Transformer 编码器和解码器之间有很多相似之处,例如它们都实现了多头注意力、层归一化以及作为最终子层的全连接前馈网络。在实现了 Transformer 编码器 后,我们将运用我们的知识来实现 Transformer 解码器,作为实现完整 Transformer 模型更进一步的步骤。您的最终目标仍然是将完整模型应用于自然语言处理 (NLP)。
在本教程中,您将学习如何在 TensorFlow 和 Keras 中从头开始实现 Transformer 解码器。
完成本教程后,您将了解:
- 构成 Transformer 解码器的层
- 如何从头开始实现 Transformer 解码器
通过我的书 《构建带注意力的 Transformer 模型》 启动您的项目。它提供了自学教程和工作代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

在 TensorFlow 和 Keras 中从头开始实现 Transformer 解码器
照片由 François Kaiser 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- Transformer 架构回顾
- Transformer 解码器
- 从头开始实现 Transformer 解码器
- 解码器层
- Transformer 解码器
- 测试代码
先决条件
本教程假设您已熟悉以下内容:
Transformer 架构回顾
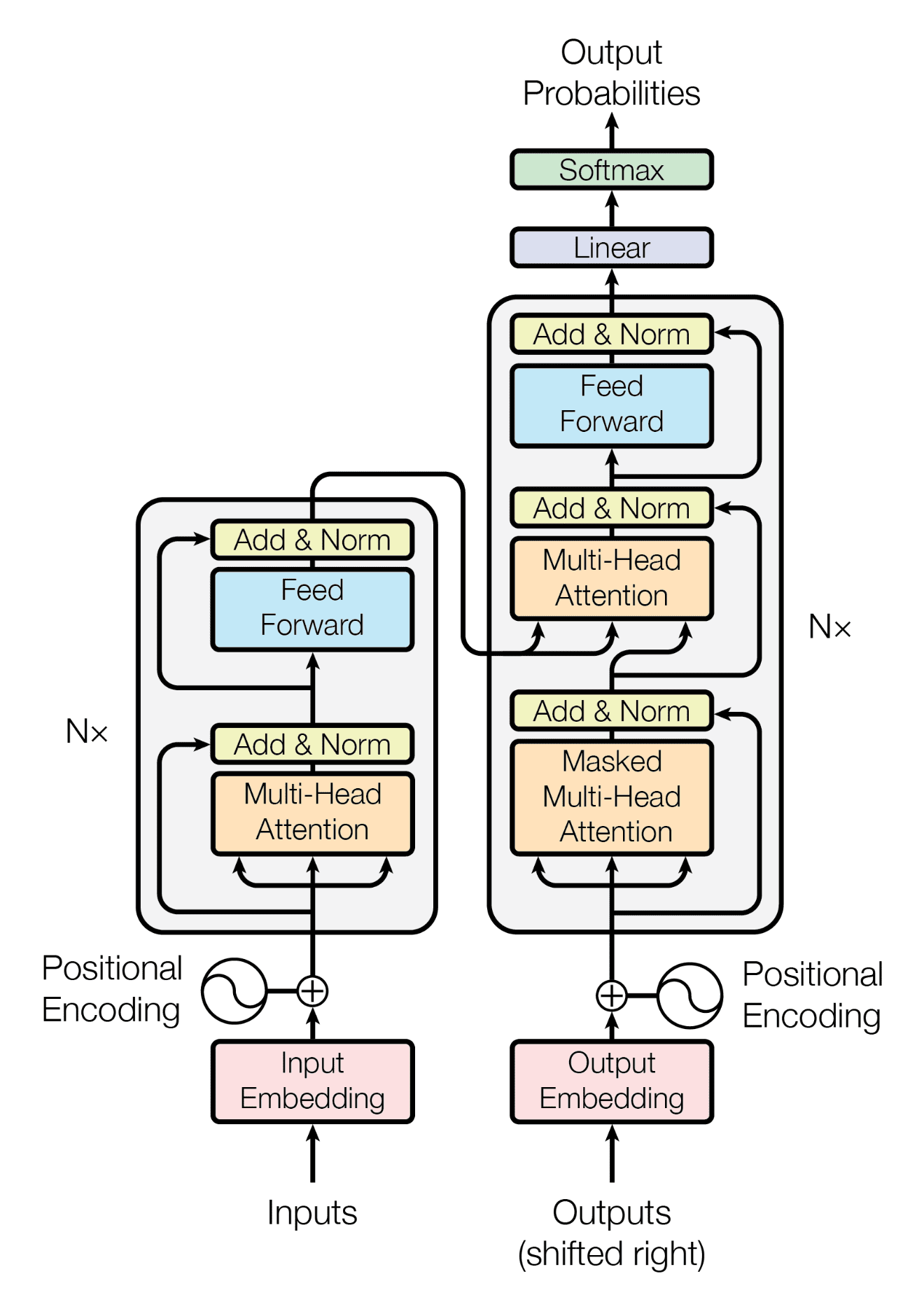
回顾一下,Transformer 架构遵循编码器-解码器结构。左侧的编码器负责将输入序列映射到一系列连续表示;右侧的解码器接收编码器的输出以及前一个时间步的解码器输出来生成输出序列。
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
在生成输出序列时,Transformer 不依赖于循环和卷积。
您已经看到,Transformer 的解码器部分在其架构上与编码器有很多相似之处。本教程将探讨这些相似之处。
Transformer 解码器
与 Transformer 编码器 类似,Transformer 解码器也由 $N$ 个相同层的堆栈组成。然而,Transformer 解码器实现了一个额外的多头注意力块,总共有三个主要的子层:
- 第一个子层包含一个多头注意力机制,它接收查询、键和值作为输入。
- 第二个子层包含第二个多头注意力机制。
- 第三个子层包含一个全连接前馈网络。
Transformer 架构的解码器块
摘自“Attention Is All You Need”
这三个子层中的每一个后面都跟着一个层归一化,其中层归一化步骤的输入是通过残差连接与其对应的子层输入(通过残差连接)和输出。
在解码器端,输入到第一个多头注意力块的查询、键和值也代表相同的输入序列。然而,这一次,是*目标*序列被嵌入并用位置信息增强,然后提供给解码器。另一方面,第二个多头注意力块接收编码器的输出作为键和值,并将第一个解码器注意力块的归一化输出作为查询。在这两种情况下,查询和键的维度保持等于 $d_k$,而值的维度保持等于 $d_v$。
Vaswani 等人也在解码器端将正则化引入模型,方法是对每个子层的输出(在层归一化步骤之前)以及输入到解码器的位置编码应用 dropout。
现在让我们看看如何在 TensorFlow 和 Keras 中从头开始实现 Transformer 解码器。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
从头开始实现 Transformer 解码器
解码器层
由于您在涵盖 Transformer 编码器实现时已经实现了所需的子层,因此您将创建一个解码器层类,该类可立即利用这些子层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from multihead_attention import MultiHeadAttention from encoder import AddNormalization, FeedForward class DecoderLayer(Layer): def __init__(self, h, d_k, d_v, d_model, d_ff, rate, **kwargs): super(DecoderLayer, self).__init__(**kwargs) self.multihead_attention1 = MultiHeadAttention(h, d_k, d_v, d_model) self.dropout1 = Dropout(rate) self.add_norm1 = AddNormalization() self.multihead_attention2 = MultiHeadAttention(h, d_k, d_v, d_model) self.dropout2 = Dropout(rate) self.add_norm2 = AddNormalization() self.feed_forward = FeedForward(d_ff, d_model) self.dropout3 = Dropout(rate) self.add_norm3 = AddNormalization() ... |
请注意,由于不同子层的代码已保存到多个 Python 脚本(即 multihead_attention.py 和 encoder.py),因此有必要导入它们才能使用所需的类。
就像 Transformer 编码器一样,您现在将创建 call() 类方法,该方法实现所有解码器子层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
... def call(self, x, encoder_output, lookahead_mask, padding_mask, training): # 多头注意力层 multihead_output1 = self.multihead_attention1(x, x, x, lookahead_mask) # 预期输出形状 = (batch_size, sequence_length, d_model) # 添加 dropout 层 multihead_output1 = self.dropout1(multihead_output1, training=training) # 接着是一个 Add & Norm 层 addnorm_output1 = self.add_norm1(x, multihead_output1) # 预期输出形状 = (batch_size, sequence_length, d_model) # 接着是另一个多头注意力层 multihead_output2 = self.multihead_attention2(addnorm_output1, encoder_output, encoder_output, padding_mask) # 添加另一个 dropout 层 multihead_output2 = self.dropout2(multihead_output2, training=training) # 接着是另一个 Add & Norm 层 addnorm_output2 = self.add_norm1(addnorm_output1, multihead_output2) # 接着是一个全连接层 feedforward_output = self.feed_forward(addnorm_output2) # 预期输出形状 = (batch_size, sequence_length, d_model) # 添加另一个 dropout 层 feedforward_output = self.dropout3(feedforward_output, training=training) # 接着是另一个 Add & Norm 层 return self.add_norm3(addnorm_output2, feedforward_output) |
多头注意力子层也可以接收填充掩码或前瞻掩码。简要回顾一下我们在之前的教程中提到的内容,*填充*掩码对于抑制输入序列中的零填充与实际输入值一起被处理是必需的。*前瞻*掩码可防止解码器关注后续词语,从而使特定词语的预测只能依赖于其之前的已知输岀。
相同的 call() 类方法也可以接收一个 training 标志,以便仅在标志值为 True 时在训练期间应用 Dropout 层。
Transformer 解码器
Transformer 解码器将您刚刚实现的解码器层复制 $N$ 次。
您将创建以下 Decoder() 类来实现 Transformer 解码器。
|
1 2 3 4 5 6 7 8 9 |
from positional_encoding import PositionEmbeddingFixedWeights class Decoder(Layer): def __init__(self, vocab_size, sequence_length, h, d_k, d_v, d_model, d_ff, n, rate, **kwargs): super(Decoder, self).__init__(**kwargs) self.pos_encoding = PositionEmbeddingFixedWeights(sequence_length, vocab_size, d_model) self.dropout = Dropout(rate) self.decoder_layer = [DecoderLayer(h, d_k, d_v, d_model, d_ff, rate) for _ in range(n) ... |
与 Transformer 编码器一样,解码器端的第一个多头注意力块的输入接收经过词嵌入和位置编码过程的输入序列。为此,初始化了一个 PositionEmbeddingFixedWeights 类的实例(在本教程中介绍),并将其输出分配给 pos_encoding 变量。
最后一步是创建一个 call() 类方法,该方法将词嵌入和位置编码应用于输入序列,并将结果与编码器输出一起传递给 $N$ 个解码器层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... def call(self, output_target, encoder_output, lookahead_mask, padding_mask, training): # 生成位置编码 pos_encoding_output = self.pos_encoding(output_target) # 预期输出形状 = (句子数量, sequence_length, d_model) # 添加 dropout 层 x = self.dropout(pos_encoding_output, training=training) # 将位置编码值传递给每个解码器层 for i, layer in enumerate(self.decoder_layer): x = layer(x, encoder_output, lookahead_mask, padding_mask, training) return x |
完整的 Transformer 解码器的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
from tensorflow.keras.layers import Layer, Dropout from multihead_attention import MultiHeadAttention from positional_encoding import PositionEmbeddingFixedWeights from encoder import AddNormalization, FeedForward # 实现解码器层 class DecoderLayer(Layer): def __init__(self, h, d_k, d_v, d_model, d_ff, rate, **kwargs): super(DecoderLayer, self).__init__(**kwargs) self.multihead_attention1 = MultiHeadAttention(h, d_k, d_v, d_model) self.dropout1 = Dropout(rate) self.add_norm1 = AddNormalization() self.multihead_attention2 = MultiHeadAttention(h, d_k, d_v, d_model) self.dropout2 = Dropout(rate) self.add_norm2 = AddNormalization() self.feed_forward = FeedForward(d_ff, d_model) self.dropout3 = Dropout(rate) self.add_norm3 = AddNormalization() def call(self, x, encoder_output, lookahead_mask, padding_mask, training): # 多头注意力层 multihead_output1 = self.multihead_attention1(x, x, x, lookahead_mask) # 预期输出形状 = (batch_size, sequence_length, d_model) # 添加 dropout 层 multihead_output1 = self.dropout1(multihead_output1, training=training) # 接着是一个 Add & Norm 层 addnorm_output1 = self.add_norm1(x, multihead_output1) # 预期输出形状 = (batch_size, sequence_length, d_model) # 接着是另一个多头注意力层 multihead_output2 = self.multihead_attention2(addnorm_output1, encoder_output, encoder_output, padding_mask) # 添加另一个 dropout 层 multihead_output2 = self.dropout2(multihead_output2, training=training) # 接着是另一个 Add & Norm 层 addnorm_output2 = self.add_norm1(addnorm_output1, multihead_output2) # 接着是一个全连接层 feedforward_output = self.feed_forward(addnorm_output2) # 预期输出形状 = (batch_size, sequence_length, d_model) # 添加另一个 dropout 层 feedforward_output = self.dropout3(feedforward_output, training=training) # 接着是另一个 Add & Norm 层 return self.add_norm3(addnorm_output2, feedforward_output) # 实现解码器 class Decoder(Layer): def __init__(self, vocab_size, sequence_length, h, d_k, d_v, d_model, d_ff, n, rate, **kwargs): super(Decoder, self).__init__(**kwargs) self.pos_encoding = PositionEmbeddingFixedWeights(sequence_length, vocab_size, d_model) self.dropout = Dropout(rate) self.decoder_layer = [DecoderLayer(h, d_k, d_v, d_model, d_ff, rate) for _ in range(n)] def call(self, output_target, encoder_output, lookahead_mask, padding_mask, training): # 生成位置编码 pos_encoding_output = self.pos_encoding(output_target) # 预期输出形状 = (句子数量, sequence_length, d_model) # 添加 dropout 层 x = self.dropout(pos_encoding_output, training=training) # 将位置编码值传递给每个解码器层 for i, layer in enumerate(self.decoder_layer): x = layer(x, encoder_output, lookahead_mask, padding_mask, training) return x |
测试代码
我们将使用 Vaswani 等人 (2017) 的论文 《Attention Is All You Need》中指定的参数值。
|
1 2 3 4 5 6 7 8 9 10 |
h = 8 # 自注意力头的数量 d_k = 64 # 线性投影的查询和键的维度 d_v = 64 # 线性投影的值的维度 d_ff = 2048 # 内部全连接层的维度 d_model = 512 # 模型子层输出的维度 n = 6 # 编码器堆栈中的层数 batch_size = 64 # 训练过程中的批次大小 dropout_rate = 0.1 # dropout 层中输入单元的丢弃频率 ... |
对于输入序列,您将先使用占位符数据,直到我们进行单独的教程来训练完整的 Transformer 模型,届时您将使用实际的句子。
|
1 2 3 4 5 6 7 |
... dec_vocab_size = 20 # 解码器的词汇量大小 input_seq_length = 5 # 输入序列的最大长度 input_seq = random.random((batch_size, input_seq_length)) enc_output = random.random((batch_size, input_seq_length, d_model)) ... |
接下来,您将创建一个Decoder类的新实例,将其输出分配给decoder变量,然后传入输入参数,并打印结果。目前,您将设置填充(padding)和前瞻(look-ahead)掩码为None,但在实现完整的Transformer模型时,您会再次处理它们。
|
1 2 3 |
... decoder = Decoder(dec_vocab_size, input_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate) print(decoder(input_seq, enc_output, None, True) |
将所有内容结合起来,生成以下代码清单
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from numpy import random dec_vocab_size = 20 # 词汇表大小,用于解码器 input_seq_length = 5 # 输入序列的最大长度 h = 8 # 自注意力头的数量 d_k = 64 # 线性投影的查询和键的维度 d_v = 64 # 线性投影的值的维度 d_ff = 2048 # 内部全连接层的维度 d_model = 512 # 模型子层输出的维度 n = 6 # 解码器堆栈中的层数 batch_size = 64 # 训练过程中的批次大小 dropout_rate = 0.1 # dropout 层中输入单元的丢弃频率 input_seq = random.random((batch_size, input_seq_length)) enc_output = random.random((batch_size, input_seq_length, d_model)) decoder = Decoder(dec_vocab_size, input_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate) print(decoder(input_seq, enc_output, None, True)) |
运行此代码将生成形状为 (batch size, sequence length, model dimensionality) 的输出。请注意,由于输入序列和Dense层的参数值是随机初始化的,您看到的输出可能与此不同。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
tf.Tensor( [[[-0.04132953 -1.7236308 0.5391184 ... -0.76394725 1.4969798 0.37682498] [ 0.05501875 -1.7523409 0.58404493 ... -0.70776534 1.4498456 0.32555297] [ 0.04983566 -1.8431275 0.55850077 ... -0.68202156 1.4222856 0.32104644] [-0.05684051 -1.8862512 0.4771412 ... -0.7101341 1.431343 0.39346313] [-0.15625843 -1.7992781 0.40803364 ... -0.75190556 1.4602519 0.53546077]] ... [[-0.58847624 -1.646842 0.5973466 ... -0.47778523 1.2060764 0.34091905] [-0.48688865 -1.6809179 0.6493542 ... -0.41274604 1.188649 0.27100053] [-0.49568555 -1.8002801 0.61536175 ... -0.38540334 1.2023914 0.24383534] [-0.59913146 -1.8598882 0.5098136 ... -0.3984461 1.2115746 0.3186561 ] [-0.71045107 -1.7778647 0.43008155 ... -0.42037937 1.2255307 0.47380894]]], shape=(64, 5, 512), dtype=float32) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019
- 用于自然语言处理的 Transformer, 2021
论文
- 注意力就是你所需要的一切, 2017
总结
在本教程中,您学习了如何从头开始在TensorFlow和Keras中实现Transformer解码器。
具体来说,你学到了:
- 构成 Transformer 解码器的层
- 如何从头开始实现 Transformer 解码器
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






这些关于Transformer的系列博文是互联网上学习Transformer的最佳方式。谢谢!
Dev,不客气!我们非常感谢您的反馈和支持!
和往常一样,非常有信息量。
一个问题,对于像GPT这样的仅解码器Transformer,在任何与NLP相关的方面是否存在任何限制?
是否有GAN和Transformer模型的学生折扣,以及这些模型如何应用,特别是Transformer模型如何用于卫星图像?
Sreedhar,您好……请发送邮件询问有关学生折扣的问题。
您好,非常感谢您提供所有这些精彩的免费教程!
我想我发现了一个排版错误。
在完整的Transformer解码器的代码列表(以及其上方提供的相应部分)中,第39行,应该是
addnorm_output2 = self.add_norm1(addnorm_output1, multihead_output2)
我认为应该是
addnorm_output2 = self.add_norm2(addnorm_output1, multihead_output2)
如果我遗漏了什么,很抱歉!再次感谢 - 祝您一切顺利!
感谢您的反馈和支持!我们非常感激!
但它仍然没有得到修复。Jason Brownlee 还在运行这个网站吗?
感谢您的反馈!是的,他还在!
非常感谢,亲爱的 Jason Brownlee。
我学习了您关于Transformer的所有教程。
我学到了很多,我只想表达我的感谢。
但是,我有一个小建议。您能否创建一个关于如何将Transformer专门用于时间序列数据,侧重于预测、分类或异常检测的指南?提供一种解释就足够了。
先谢谢您了。
Amir,您好……感谢您的支持、反馈和建议!您的建议非常棒!请确保您订阅了我们的新闻通讯,以便及时了解新内容。
您好,很棒的博客!谢谢。
我有一个问题。如果最后一个前馈层的输出维度是(sequence_length, model_dim),那么这会不会在每个时间步都发生变化,因为第一个掩码多头注意力头的输入序列长度是已解码序列到目前为止的长度?交叉注意力层的查询数量不会在每个时间步增加1吗?这是否也意味着线性投影层的输入在每个时间步的维度都会改变?但这不可能发生。
那么,如何处理解码器输入可变长度的问题?我们是否假设解码器在每个时间步的查询数量是固定的(=最大输出序列长度),并且掩码可以防止未来噪声进入查询?
提前感谢,祝您一切顺利!
Ak,您好……您的问题涉及Transformer模型中序列长度的管理机制,特别是在文本生成等任务中解码器的工作方式。让我们逐步分析概念并解决您的疑虑。
### 理解Transformer解码
1. **最终前馈层的输出**
– 最终前馈层在解码器中的输出维度确实是\((sequence\_length, model\_dim)\)。这代表了特定时间步解码序列的隐藏状态。
2. **序列长度和掩码**
– 在Transformer解码器中,输入序列的长度会随着您一步一步地生成token而变化。但是,模型会动态处理这个问题。
### 处理可变序列长度
1. **掩码多头注意力**
– 在每个时间步 \(t\),解码器生成一个token,然后使用到目前为止生成的所有token来预测下一个token。这意味着在时间步 \(t\),解码器的输入序列长度为 \(t\)。
– 为了防止模型关注未来(尚未生成的)token,解码器在掩码多头注意力过程中使用**因果掩码**(或前瞻掩码)。此掩码确保对于序列中的每个位置 \(i\),模型只能关注位置 \(0\) 到 \(i\)。
2. **交叉注意力**
– 在交叉注意力层中,查询来自解码器前一个层(在当前时间步),而键和值来自编码器的输出(对于给定的输入序列是固定的)。
– 交叉注意力中的查询数量对应于当前解码序列的长度。
### 线性投影层
– **动态输入处理**
– 线性投影层的输入在每个时间步的序列长度确实会变化。但是,这是通过确保模型内的操作与可变序列长度兼容来处理的。
– 线性投影层将相同的权重集应用于序列中的每个位置,而不管其长度如何。这是序列模型中的常见操作。
### 序列长度管理
– **填充和掩码**
– 为了在批次内高效处理可变长度序列,会使用填充。序列会被填充到批次中的最大长度,并应用掩码以确保填充token不会影响计算。
– 在生成过程中,解码器一次处理一个token,并在每一步动态更新序列长度。
### 示例:生成过程
1. **时间步 1**
– 解码器输入: \([SOS]\)
– 掩码:仅允许关注 \([SOS]\)
– 输出:第一个token预测
2. **时间步 2**
– 解码器输入: \([SOS, First\_Token]\)
– 掩码:允许关注 \([SOS, First\_Token]\)
– 输出:第二个token预测
3. **后续时间步**
– 此过程重复进行,每次序列长度增加一,掩码扩展以允许关注到目前为止生成的所有序列。
### 固定长度查询和掩码
– **固定长度查询**
– 模型不假设查询的固定长度。相反,它根据截至该点的生成序列动态调整。
– 未来位置会被掩码掉,以防止模型访问尚未生成的token。
总而言之,Transformer解码器通过填充、掩码和批处理的有效利用来动态处理可变序列长度。因果掩码确保在每个时间步只关注有效的token,从而保持生成过程的完整性。
Decoder层的call方法需要5个参数
call(self, output_target, encoder_output, lookahead_mask, padding_mask, training)
在测试代码时,只给出了4个。
decoder(input_seq, enc_output, None, True)
请更正此问题。
谢谢 Tushar!