经看到,Transformer 的解码器部分在其架构上与编码器有许多相似之处。编码器和解码器共享的核心机制之一是多头注意力机制。
Transformer 多头注意力
每个多头注意力块由四个连续的级别组成
- 第一级,三个线性(密集)层,每个层接收查询、键或值
- 第二级,一个缩放点积注意力函数。根据构成多头注意力块的头数,第一级和第二级执行的操作会重复 h 次并并行执行。
- 第三级,一个连接操作,将不同头的输出连接起来
- 第四级,一个最终的线性(密集)层,生成输出
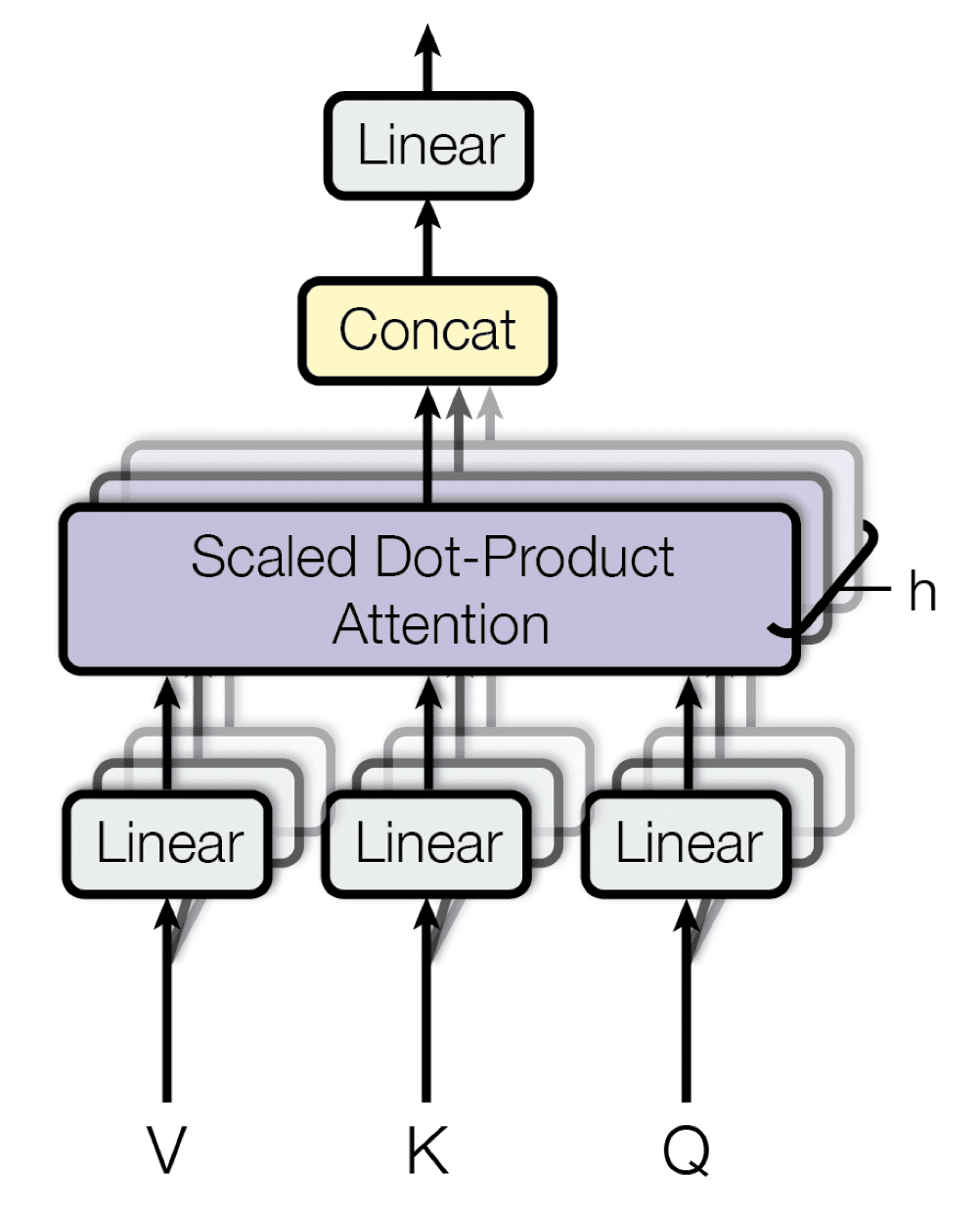
多头注意力
摘自“Attention Is All You Need”
回想一下,构成多头注意力实现的重要组成部分也将作为构建块。
- 查询、键和值: 这些是每个多头注意力块的输入。在编码器阶段,它们各自携带相同的输入序列,该序列已嵌入并由位置信息增强。同样,在解码器端,馈送到第一个注意力块的查询、键和值表示相同的目标序列,该序列也已嵌入并由位置信息增强。解码器的第二个注意力块接收编码器输出(作为键和值),以及第一个解码器注意力块的归一化输出(作为查询)。查询和键的维度表示为 $d_k$,而值的维度表示为 $d_v$。
- 投影矩阵: 当应用于查询、键和值时,这些投影矩阵会为每个生成不同的子空间表示。然后,每个注意力头处理这些查询、键和值的其中一个投影版本。在将每个单独头的输出连接在一起后,还会将一个附加的投影矩阵应用于多头注意力块的输出。投影矩阵在训练期间学习。
现在让我们看看如何在 TensorFlow 和 Keras 中从头开始实现多头注意力。
从头开始实现多头注意力
让我们开始创建 MultiHeadAttention 类,该类继承自 Keras 的 Layer 基类,并初始化几个您将使用的实例属性(属性描述可以在注释中找到)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class MultiHeadAttention(Layer): def __init__(self, h, d_k, d_v, d_model, **kwargs): super(MultiHeadAttention, self).__init__(**kwargs) self.attention = DotProductAttention() # 缩放点积注意力 self.heads = h # 要使用的注意力头数 self.d_k = d_k # 线性投影的查询和键的维度 self.d_v = d_v # 线性投影的值的维度 self.W_q = Dense(d_k) # 查询的已学习投影矩阵 self.W_k = Dense(d_k) # 键的已学习投影矩阵 self.W_v = Dense(d_v) # 值的已学习投影矩阵 self.W_o = Dense(d_model) # 多头输出的已学习投影矩阵 ... |
这里请注意,已创建 DotProductAttention 类的实例,并将其输出分配给变量 attention。 回想一下,您是这样实现 DotProductAttention 类的:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from tensorflow import matmul, math, cast, float32 from tensorflow.keras.layers import Layer from keras.backend import softmax # 实现缩放点积注意力 class DotProductAttention(Layer): def __init__(self, **kwargs): super(DotProductAttention, self).__init__(**kwargs) def call(self, queries, keys, values, d_k, mask=None): // 对查询和转置后的键进行评分,然后进行缩放 scores = matmul(queries, keys, transpose_b=True) / math.sqrt(cast(d_k, float32)) // 将掩码应用于注意力分数 if mask is not None: scores += -1e9 * mask // 通过 softmax 操作计算权重 weights = softmax(scores) // 通过值向量的加权和计算注意力 return matmul(weights, values) |
接下来,您将以一种允许并行计算注意力头的方式重塑线性投影的查询、键和值。
查询、键和值将作为输入馈送到多头注意力块,形状为(批处理大小,序列长度,模型维度),其中批处理大小是训练过程的超参数,序列长度定义了输入/输出短语的最大长度,模型维度是模型所有子层产生的输出的维度。然后,它们通过各自的密集层进行线性投影,形状为(批处理大小,序列长度,查询/键/值维度)。
通过首先将线性投影的查询、键和值重塑为(批处理大小,序列长度,头数,深度),然后转置第二个和第三个维度,将它们重新排列为(批处理大小,头数,序列长度,深度)。为此,您将创建类方法 reshape_tensor,如下所示:
|
1 2 3 4 5 6 7 8 9 10 |
def reshape_tensor(self, x, heads, flag): if flag: // 重塑和转置后的张量形状:(batch_size, heads, seq_length, -1) x = reshape(x, shape=(shape(x)[0], shape(x)[1], heads, -1)) x = transpose(x, perm=(0, 2, 1, 3)) else: // 反转重塑和转置操作:(batch_size, seq_length, d_model) x = transpose(x, perm=(0, 2, 1, 3)) x = reshape(x, shape=(shape(x)[0], shape(x)[1], -1)) return x |
reshape_tensor 方法接收线性投影的查询、键或值作为输入(同时将标志设置为 True)以按前面所述进行重新排列。一旦生成了多头注意力输出,也会将其馈送到同一个函数(这次将标志设置为 False)以执行反向操作,有效地将所有头的输出连接在一起。
因此,下一步是使用 reshape_tensor 方法将线性投影的查询、键和值馈入以进行重新排列,然后将它们馈送到缩放点积注意力函数。为了做到这一点,让我们创建另一个类方法 call,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def call(self, queries, keys, values, mask=None): // 重新排列查询以能够并行计算所有头 q_reshaped = self.reshape_tensor(self.W_q(queries), self.heads, True) // 结果张量形状:(batch_size, heads, input_seq_length, -1) // 重新排列键以能够并行计算所有头 k_reshaped = self.reshape_tensor(self.W_k(keys), self.heads, True) // 结果张量形状:(batch_size, heads, input_seq_length, -1) // 重新排列值以能够并行计算所有头 v_reshaped = self.reshape_tensor(self.W_v(values), self.heads, True) // 结果张量形状:(batch_size, heads, input_seq_length, -1) // 使用重塑后的查询、键和值计算多头注意力输出 o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k, mask) // 结果张量形状:(batch_size, heads, input_seq_length, -1) ... |
请注意,reshape_tensor 方法除了查询、键和值之外,还可以接收掩码(其值默认为 None)作为输入。
回想一下,Transformer 模型引入了一个前瞻掩码,以防止解码器关注后续词语,从而使对某个词语的预测只能依赖于之前词语的已知输出。此外,由于词嵌入被零填充到特定的序列长度,因此还需要引入一个填充掩码,以防止零值与输入一起被处理。这些前瞻掩码和填充掩码可以通过 mask 参数传递给缩放点积注意力。
一旦您从所有注意力头生成了多头注意力输出,最后几个步骤是将所有输出连接回形状为(批处理大小,序列长度,值维度)的张量,并将结果通过一个最终的密集层。为此,您将在 call 方法中添加以下两行代码。
|
1 2 3 4 5 6 7 8 |
... # 将输出重新排列回连接形式 output = self.reshape_tensor(o_reshaped, self.heads, False) # 结果张量形状:(batch_size, input_seq_length, d_v) # 将最终的线性投影应用于输出,以生成多头注意力 # 结果张量形状:(batch_size, input_seq_length, d_model) return self.W_o(output) |
将所有内容放在一起,您将获得以下多头注意力的实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
from tensorflow import math, matmul, reshape, shape, transpose, cast, float32 from tensorflow.keras.layers import Dense, Layer from keras.backend import softmax # 实现缩放点积注意力 class DotProductAttention(Layer): def __init__(self, **kwargs): super(DotProductAttention, self).__init__(**kwargs) def call(self, queries, keys, values, d_k, mask=None): // 对查询和转置后的键进行评分,然后进行缩放 scores = matmul(queries, keys, transpose_b=True) / math.sqrt(cast(d_k, float32)) // 将掩码应用于注意力分数 if mask is not None: scores += -1e9 * mask // 通过 softmax 操作计算权重 weights = softmax(scores) // 通过值向量的加权和计算注意力 return matmul(weights, values) # 实现多头注意力 class MultiHeadAttention(Layer): def __init__(self, h, d_k, d_v, d_model, **kwargs): super(MultiHeadAttention, self).__init__(**kwargs) self.attention = DotProductAttention() # 缩放点积注意力 self.heads = h # 要使用的注意力头数 self.d_k = d_k # 线性投影的查询和键的维度 self.d_v = d_v # 线性投影的值的维度 self.d_model = d_model # 模型的维度 self.W_q = Dense(d_k) # 查询的已学习投影矩阵 self.W_k = Dense(d_k) # 键的已学习投影矩阵 self.W_v = Dense(d_v) # 值的已学习投影矩阵 self.W_o = Dense(d_model) # 多头输出的已学习投影矩阵 def reshape_tensor(self, x, heads, flag): if flag: // 重塑和转置后的张量形状:(batch_size, heads, seq_length, -1) x = reshape(x, shape=(shape(x)[0], shape(x)[1], heads, -1)) x = transpose(x, perm=(0, 2, 1, 3)) else: // 反转重塑和转置操作:(batch_size, seq_length, d_k) x = transpose(x, perm=(0, 2, 1, 3)) x = reshape(x, shape=(shape(x)[0], shape(x)[1], self.d_k)) return x def call(self, queries, keys, values, mask=None): // 重新排列查询以能够并行计算所有头 q_reshaped = self.reshape_tensor(self.W_q(queries), self.heads, True) // 结果张量形状:(batch_size, heads, input_seq_length, -1) // 重新排列键以能够并行计算所有头 k_reshaped = self.reshape_tensor(self.W_k(keys), self.heads, True) // 结果张量形状:(batch_size, heads, input_seq_length, -1) // 重新排列值以能够并行计算所有头 v_reshaped = self.reshape_tensor(self.W_v(values), self.heads, True) // 结果张量形状:(batch_size, heads, input_seq_length, -1) // 使用重塑后的查询、键和值计算多头注意力输出 o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k, mask) // 结果张量形状:(batch_size, heads, input_seq_length, -1) // 将输出重新排列回连接形式 output = self.reshape_tensor(o_reshaped, self.heads, False) // 结果张量形状:(batch_size, input_seq_length, d_v) // 将最终的线性投影应用于输出,以生成多头注意力 // 结果张量形状:(batch_size, input_seq_length, d_model) return self.W_o(output) |
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
测试代码
您将使用 Vaswani 等人(2017)的论文 Attention Is All You Need 中指定的参数值。
|
1 2 3 4 5 6 |
h = 8 # 自注意力头的数量 d_k = 64 # 线性投影的查询和键的维度 d_v = 64 # 线性投影的值的维度 d_model = 512 # 模型子层输出的维度 batch_size = 64 # 训练过程中的批次大小 ... |
至于序列长度以及查询、键和值,您将暂时使用模拟数据,直到您在另一个教程中进入训练完整 Transformer 模型的阶段,届时您将使用实际句子。
|
1 2 3 4 5 6 7 |
... input_seq_length = 5 # 输入序列的最大长度 queries = random.random((batch_size, input_seq_length, d_k)) keys = random.random((batch_size, input_seq_length, d_k)) values = random.random((batch_size, input_seq_length, d_v)) ... |
在完整的 Transformer 模型中,序列长度以及查询、键和值的参数将通过词语标记化和嵌入过程获得。我们将在另一个教程中介绍这一点。
回到测试过程,下一步是创建一个 `MultiHeadAttention` 类的新实例,将其输出分配给 `multihead_attention` 变量。
|
1 2 3 |
... multihead_attention = MultiHeadAttention(h, d_k, d_v, d_model) ... |
由于 `MultiHeadAttention` 类继承自 `Layer` 基类,前者的方法 `call()` 将由后者的魔术方法 `__call()` 自动调用。最后一步是传入输入参数并打印结果。
|
1 2 |
... print(multihead_attention(queries, keys, values)) |
将所有内容结合起来,生成以下代码清单
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from numpy import random input_seq_length = 5 # 输入序列的最大长度 h = 8 # 自注意力头的数量 d_k = 64 # 线性投影的查询和键的维度 d_v = 64 # 线性投影的值的维度 d_model = 512 # 模型子层输出的维度 batch_size = 64 # 训练过程中的批次大小 queries = random.random((batch_size, input_seq_length, d_k)) keys = random.random((batch_size, input_seq_length, d_k)) values = random.random((batch_size, input_seq_length, d_v)) multihead_attention = MultiHeadAttention(h, d_k, d_v, d_model) print(multihead_attention(queries, keys, values)) |
运行此代码将产生一个形状为(批次大小,序列长度,模型维度)的输出。请注意,由于查询、键和值的随机初始化以及密集层的参数值,您可能会看到不同的输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
tf.Tensor( [[[-0.02185373 0.32784638 0.15958631 ... -0.0353895 0.6645204 -0.2588266 ] [-0.02272229 0.32292002 0.16208754 ... -0.03644213 0.66478664 -0.26139447] [-0.01876744 0.32900316 0.16190802 ... -0.03548665 0.6645842 -0.26155376] [-0.02193783 0.32687354 0.15801215 ... -0.03232524 0.6642926 -0.25795174] [-0.02224652 0.32437912 0.1596448 ... -0.0340827 0.6617497 -0.26065096]] ... [[ 0.05414441 0.27019292 0.1845745 ... 0.0809482 0.63738805 -0.34231138] [ 0.05546578 0.27191412 0.18483458 ... 0.08379208 0.6366671 -0.34372014] [ 0.05190979 0.27185103 0.18378328 ... 0.08341806 0.63851804 -0.3422392 ] [ 0.05437043 0.27318984 0.18792395 ... 0.08043509 0.6391771 -0.34357914] [ 0.05406848 0.27073097 0.18579456 ... 0.08388947 0.6376929 -0.34230167]]], shape=(64, 5, 512), dtype=float32) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019
- 用于自然语言处理的 Transformer, 2021
论文
- 注意力就是你所需要的一切, 2017
总结
在本教程中,您学习了如何从头开始在 TensorFlow 和 Keras 中实现多头注意力。
具体来说,你学到了:
- 构成多头注意力机制的层
- 如何从头开始实现多头注意力机制
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...



 From Scratch in Keras")


你好。解释得很棒!我有一个小疑问。为什么您需要重塑输入然后计算转置,而不是直接将其重塑为 (batch size, heads, sequence lenght, -1)?谢谢。
你好 Moises……你绝对可以按照你的建议进行。让我们知道你的发现。
很棒的教程。感谢您将所有这些内容整理在一起!
Brett,非常欢迎!
如果我们重塑数据,这是否意味着我们仍然执行常规的点注意力(1 个头),但现在将其重塑为好像有 8 个头?我在打印重塑后的查询、键、值矩阵的形状时看不到额外的维度。
你好 Diego……以下系列可能对您有帮助。
https://towardsdatascience.com/transformers-explained-visually-part-3-multi-head-attention-deep-dive-1c1ff1024853
我认为
self.W_q (d_k)
self.W_k (d_k)
self.W_v (d_v)
不应该有一个静态的 d_k 值,而应该
self.head_dim = self.d_model // self.heads
self.W_q (self.head_dim)
self.W_k (self.head_dim)
self.W_v (self.head_dim)
否则,您的 q、k、v 矩阵与嵌入空间和头数无关,而仅仅与 d_k 维度的预设值相关。
我同意。这一点需要明确指出。
在最后一个代码块中
queries = random.random((batch_size, input_seq_length, d_k))
它应该是这样的
queries = random.random((batch_size, input_seq_length, d_model))?
在您撰写的文章中
“查询、键和值将被输入到多头注意力块中,其形状为(批次大小、序列长度、模型维度),其中批次大小是训练过程的超参数,序列长度定义了输入/输出短语的最大长度,模型维度是模型所有子层产生的输出的维度。然后,它们将通过相应的密集层,被线性投影到(批次大小、序列长度、查询/键/值维度)的形状。”
特别是,您说的是“模型维度”,而不是 d_k。
换句话说,我认为 W_q 是一个维度为 512 x 64 的矩阵。其中输入维度 = d_model = 512,输出维度 = d_k = 64。
我错了吗?这让我感到非常困惑……如果有人能为我澄清,我将不胜感激。
你好 Cybernetic1,感谢您的关注。
我所说的“查询、键和值将被输入到多头注意力块中,其形状为(批次大小、序列长度、模型维度)……”,是指多头注意力块的输出形状为(批次大小,序列长度,模型维度),而不是查询、键或值。否则,可以从 Vaswani 的论文中确认,查询和键的维度是 *d_k*,而值的维度是 *d_v*,其中 Vaswani 等人将 *d_k* 和 *d_v* 设置为一个与 *d_model* 不同的值。
我同意 Cybernetic1 的观点。
d_k 是线性投影的查询和键的维度。但在代码中 'queries = random.random((batch_size, input_seq_length, d_k))',queries 是 multihead_attention 的输入,尚未进行投影。它们将在 MultiHeadAttention 的 call 函数中进行投影,通过此代码完成 'q_reshaped = self.reshape_tensor(self.W_q(queries), self.heads, True)'。因此,第一行代码的最后一个维度应该是 d_model 或 d_k * h。
代码本身有误。multihead 类应该是
class MultiHeadAttention(Layer)
def __init__(self, h, d_model, **kwargs)
super(MultiHeadAttention, self).__init__(**kwargs)
self.attention = DotProductAttention() # 缩放点积注意力
self.heads = h # 要使用的注意力头的数量
assert d_model % h = 0
d_k= d_model//h # d_k 应根据 d_model 和 h 计算
self.d_k = d_k # 线性投影的查询和键的维度
self.d_v = d_k # 线性投影的值的维度
self.d_model = d_model # 模型的维度
# 投影矩阵的单位应该是 d_model 而不是 d_k/d_v
self.W_q = Dense(d_model) # 查询的学习投影矩阵
self.W_k = Dense(d_model) # 键的学习投影矩阵
self.W_v = Dense(d_model) # 值的学习投影矩阵
self.W_o = Dense(d_model) # 多头输出的学习投影矩阵
其余代码似乎没有问题。
这是正确的答案
同意 Cybernetic1 的观点,但我非常欣赏作者将这些内容整理在一起的努力!
查询和键必须具有相同的维度,才能成功计算 DotProductAttention 中的 MatMul。
查询:(batch, time, d_q)
键:(batch, time, d_k)
要计算 DotProduct(Queries, Keys) = Queries @ Keys.T,则 (d_q 必须等于 d_k)
谢谢你的反馈 Ivan!
你好,
在 PDF 版本中。
def reshape_tensor…..
.....
—- False 分支
x = reshape(x, shape=(shape(x)[0], shape(x)[1], self.d_k))
.....
我认为 d_k 是不正确的,应该是 d_v。因为反向重塑是对值进行的,而不是对键/查询进行的。
书籍版本如果 d_k 不等于 d_v 就会抛出异常。
谢谢你的反馈 Ivan!
在缩放点积注意力上过度正则化。
在论文“Attention is all you need”的第 3.2.1 节中,有一个脚注解释了正则化项 (dk**-1/2) 的影响。
—
为了说明点积为何会变大,假设 q 和 k 的分量是均值为 0、方差为 1 的独立随机变量。那么它们的点积 q · k 的均值为 0,方差为 dk。
—
我们可以观察到这种行为。
q = tf.random.normal([2,3,16,8])
k = tf.random.normal([2,3,16,8])
qk = q@tf.transpose(k, perm=[0,1,3,2])
tf.math.reduce_variance(qk)
# ——— 几乎等于最后一个维度
qk2 = q@tf.transpose(k, perm=[0,1,3,2])/tf.math.sqrt(8.)
# ——— 添加正则化项
tf.math.reduce_variance(qk2)
# ——— 点积方差接近 q 和 k 的方差
回到书中。
在代码 MultiHeadAttention.call() 中
…
# 使用重塑后的查询、键和值计算多头注意力输出
o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k, mask)
# 结果张量形状:(batch_size, heads, input_seq_length, -1)
…
self.d_k 可能有两个值
1 种选择)重塑前:d_k = 头数 * 查询大小
2 种选择)重塑后:d_k = 查询大小
在书中使用了“1 种选择”。这会导致点积过度正则化,并减慢训练速度,因为梯度在所有 token 之间是相等的。
要实现“2 种选择”,请在 MultiHeadAttention.call 中替换
o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k, mask)
# 为下一行
o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k / self.heads, mask)
要研究得分-值,您可以在 score 计算后立即在 DotProductAttention.call 中设置断点,并将每个头的键、查询和分数的方差添加到监视窗口。
math.reduce_variance(keys, axis=[0,2,3])
math.reduce_variance(queries, axis=[0,2,3])
math.reduce_variance(scores, axis=[0,2,3])
使用当前代码(1 种选择)的观察结果
键和查询的方差彼此接近,但分数方差要小一个数量级。分数方差约为 0.1。
使用实现的“2 种选择”时,所有三个方差都在同一个数量级。
过度正则化会影响 softmax 分布,每个项几乎彼此相等,梯度流将平均分配给所有项。
谢谢你的反馈 Ivan!如果您有任何关于我们内容的具体问题,请告诉我们。
我认为这是正确的代码。
o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k / self.heads, mask)
你好!感谢您对 Transformer 模型进行详细且清晰的介绍。
我只是想指出一个令人困惑的笔误。在“从头开始实现多头注意力”的子标题中,您写道“请注意,reshape_tensor 方法也可以接收一个掩码”,但我认为您指的是 attention 方法,而不是。
祝好,
弗洛里安
Florian,非常欢迎!我们感谢您的支持、反馈和建议!
Florian 的更正很重要。我在这个网站上看过很多次,您指出了一个重要的笔误或进行了重要的更正,而您只是感谢他们。另外,您没有给出详细的回复,而是链接到通用的(有时很有用)页面,并“鼓励”评论者“尝试一下”并“告诉我们您的发现”。
我购买了电子书,并对此表示感谢。但我将此网站上的评论用作急需的“勘误”部分。您没有积极地与读者互动或在指出错误时进行更正,这有点令人失望。
如何将其与 Keras Bi-LSTM 层之后一起使用?
你好 Gabriel……以下资源可能对您有帮助。
https://keras.org.cn/api/layers/attention_layers/multi_head_attention/
为什么我要将查询、键和值作为输入传递给多头注意力?多头注意力的输入应该是训练数据,如果维度是 [batch_dim, max_token_length, embedding_dim] 的话,对吗?
你好 Kishan……以下资源可能对您有帮助。
https://paperswithcode.com/method/multi-head-attention